爬虫之爬取英雄联盟战绩详细数据
思路解析:
我们首先打开LOL游戏官网,登录自己的账号(因为牵扯到账号,所以需要用到cookie),然后选择你想爬取数据的大区!
在这个界面我们按下F12查看源代码,在Network下的JS里,刚开始什么都没有,我们需要重新加载网页然后才会显示各种数据
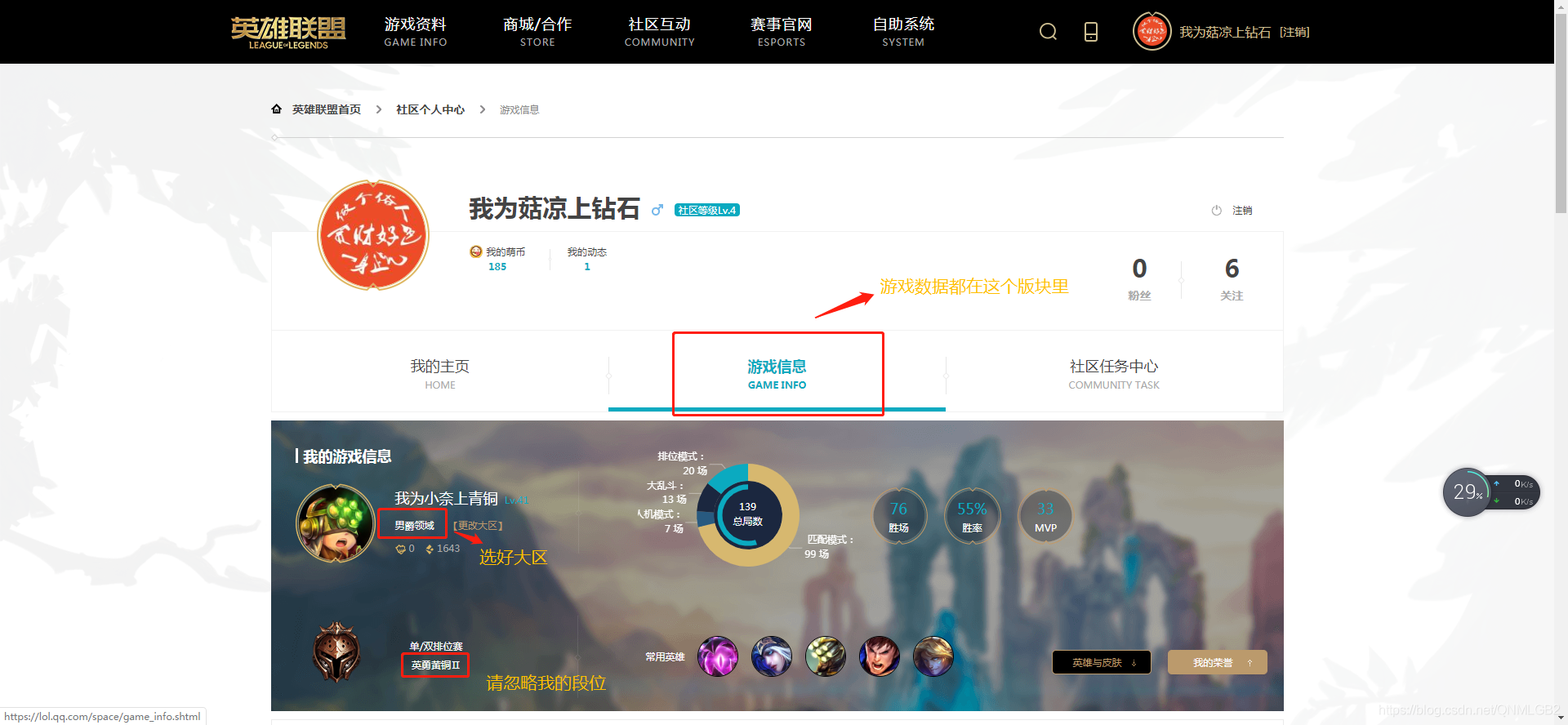
如果你看下除了第一个?c=Battle的其他相同名字数据就会发现,下面的每一条数据正好对应着左侧的每一局游戏,我们点开几个游戏数据,在general的url里发现只有一个参数变了,那就是gameId,这个gameId在哪里得到的呢?就是从第一条?c=Battle的数据里得来的.

