写在前面的话
偶尔出来放个比较大的招啦。这是我自己目前研究领域的一分部,基于k-gram hash 查重检测文档的相似性这个技术已经是相当成熟的。这个是我这几个月的工作方向中最小的一个模块之一,现在和大家稍微稍微稍微的分享一下我自己的感悟和心得。
我比较菜,也比较水,可能很多东西没有前辈们掌握的更加透彻,参悟的更加明白,欢迎各位大神给我提提意见。
前天改完作业,我突然发现了好几份相似的代码,逻辑思维和代码风格都全部一样。熊孩子们又没有好好做作业,我就想这两天写个自动化检测的剽窃的脚本,把抄作业的熊孩子找出来。哈哈哈,大家不用担心,你只要不要让我觉得抄的很过分,我会考虑放过你的。只不过看着这么好一堆的ground truth 在我面前,这好可以检测我写的代码的正确性,有什么地方可以改进的。还有一点,请各位同学不!要!抄!作!业!因为我是过目不忘的,请不要往枪口上撞。
我的标题是不是起的很奇怪,我自己也觉得很奇怪。我想了半天才想出来这么个名字,首先它是基于k-gram 的,有个时候我们看某些文献的时候,你可能会发现人家叫n-gram,这两个东西其实就是相同的。我们基于 k-gram hash 算法主要的目的就是来提取我们文档或者是代码的特征值,我们根据这些特征值来找到和该文档相似的其他文档,所以我们可以用这种技术来判断软件的相似性(similarity)以及用来查重(clone),剽窃(plagiarism)检测。
总的来说,这个算法的效果还是很不错的。
1.背景知识
首先我们这篇文章的主要讲的是一个03年就提出的技术。我们主要参考的是这篇文章:Winnowing: Local Algorithms for Document Fingerprinting 你可以在这个地方下载到这篇文章。
1.1winnowing


winnowing 这个词用英语翻译过来是“扬场”的意思,就是用风过滤筛选种子的意思。在一大堆的东西中我们只留下对我们有价值的东西(如饱满的种子),然后让风吹去没有价值的东西比如我们的麦秆之类的。



用我们中国话比较文绉绉一点的就是:取其精华去其糟粕! 保留对我们有用的,丢弃那些干扰项。
就行很有农情意味的 : 用簸箕挑选种子去沙的道理是一样的。
我是不是话太多了。
绝对良心博客!
1.2 k-gram model
这个模型在做NLP自然语言处理的时候经常能够用得到,做这个方向的同学应该对这个概念是比较清楚的。
K-gram/ n-gram 英文翻译过来就叫做n元语法模型
参见维基百科:
n-gram English version
n-gram 中文版
我们其实在密码学中接触过这个概念,Playfair Cipher加密算法就是使用了这样一种分类的概念。
k-gram 就是将一个连续的文本进行切割,每一个部分的长度都是k。当长度为1,2, 3时 分别对应的名称叫做 一元语法(1-gram unigram), 二元语法(bigram),三元语法(trigram).
为了形象的说明这个问题,我们来举一个简单的例子。有一个简单的文档 叫做A,由字母yabbadabbadoo组成:
我们给它们都编一个号:
0 1 2 3 4 5 6 7 8 9 10 11 12
A : y a b b a d a b b a d o o
这个时候我们在A这个文档上取一个大小为3的滑动窗口,就得到了一个3-gram 的集合:

