1.利用python抓取网站上的图片,对于学习python及对网页数据分析处理很有帮助,也可以学习一些web方面的知识,我尝试使用【搜狗图片】搜索到的图片作为抓取对象,抓取【搜狗图片】主页各个标题栏的图片,以及【其他】输入图片类型的图片,使用tkinter完成了一个简单的UI界面。
2.一般抓取网页图片,需要先访问页面,然后提取源码,依次解析各个图片URL,然后直接下载即可,这些网上的教程很多,在此不再赘述。但是对于一些图片较多的页面,往往使用动态加载的方式呈现图片,也就是我们抓取的页面源码中,并没有各个图片的URL,这就需要 分析页面结构,找到页面图片真正的URL资源地址,才能完成下载。
3.例如在【搜狗图片】搜索美女,然后点进图片,查找该图片的URL地址:
【请求URL】:


【页面源码】:找不到对应的图片URL。
但是通过分析发现图片是动态加载出来的,然后参考了 Python爬取网页中的图片(搜狗图片)详解 ,
发现【标题类】的图片都集中在如下URL:


而通过【搜索】得到得图片URL集中在:

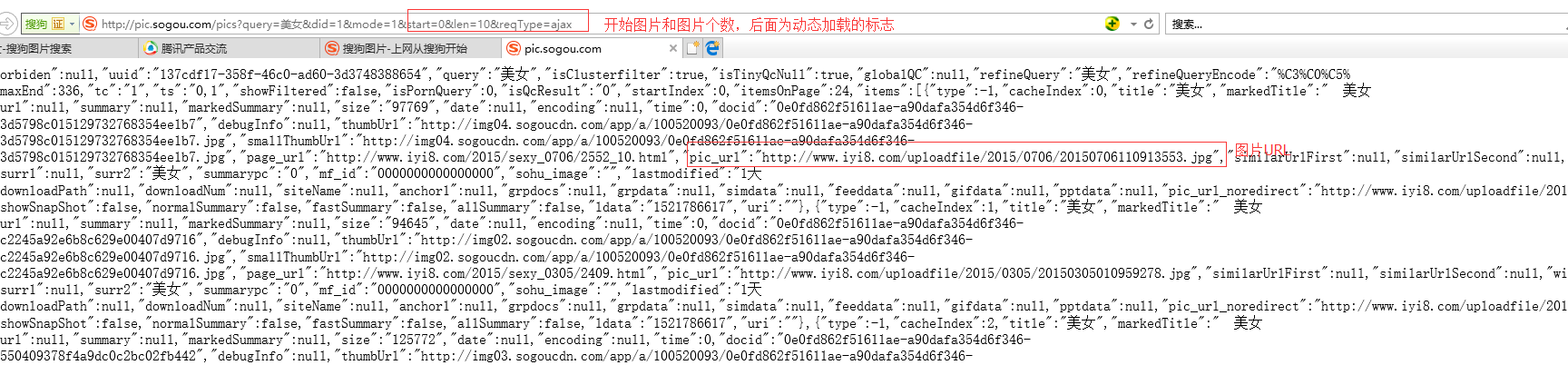
这样,就可以很清楚的得到各个图片URL的地址,爬取图片了。
4.源码:
#-*- encoding=UTF-8 -*-
import urllib.request,socket,re,sys,os
from urllib.request import urlopen
import time
from tkinter import *
import webbrowser
from bs4 import BeautifulSoup
import requests
import json
import urllib
##############################常量区##############################
sougou_url="http://pic.sogou.com/"
###URL
download_pics_path="C:/bz2018/"
download_pics_num=10
download_success = ""
sougou_pics_tag=["pic_url","thumbUrl","bthumbUrl","ori_pic_url"]
sougou_url_pics_start="http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category="
sougou_url_pics_mid="&tag=%E5%85%A8%E9%83%A8&start=0&len="
sougou_url_pics_start_other="http://pic.sogou.com/pics?query="
sougou_url_pics_mid_other="&did=1&mode=1&start=0&len="
sougou_url_pics_stop_other="&reqType=ajax"
###title
title_key_start="a class=\"nav-tab\" href=\"/pics/"
title_key_stop="<"
###tkinter
window_name="搜狗图片下载器"
window_size="500x500"
frm_bg="white"
real_columnspan=4
label_type_str="---------------------------------------------图片类型---------------------------------------------"
##############################常量区##############################
real_url_arr = [] ###组成url集合
##############################函数区##############################
###获取网页上标题,返回标题数组
def get_title(url):
html = urlopen(url)
sougou_html = BeautifulSoup(html.read())
title_key = []
for ihtml in sougou_html:
data1 = str(ihtml).split(title_key_start)
if len(data1) > 1:
for jhtml in data1:
data2 = jhtml.split(title_key_stop)[0]
data3 = data2.split("\">")
if len(data3) == 2:
title_key.append(data3[1])
return title_key
###获取网页图片并下载,返回下载失败个数
def get_pics(url,path):
# 检测当前路径的有效性
if not os.path.isdir(path):
os.mkdir(path)
pics_str = requests.get(url)
pics_dict = json.loads(pics_str.text)
pics_dict_items = pics_dict['all_items']
i_item=0
fail_count=0
for item in pics_dict_items:
fail_flag=0
for itag in sougou_pics_tag:
try:
pic_url=item[itag]
pic_title=item['title']
if pic_title == "":
pic_title = str(i_item)
i_item = i_item + 1
if pic_url != "":
urllib.request.urlretrieve(pic_url, path + pic_title + '.jpg')
print(pic_title+": download complete!")
fail_flag=1
break
except:
print("download fail!")
continue
if fail_flag != 1:
fail_count=fail_count+1
return fail_count
def get_pics_other(url,path):
pics_str = requests.get(url)
pics_dict = json.loads(pics_str.text)
pics_dict_items = pics_dict['items']
i_item=0
fail_count=0
for item in pics_dict_items:
fail_flag=0
for itag in sougou_pics_tag:
try:
pic_url=item[itag]
pic_title=item['title']
pic_title=pic_title+str(i_item)
i_item = i_item + 1
if pic_url != "":
urllib.request.urlretrieve(pic_url, path + pic_title + '.jpg')
print(pic_title+": download complete!")
fail_flag=1
break
except:
print("download fail!")
continue
if fail_flag != 1:
fail_count=fail_count+1
return fail_count
def url_get_othertype():
global real_url_arr
if PhotoType.get() != "":
real_url_arr.append(PhotoType.get())
real_url_arr = list(set(real_url_arr))
def url_get_phototype(all_type):
global real_url_arr
real_url_arr=[]
url_get_othertype()
if "其他" in all_type:
all_type.remove("其他")
for i in range(len(all_type)):