这里我们找到了gameId的位置,只要把所有的gameId得到,就可以进一步提取每一局的游戏数据了
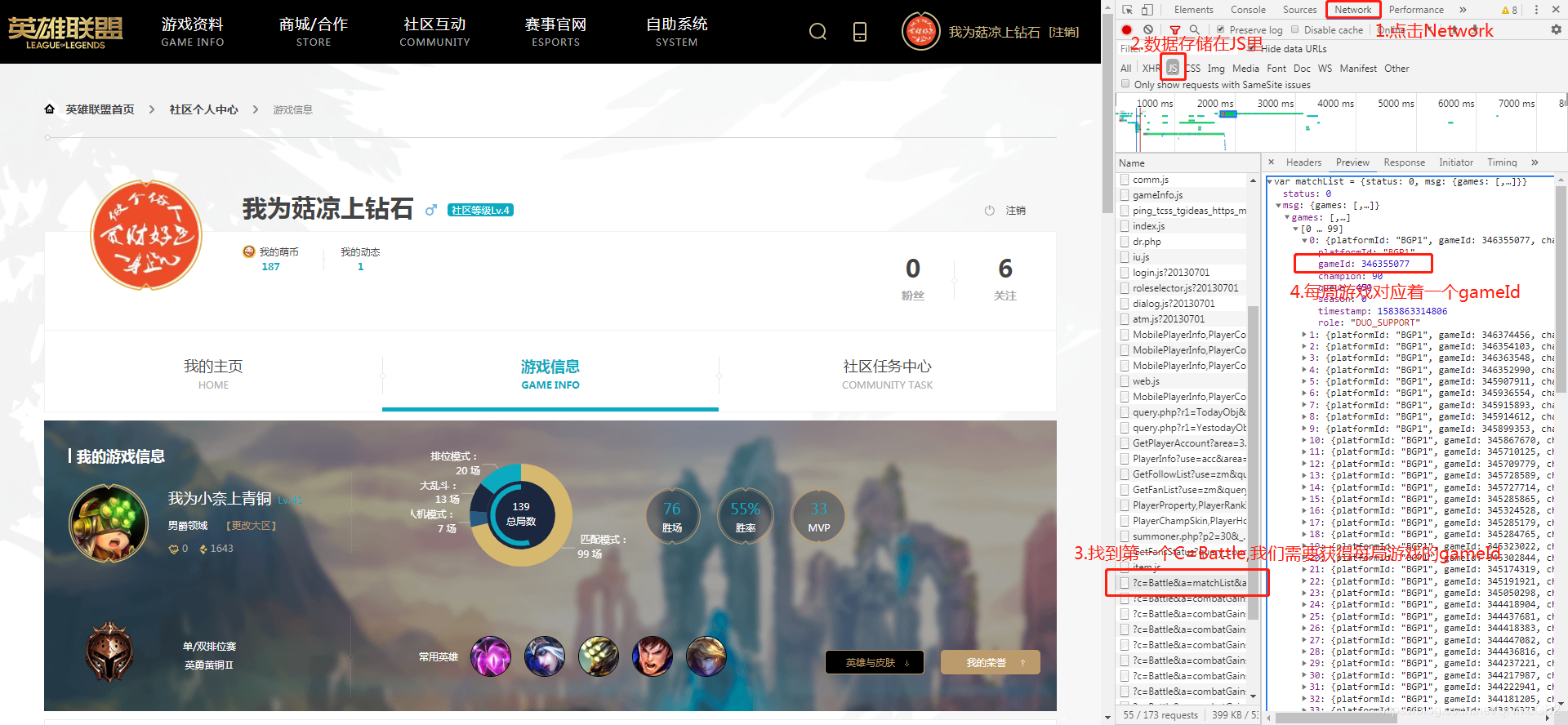
我们通过第一条游戏数据,找到队伍里自己的位置,我是在第六的位置,然后在stats里就是自己的详细游戏数据了,我们这次要爬取的数据主要就是在这里.