A : yab abb bba dad ada dab abb bba bad ado doo
我们把这个集合中的元素都称为shingle.
下面我们再来看另一个文档C,文档C由下面的这些字符组成的:doobeedoobeedoo
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
C : d o o b e e d o o b e e d o o
我们在为3构建一个3-gram 的集合,那么组成的shingle就是下面这个样子的:
C : doo oob obe bee eed edo doo oob obe bee eed edo doo
那么我们要比较A和C之间的相似性,我们很容易看出来我们只要比较他们的Shingle集合中相似的有多少就可以了。 在A和C集合中我们可以发现他们共有的元素是doo,但是他在A集合中出现了一次,在C集合中出现了三次。
那么这里就有两种可能,一种就是这是偶然的,还有一种假设就是万一真的存在剽窃呢,那就是说明doo 从A中被复制到C中三次。
但是其实这种情况,完全是取决与我们的K
看下面我们对A和C进行重新的划分,我们去k=4
A : yabb abba bbad bada adab dabb abba bbad dado adoo
C : doob oobe obee beed eedo edoo doob oobe obee beed eedo edoo
可以看出现在这样子划分,这两个字符串是完全没有相似性可言的。
注意: 通过我们前面的观察,或者计算,对于一个含有N个字符的文档,我们按照k来划分得到的shingle 的个数是:
N-K+1
1.2.1 K的选取
根据上面的分析我们知道,在这里最重要的就是选取K值。那么我们要怎么分割呢,一般我们文档的常见单词(不重要的出现频率大)的长度必须要小于 K.
注意注意重点来了!!!
我们选取的K必须大于文档中常见的不重要的单词,比如说在一个文档里,中文文档,最常见的单词应该是“的”,这个次几乎是每个文档都会出现的,但是这个次可能对于文档的相似性判断没有任何重要性而言。
又比如说我们英文当中的the 和我们程序当中的if 都是我们不太关心的,所以K的取值一般要比这些单词要大。这样就很好的剔除了文档中自然产生的相似性。
我们使用论文中的原话来讲,我们要查找一些我们感兴趣的信息,重要的shingle的长度必须要大于K,这些使我们感兴趣的,比K小的就是我们不敢兴趣的。你看,这是不是就是一个简单的过滤过程,首先通过K我们可以过滤掉一些信息。
k-gram 最有意思的特征就是,在某种程序上他对于排序是不敏感的。注意关键词, 某种程度上是不敏感的. 这样可以防止有的人重新排列了我们的文档,这种情况在代码中最为常见,比如说一个代码中有两个类,我们先后调换一下位置,这两份文档还是不能躲过我们k-gram hash 算法的火眼金睛。
比如说我们将 yabbadabbadoo 重新排列成 bbadooyabbada 混淆之后我们得到文档的shingle集合是:
A: bba bad ado doo ooy oya yab abb bba bad ada
通过观察我们可以发现,3连字任然完整无缺的出现在其中,那么我们把这个文档和我们的C文档比较一下,他们的相似度是不变的。
1.3 hash 算法
我们创造出一个东西,当然是为了让世界更美好。所以当然是要投入到社会使用的嘛。但是,however, but, while 要是存储一个大的文档和一大堆的文件的所有的shingle这个效率实在是太低了。我们直接把这些shingle替换成hash来做比较,一切都是为了效率,一切都是为了性能。
所以这货的完整名字应该叫做基于 K-gram hash 算法分析。
why?
为什么转换成哈希效率就会改变呢?为什么呢?平时多问几个为什么总是好的。
因为简单概括,hash 算法的实质就是把大把大把的数据映射成比较短的固定长度的散列值。提高存储效率。就是这么简单,所以人们要这么做。
详细的解释和hash算法我们看下面我的解释。
亲们,有的人搞混了在数据结构中学到的哈希表以及密码学中的哈希算法,这两个东西是完全不一样的东西。
Hash 算法就是把任意长度的输入,通过散列算法,变换成固定长度的输出。该输出就是散列值。这种转换是一种压缩映射,散列值的空间一般远小于输入的空间。 但是如果不同的数据通过hash 算法得到了相同的输出,这个就叫做碰撞,因此不可能从散列值来唯一确定输入值。
一般的hash 算法我们都要求满足几个条件:
- 单向性(one-way), 从预映射,能够简单迅速的得到散列值,而在计算上不可能构造一个预映射,使其散列结果等于某个特定的散列值,即构造相应的M=H-1(h)不可行。这样,散列值就能在统计上唯一的表征输入值,因此,密码学上的 Hash 又被称为”消息摘要(messagedigest)”,就是要求能方便的将”消息”进行”摘要”,但在”摘要”中无法得到比”摘要”本身更多的关于”消息”的信息。
- 第二是抗冲突性(collision-resistant),即在统计上无法产生2个散列值相同的预映射。给定M,计算上
无法找到M’,满足H(M)=H(M’) ,此谓弱抗冲突性;计算上也难以寻找一对任意的M和M’,使满足H(M)=H(M’)
,此谓强抗冲突性。要求”强抗冲突性”主要是为了防范 所谓”生日攻击(birthdayattack)”,在一个10人的团
体中,你能找到和你生日相同的人的概率是2.4%,而在同一团体中,有2人生日相同的概率是11.7%。类似的,
当预映射的空间很大的情况下,算法必须有足够的强度来保证不能轻易找到”相同生日”的人。
- 第三是映射分布均匀性和差分分布均匀性,散列结果中,为 0 的 bit 和为 1 的 bit ,其总数应该大致
相等;输入中一个 bit的变化,散列结果中将有一半以上的 bit 改变,这又叫做”雪崩效应(avalanche effect)”;
要实现使散列结果中出现 1bit的变化,则输入中至少有一半以上的 bit 必须发生变化。其实质是必须使输入
中每一个 bit 的信息, 尽量均匀的反映到输出的每一个 bit上去;输出中的每一个 bit,都是输入中尽可能
多 bit 的信息一起作用的结果。
hash 算法最常用的就是加减乘除和移位运算。我们先来看几个常用常见的哈希函数吧。
RS hash
public long RSHash(String str)
{
int b = 378551;
int a = 63689;
long hash = 0;
for(int i = 0; i < str.length(); i++)
{
hash = hash * a + str.charAt(i);
a = a * b;
}
return hash;
} public long JSHash(String str)
{
long hash = 1315423911;
for(int i = 0; i < str.length(); i++)
{
hash ^= ((hash << 5) + str.charAt(i) + (hash >> 2));
}
return hash;
}
观察上面的这些hash算法我们可以发现,输入都是一些字符串,我们需要对字符串进行操作,并且是对字符串的每一个位置上的字符串进行操作,移位加减乘除,等运算然后得到我们的散列置。在这里我们采用的hash 算法是下面这个: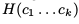
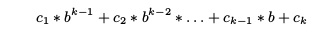
其中H表示的是映射关系,这里操作的对象是我们的每一个shingle,所以C1…CK表示的是一个有K位的元model ,将每一个C按照我们的公式进行计算得到一个hash 值,这里的b 表示的是一个基底(Base) 这里是用户自己设定的某个值,我们一般选取一个质数来做我们的基底,按照上面的公式我们计算得到我们每个 Shingle的hash 值。
哦,对了 http://ytliu.info/blog/2013/12/16/fingerprintsuan-fa-cha-chao-xi/ 这哥们在博客里有几个地方是不准确的。 比如说:

