coordinate-wise minimization(坐标朝向最小)
coordinate-wise minimization介绍的是坐标下降法的理论依据。
问题的描述:给定一个可微的凸函数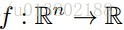
,使得
在每一个坐标轴上都是最小值,那么
 是不是一个全局的最小值。
是不是一个全局的最小值。
形式化的描述为:是不是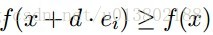
都有
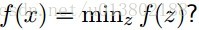
这里的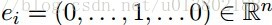 个标准基向量。
个标准基向量。
答案为成立。
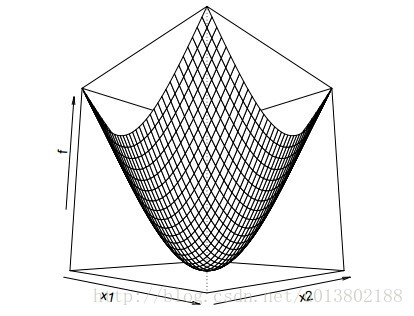
这是因为:
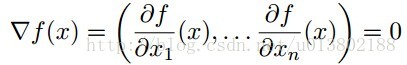
但是问题来了,如果对于凸函数,若不可微该会怎样呢?
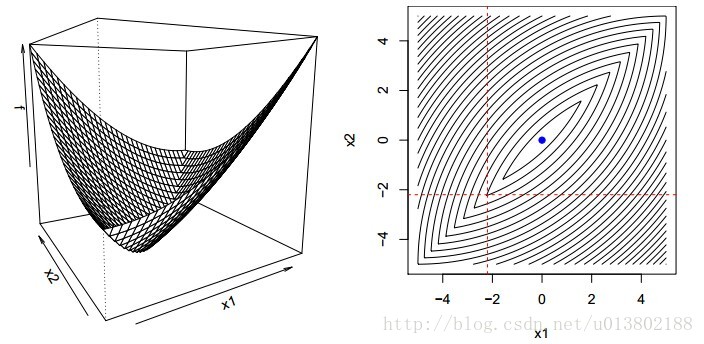
答案为不成立,上面的图片就给出了一个反例。
那么同样的问题,现在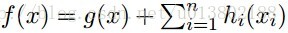
是可微的凸函数,每一个
都是凸的?这其实就是Lasso回归的目标函数。
答案为成立。
证明如下,对每一个
给定一个可微的凸函数
,使得
在每一个坐标轴上都是最小值,那么
坐标下降(Coordinate descent)
坐标下降法属于一种非梯度优化的方法,它在每步迭代中沿一个坐标的方向进行线性搜索(线性搜索是不需要求导数的),通过循环使用不同的坐标方法来达到目标函数的局部极小值。
算法过程
假设目标函数是求解的极小值,其中
是一个n维的向量,我们从初始点
开始(
是我们猜想的一个初值)对k进行循环:
相当于每次迭代都只是更新的一个维度,即把该维度当做变量,剩下的n-1个维度当作常量,通过最小化
来找到该维度对应的新的值。坐标下降法就是通过迭代地构造序列
来求解问题,即最终点收敛到期望的局部极小值点。通过上述操作,显然有:
证明如下:
当时,对应的
的值为
由于,所以
,以此类推
所以
所以
同理可得,命题得证。
相比梯度下降法而言,坐标下降法不需要计算目标函数的梯度,在每步迭代中仅需求解一维搜索问题,所以对于某些复杂的问题计算较为简便。但如果目标函数不光滑的话,坐标下降法可能会陷入非驻点。
流程总结:
- 首先,我们把,上面的括号里面的数字代表我们迭代的轮数,当前初始轮数为0。
- 对于第
轮的迭代。我们从
开始,到
为止,依次求
。
的计算表达式如上文所描述。 - 检查
向量和
向量在各个维度上的变化情况,如果在所有维度上变化都足够小,那么
轮的迭代。
小结
关于坐标下降法,有几点需要注意的:
- 坐标下降的顺序是任意的,不一定非得按照从的顺序来,可以是从1到n的任意排列。
- 坐标下降的关键在于一次一个地更新,所有的一起更新有可能会导致不收敛。
- 坐标上升法和坐标下降法的本质一样,只不过目标函数成为求
变成
了。
坐标轴下降法的求极值过程,可以和梯度下降做一个比较:
- 坐标轴下降法在每次迭代中在当前点处沿一个坐标方向进行一维搜索 ,固定其他的坐标方向,找到一个函数的局部极小值。而梯度下降总是沿着梯度的负方向求函数的局部最小值。
- 坐标轴下降优化方法是一种非梯度优化算法。在整个过程中依次循环使用不同的坐标方向进行迭代,一个周期的一维搜索迭代过程相当于一个梯度下降的迭代。
- 梯度下降是利用目标函数的导数来确定搜索方向的,该梯度方向可能不与任何坐标轴平行。而坐标轴下降法法是利用当前坐标方向进行搜索,不需要求目标函数的导数,只按照某一坐标方向进行搜索最小值。
- 两者都是迭代方法,且每一轮迭代,都需要O(mn)的计算量(m为样本数,n为系数向量的维度)
参考文章
转载自原文链接, 如需删除请联系管理员。
原文链接:【机器学习】坐标下降法(Coordinate descent),转载请注明来源!