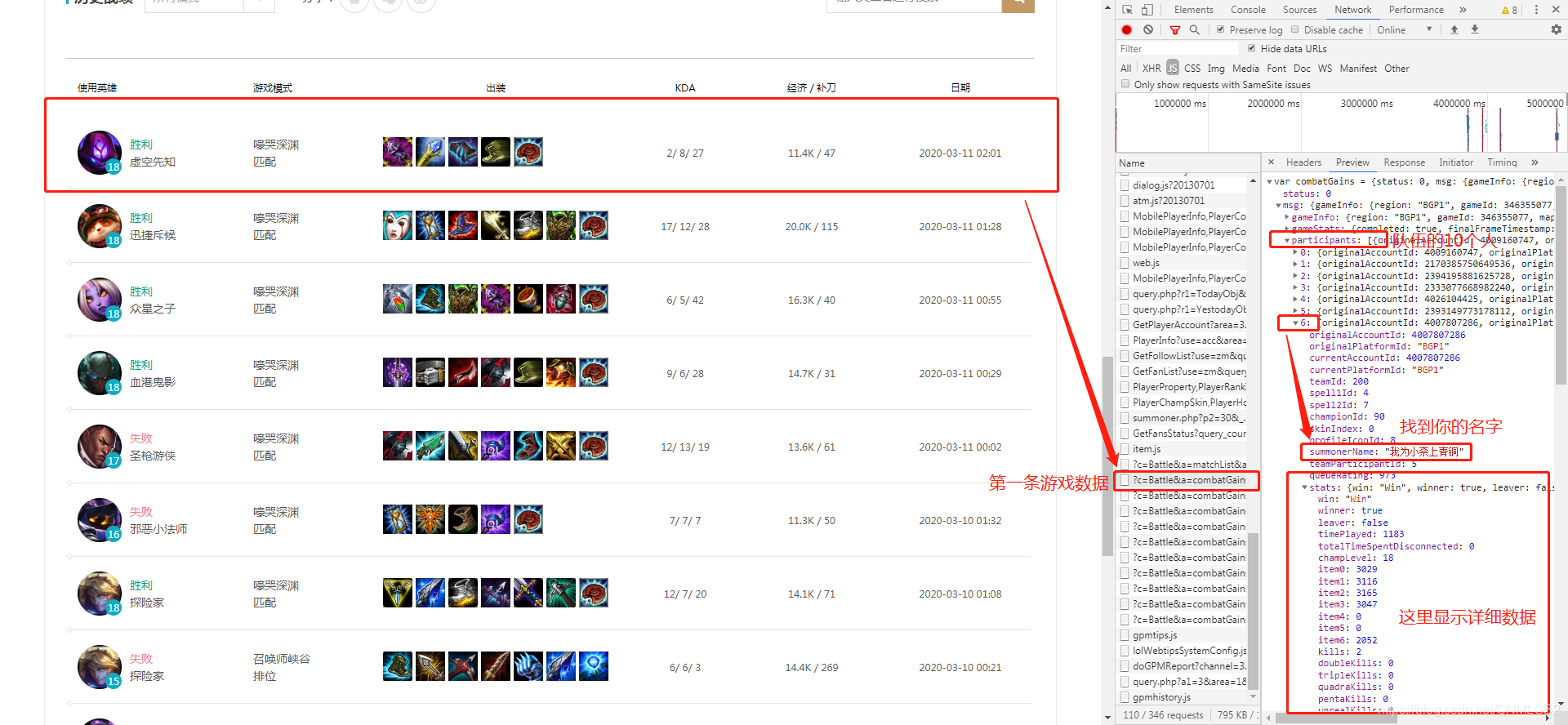
我们看下gameId的获取方式,知道url,请求方式为get,接下来就可以上代码了
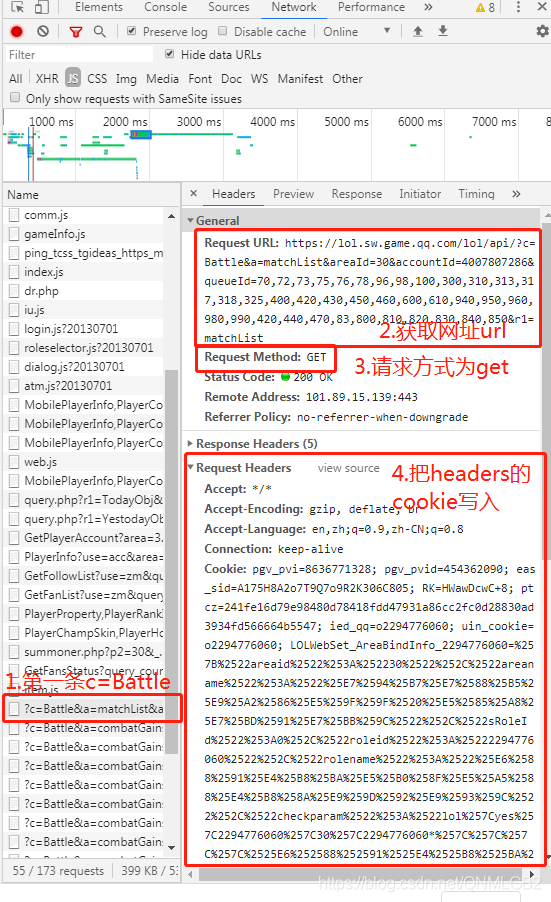
第一部分,获取gameIds
import requests,json #导入模块
url = 'https://lol.sw.game.qq.com/lol/api/?c=Battle&a=matchList&areaId=30&accountId=4007807286&queueId=70,72,73,75,76,78,96,98,100,300,310,313,317,318,3'#太长了,输入你自己的网址就行了
headers = {'Cookie':'因太长,写入你自己的就可以了',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'}#防止反爬虫
#获取网页源代码
res = requests.get(url,headers = headers) #解析这个网页
print(res.status.code)#状态码为200说明正常
print(res.text) #打印看看是不是有很多数据,有就对了,如果只有两行说明哪地方出错了