这这这,啥叫K个b位数? b位数是几位呀??还是指的是进制??这个别人完全不懂的话,可能会懵逼。他就是我们在hash算法中设置的一个常量,我们叫Base,论文中也是这么说的,我们用它来做为计算散列值的一个因子,是我们自己设定的,当然一般我们取得是素数。
申明一点:只是为了让技术更美好,生活更美好,没有攻击任何人的意思。网络上中国这方面的资料本来就少,有个人来分享总是好的,我们要做的就是让他更好。哈哈哈哈~~~
有了我们的hash算法,我们就可以计算每一个shingle的hash值。
我们的文档有N,按照k 来划分,得到的shingle 总共是N-K+1个。所以我们要计算N-K+1个长度为K的shingle的hash.
其实计算量还是很大的,不要着急,我们后面会讲怎么改进的,现在先买个关子。
2.特征提取
什么是特征?
应该是能很快区分出你是谁的点,我们把这些你独一无二的东西叫做我们的“特”征。特征一定是能快速标记你是谁的东西。
在软件文本的检测中这个道理同样适用。
一个软件,它总有一些比较有价值的代码,和一些大众代码,我们谁都可以实现的。你有我有大家有的东西,显然不可能做特征。
我们在破案的时候,常常采用指纹,DNA,掌纹,牙齿的结构,等等来确定这个人是谁。我们没有必要比较所有的特征,因为那是没有任何效率的。比个DNA就能搞定的事情,你非要把身上的每一块肥肉都拿来判别一下,这个行为就是来搞笑的。
所以我们没有必要去比较一个文档的所有的shingle的hash值,我们只需要比较一些特定的hash 值,就可以了。这个时候就涉及到特征的提取和选择,到底那些特征是该保留的,那些特征是该舍弃的?
现在我们有一整个文档的hash 值,那有的人就说了,那我们每隔几个选一个hash 值带代替整个文档,让这些哈希值作为我们整个文档的“胎记”birthmark 或者是”指纹”fingerprint 也就是我们的特征。
OK,这个想法却是减小了我们的特征值,但是有效么?
我们思考一下.
随机每隔相通的距离选取一个hash值,这样的做法有什么弊端么?有可能这些哈希值全部都是不重要的信息的hash, 你用这些值根本找不到剽窃样本。
所以某种程度上效果不好。
之后又有人 提出了我们使用
θmodp
= 0 的方法来选择我们的hash 值。这样又使得我们的选择更加的随机。
假设我们有一组hash 值,是这个样子的:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
77 72 42 17 98 50 17 98 8 88 67 39 77 72 42 17 98
那我们选取 mod 4 =0 的哈希那我们就得到了 四个hash值做我们文档的特征值
我们得到的特征值就是:
(1:72), ( 8:8), (9:88) , (13:72)
这个算法比上面的选取固定值又提升了一部,使得选取更加的随机化。但是,有问题么??
假设我们的散列值是下面这个排序:
72 8 88 72 77 42 17 98 50 17 98 67 39 77 42 17 98
那我们去p=4 ,我们取出来的hash值全部都来自头部的hash, 假设这个文章是有很多段组成的,我们这样选取,很可能使得我们的特征分布不均匀。这样我们很可能只提取到了某些段落的特征值,而完全的忽略了某些段落。
要是我们忽略的段落正好是我们抄袭的段落,那么我们很可能就完全检测不到了。所以,你可以看到这个方法的缺点了吧。有时候取余选取的特征值存在分配不均匀的情况。为了改善这个情况,我们就要推出我们今天的主角 winnowing.
3.winnowing 方法
为了使得我们的选取的特征值分布相对来说比较合理一点,这里我们使用了winnowing 的方法。在上面的一个小节中我们已经对这个方法做了一个简单的介绍。
这个方法的基本思想就是,我们首先设置一个大小为W的滑动窗口。将每个窗口中最小的那个hash保留下来(如果窗口中最小的hash 有两个或者多个,就保留最右边的那一个),这样就保证了我们保留下来的文档原文的间隔不会超过 W+K-1.注意,选过的特征是不能在挑选的,我们需要记录下下标。因为hash值是可能重复的。
为什么我们能保证间隔就是 W+K-1?why?
你想过这个问题了没有?
好的我们现在再来解答一下这个问题:
我们的特征值如下:
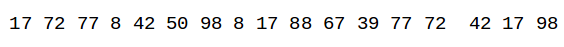
我们假设我们选取的窗口的大小为4:
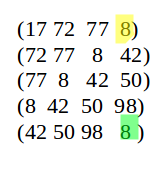
在第一个窗口中我们的最小值是A3:8,以此类推

