风语咒作为扛起国漫崛起的又一国漫之作,爬取风语咒猫眼的电影评论数据,以便对其评论做之后的数据分析。
此次demo的流程图如下:

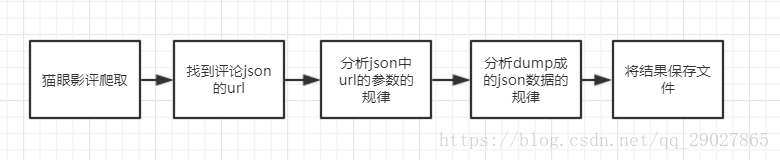
一.找到猫眼电影中风语咒影评得json数据:
l
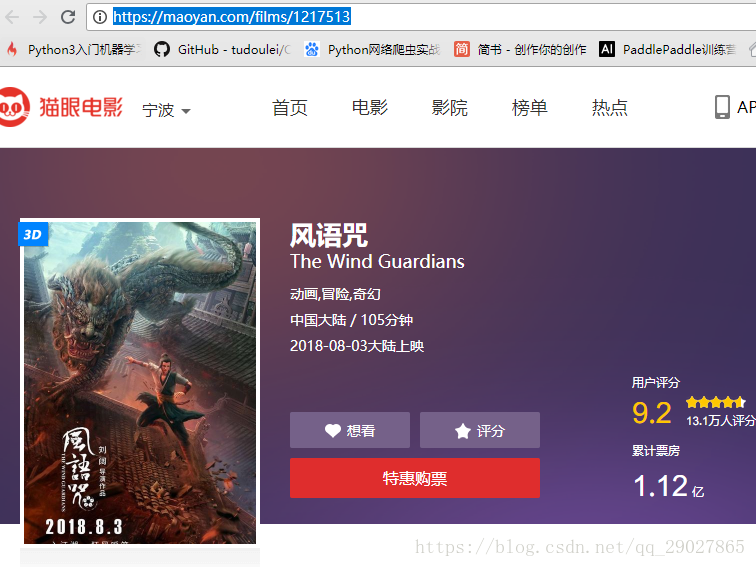
找出url后,往下滚动后,发现其并无评论页面得接口,这时通过f12启动手机版得调试模式,通过手机端得界面寻找此电影的评论的接口位置。刷新后如下:
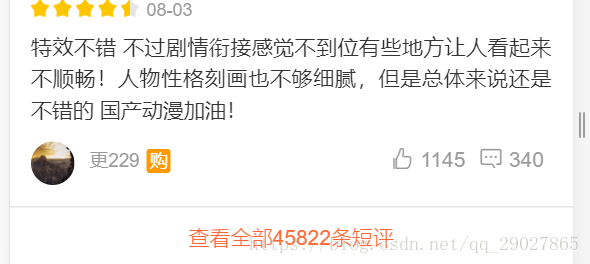
找到位置后,点开评论区,因为其中的评论采用的是js的方式加载,故当其向下拉动时,通过Network可以获得其中的json串,通过json串得出其中的评论json的url。

二.观察url,寻找其中的参数规律:
风语咒影评的某评论json的url如下:
http://m.maoyan.com/mmdb/comments/movie/1217513.json?_v_=yes&offset=45&startTime=2018-08-23%2015%3A24%3A16通过分析其中的参数并在浏览器上尝试,可以发现其中offset和starttime的参数均为可变的,经实践得知,starttime参数的含义是该条评论的时间,而offset指的是该页评论的index;那么我们可以通过格式化这两个参数的值,来对影评评论数据进行抓取。
因为我们暂时不知其中的offset到多少会为空,所以我们可以使用for循环对page进行操作,通过观察每页中的数据,发现每页评论的条数为15条,故在此每次遍历15条,即第一次的offset为0的话,下一次遍历的offset则为15,同样日期也可以用range的方法进行赋值:
#抓取20号到23号的数据
date = range(20,23)
for day in date:
for page in range(0,100):
url1 = url.format(page*15,str(day))三.load其中的json内容,从中筛选提取出自己需要的数据:
通过将得到的json数据解析后,发现其中评论在cmt和hcmt两个key内,通过loads的方法将json转化为字典:
def get_json(url,k_name):
json_str = requests.get(url=url,headers=headers).content
data = json.loads(json_str)
data = data[str(k_name)]
return data楼主中间尝试了很多次,发现有时会经常出现重复的数据,经过研究发现,cmt中是最新的评论,而hcmt中是最热的10条评论,只有10条(怪不得一直看到这几条。。。)
于是采用对整体进行cmt采取遍历,但是在遍历中,只对hcmt中的评论的content内容取1次的方法,在外围设置cnt计数实现:
# 最新短评
data_cmts = get_json(url1,'cmts')
# 最热短评
data_hcmts = get_json(url1, 'hcmts')
for data_cmt in data_cmts:
item = {}
if cnt == 0:
for data_hcmt in data_hcmts:
#最热评论
print(data_hcmt['content'])
cnt+=1
#输出最新评论
print(data_hcmt['content'])
四.保存成csv格式的文件
最终将文件保存,由于评论数据中不止有评论内容,还包含评论时间,评论作者,评论地点等一些内容,所以采用了pandas的方法来存储成csv格式,考虑到采集数据过程中可能会出现异常,故使用try,,except的格式来进行,当采集到的数据为空时,就表示采集完毕,保存到csv文件中:
df = pd.DataFrame(columns=['city','content'])
try:
....
item = {}
item['city'] = data_cmt['cityName']
item['content'] = data_cmt['content']
item['date'] = data_cmt['startTime']
df = df.append(item, ignore_index=True)
except Exception as e:
df.to_csv('train_set.csv',encoding='utf_8_sig')
continue
完整代码可以移步github,水平不足,希望多多拍砖,感谢!
github:
https://github.com/476736794/-
转载自原文链接, 如需删除请联系管理员。
原文链接:Python爬虫爬取猫眼电影风语咒影评评论信息,转载请注明来源!