json = json.loads(res.text[16:]) #因为response的前面16个字符不是json格式的,所有要去除
#获取所有游戏的gameId
games = json['msg']['games'] #获取所有game信息的列表
gameIds = [] #创建一个存放gameId的列表
for game in games:
gameId = game['gameId']
gameIds.append(gameId)
print(gameIds) #打印看看有多少gameId **如果你隔很长时间重新玩的游戏,只能取最近玩的游戏数据,因为他的cookie不一样,所以取全部gameId可能会报错**
代码实际效果

第二部分,获取每局战绩的详细数据
我们先分析每一局游戏的数据,和第一部分一样,根据url和cookie获取网页源代码
import requests,json #导入模块
url2 = 'https://lol.sw.game.qq.com/lol/api/?c=Battle&a=combatGains&areaId=30&gameId=346355077&r1=combatGains'导入一局游戏的url
headers = {'cookie':'输入你的cookie','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'}#防止反爬虫
res2 = requests.get(url2,headers=headers)
json2 = json.loads(res2.text[18:])#将源代码前面不是json格式的去掉
participants = json2['msg']['participants']#获取一局游戏10人的战绩列表
找到自己的战绩
for own in participants:
if own['summonerName'] =='自己游戏ID':#输入自己的游戏ID,如果匹配,就继续执行下面的代码,否则跳过
try: #有的游戏某一项没有数据,例如大乱斗没有插眼数据,用try防止报错,
#游戏数据
stats = own['stats'] #转到stats这一项中,有战斗数据
win = stats['win'] #是否胜利,win为赢,fail为输
kills = stats['kills'] #击杀
deaths = stats['deaths'] #死亡
assists = stats['assists'] #助攻
visionWardsBought = stats['visionWardsBoughtInGame']#买的真眼数