if CheckType[i].get() == 1:
real_url_arr.append(typeBtn[all_type[i]]['text'])
real_url_arr = list(set(real_url_arr))
def other_type():
if OtherType.get() == 1 :
type["state"] = "normal"
else:
type["state"] = "disabled"
PhotoType.set("")
def get_full_url(all_type):
global download_pics_num
down_result["text"] = ""
url_get_phototype(all_type)
if download_num_str.get() != "":
download_pics_num = int((download_num_str.get()))
sum = len(real_url_arr) * download_pics_num
down_result["text"] = "准备下载: " + str(sum) + "张照片"
fail_num = 0
for iurl in real_url_arr:
if iurl in photo_type:
tmp_url=sougou_url_pics_start+iurl+sougou_url_pics_mid+str(download_pics_num)
fail_num = fail_num + get_pics(tmp_url, download_pics_path)
else:
tmp_url=sougou_url_pics_start_other + iurl + sougou_url_pics_mid_other + str(download_pics_num) + sougou_url_pics_stop_other
time.sleep(1)
fail_num = fail_num + get_pics_other(tmp_url, download_pics_path)
down_result["text"] ="成功下载: " + str(sum-fail_num) + "张照片"
###tkinter label占一行
def write_line(row,text="",column=0,columnspan=real_columnspan,bg=frm_bg):
label = Label(frm, text=text, bg=bg)
label.grid(row=row, column=column,columnspan=columnspan)
return label
###调用网页
def callback(url=sougou_url):
webbrowser.open_new(url)
##############################函数区##############################
##############################UI部分##########################################
root =Tk() #给窗体
root.title(window_name) #设置窗体名字
root.geometry(window_size)
root.resizable(width=False, height=False) ###固定窗体大小
frm=Frame(root,bg=frm_bg) #新建框架
frm.pack(expand = YES,fill = BOTH) #放置框架
###控制行的参数
real_row=0
###空一行
write_line(real_row)
real_row=real_row+1
###进入官网
Button(frm,text="点击进入搜狗图片官网",command=callback).grid(row=real_row,column=0,columnspan=real_columnspan,sticky=N)
real_row=real_row+1
###空一行
write_line(real_row)
real_row=real_row+1
###图片类型
write_line(real_row,label_type_str)
real_row=real_row+1
###空一行
write_line(real_row)
real_row=real_row+1
###checkbutton
photo_type=get_title(sougou_url)
photo_type.append("其他")
typeBtn={}
CheckType=[]
real_column=0
for itype in photo_type:
if itype == "其他":
OtherType = IntVar()
PhotoType = StringVar()
type = Entry(frm, textvariable=PhotoType, width=9, state='disabled') # 添加输入框
Checkbutton(frm, text="其他", variable=OtherType, onvalue=1, offvalue=2, command=other_type).grid(row=real_row, column=1)
type.grid(row=real_row, column=2, columnspan=4, sticky=W, padx=40, ipadx=60) # 放置输入框位置
else:
CheckType.append(IntVar())
typeBtn[itype]=Checkbutton(frm, text=itype, variable=CheckType[-1], command=lambda: url_get_phototype(photo_type))
typeBtn[itype].grid(row=real_row, column=real_column)
real_column=real_column+1
if real_column == 4:
real_column = 0
real_row = real_row + 1
real_row=real_row+1
###空一行
write_line(real_row)
real_row=real_row+1
###下载个数
lab1 = Label(frm,text = "下载个数:")# 添加Label
lab1.grid(row = real_row,column=0)
download_num_str = StringVar()
download_num = Entry(frm,width=10,textvariable=download_num_str)# 添加Entry
download_num.grid(row = real_row,column=1,sticky=W)
real_row=real_row+1
###空一行
write_line(real_row)
real_row=real_row+1
###get
Button(frm,text="获取照片",command=lambda: get_full_url(photo_type)).grid(row=real_row,column=0,columnspan=4,sticky=N)
real_row=real_row+1
###空一行
write_line(real_row)
real_row=real_row+1
###结果
down_result=write_line(real_row)
real_row=real_row+1
###空一行
write_line(real_row)
real_row=real_row+1
Button(frm,text="退出程序",command=root.quit).grid(row=real_row,column=0,columnspan=4,sticky=N)
real_row=real_row+1
mainloop()
##############################UI部分##########################################