在第二个窗口中我们的最小值依然是A3:8

在第三个窗口中我们的最小值依然是A3:8

在第四个窗口中我们的最小值依然是A3:8

直到第五个窗口的时候我们才能加入新的特征值

我们可以看到最差的情况就是上面我们说的这情况,其实就是W-1
按照这种方法我们可以选举出我们的所有特征值。
假设我们的hash值的集合是下面这个样子
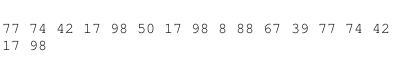
我们设置窗口的大小为4:

我们得到最终的特征值就是下面这个样子:

前面的是特征值,后面的是特征值对应的下标。
好的这章我们就讲到这里。
下次我们在讲代码部分,要是各位看官觉得小的博客讲的还算不错,请打个赏钱呗。
现在是家里唯一劳动力,男丁都已经去世,上有老下有小,一个人要养整个家不容易。希望自己成功的速度比外婆衰老的脚步快一点,他们老人家把这么淘气又喜欢惹事情的我养大十分不容易,如果大家觉得这个博客值,跪求打赏。当然不打同情牌,只用实力吃饭,觉得好的感谢支持,仅此而已。当然,没有钱场跪求给个人场~~~^-^



你必须非常努力,才可以看起来毫不费力
转载自原文链接, 如需删除请联系管理员。
原文链接:基于K-gram的winnowing特征提取剽窃查重检测技术(概念篇),转载请注明来源!