wardsPlaced = stats['wardsPlaced'] #放置守卫数
wardsKilled = stats['wardsKilled'] #击杀守卫数
goldEarned = stats['goldEarned'] #游戏挣的金币
minionsKilled = stats['minionsKilled'] #击杀小兵
inhibitorKills = stats['inhibitorKills'] #摧毁水晶
#你还想写什么可以按照这种方法找,游戏模式,使用英雄,出装,伤害等等都可以
print(win,kills,deaths,assists,visionWardsBought,wardsPlaced,wardsKilled,goldEarned,minionsKilled,inhibitorKills)#把这些打印出来
except:
print(i)#输出没游戏数据的gameId
else:#这是其他9人的数据,如果你想分析也可以下载看看
pass
这是一局游戏的数据,如果你想下载所有游戏数据只要加个循环就可以了
所有游戏数据在这里
我只循环了前20项
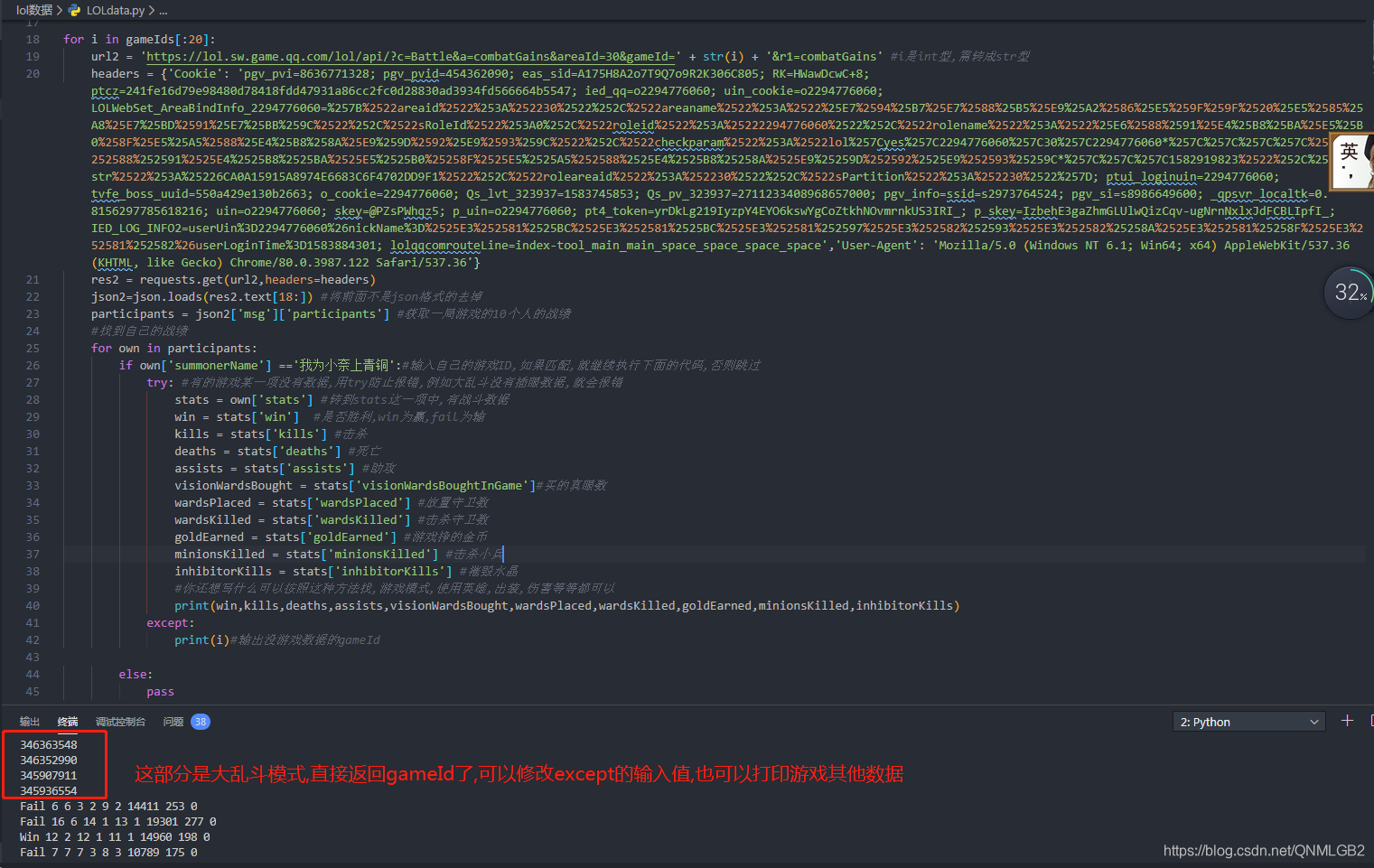
第三部分,存入Excel,方便可视化
import openpyxl #导入Excel模块
#设置Excel
wb = openpyxl.Workbook() #创建工作簿
ws = wb.active #创建工作表
ws.title = 'LOL数据' #表名为LOL数据
ws.append(['胜负','击杀','死亡','助攻','买眼数','放置守卫数','击杀守卫数','挣金币数','击杀小兵数','摧毁水晶数'])#创建第一行
'''省略获取数据部分''''
try:
'''
省略
'''
ws.append([[win,kills,deaths,assists,visionWardsBought,wardsPlaced,wardsKilled,goldEarned,minionsKilled,inhibitorKills])#在循环内部把每一条数据加到表格里
wb.save('LOL数据.xlsx') #保存文件
全部代码在这里
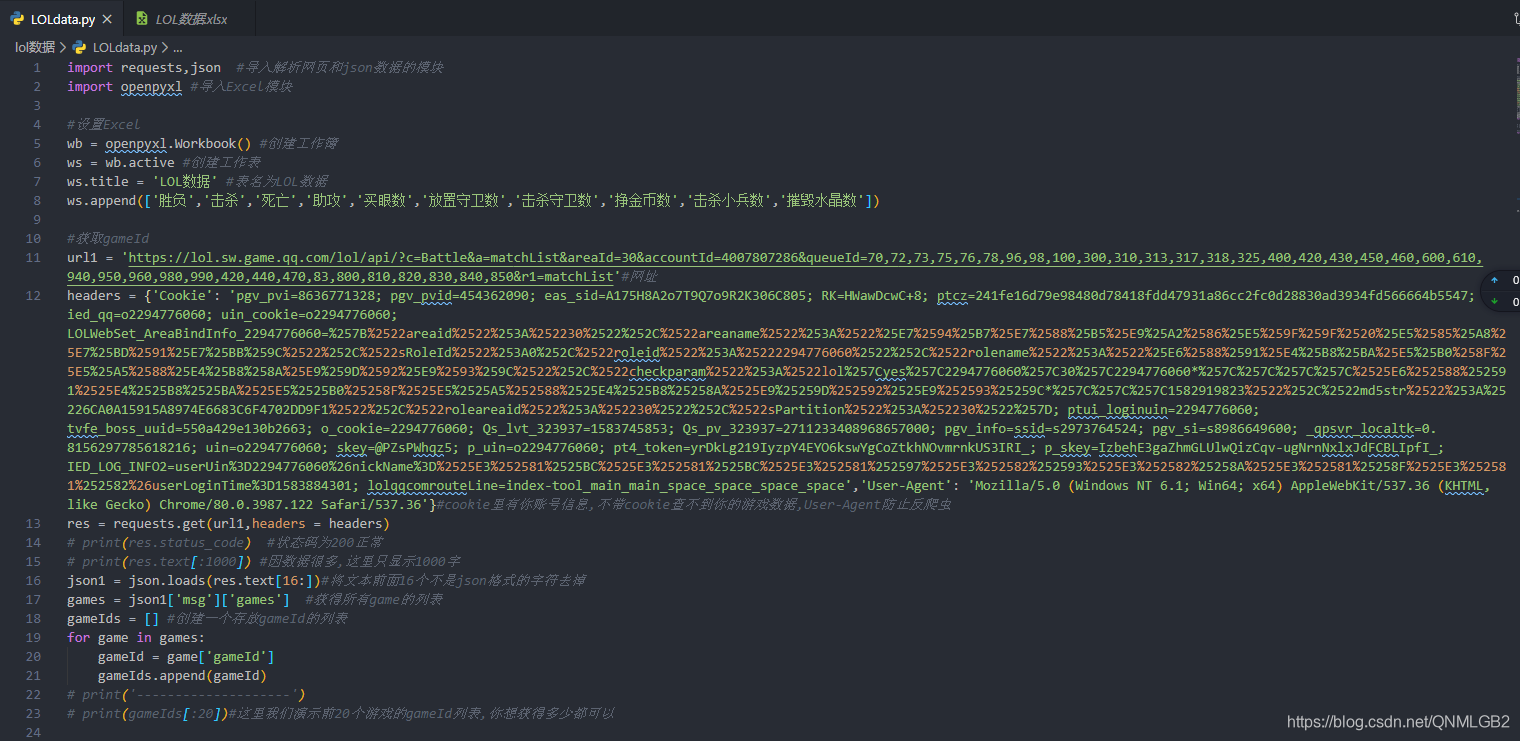
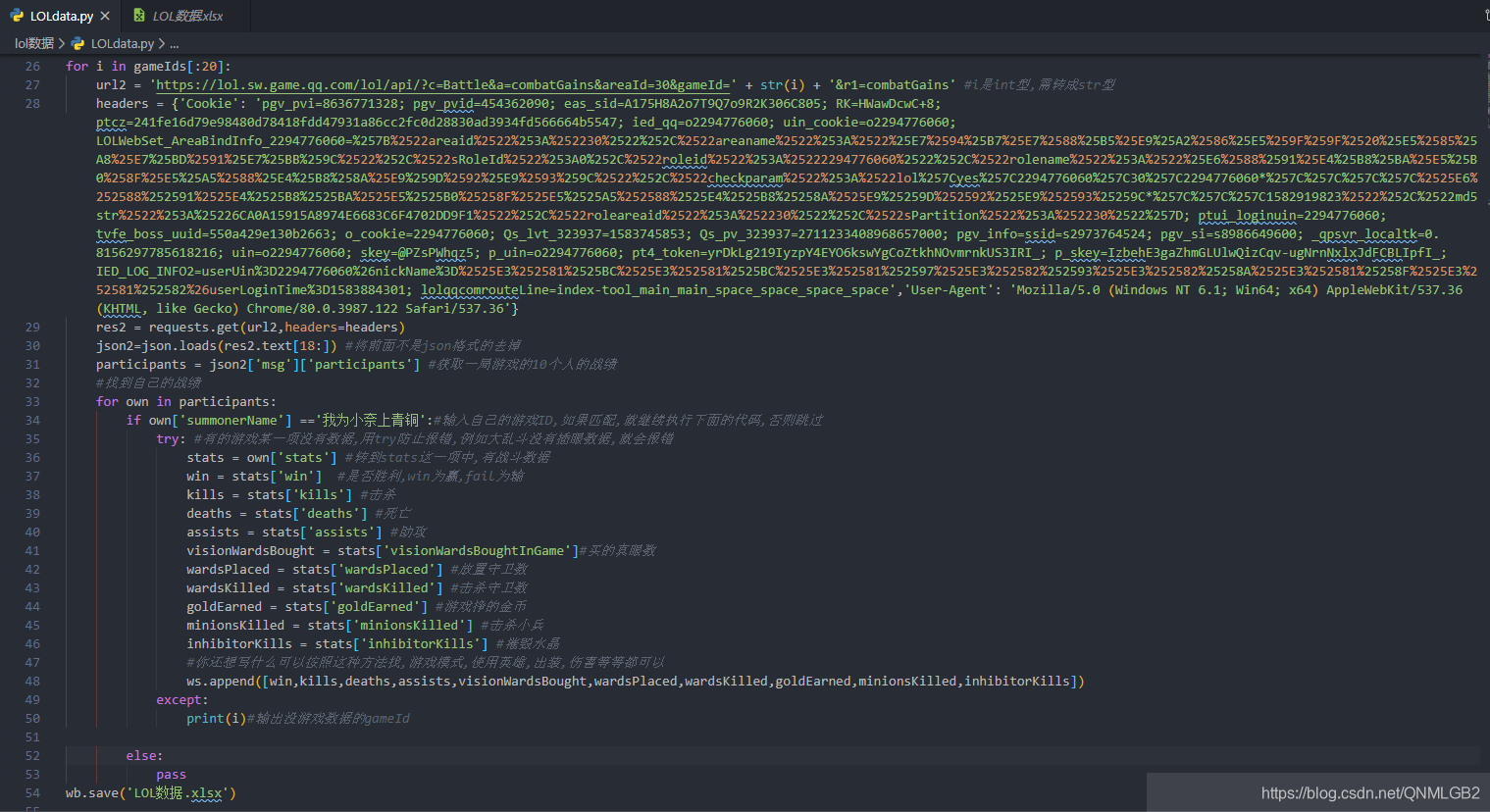
得到的Excel
循环了20次,其中7次大乱斗的数值没有提取,Excel效果如下

第四部分,数据可视化
还没学会,溜了溜了
第一次发表文章…
转载自原文链接, 如需删除请联系管理员。
原文链接:爬虫之爬取英雄联盟战绩详细数据,转载请注明来源!