提高处理机指令执行速度,通常有三条途径:提高CPU工作主频,
②采用更好的算法和功能部件。例如采用RISC,改进乘法、除法的算法等;
③采用指令并行技术,这是目前提高处理机性能的主要方法,其基本方法有3个,即流水线技术;超标量超流水线技术以及超长指令字技术
流水线技术
把一个重复的过程分解为若干个子过程,每个子过程由专门的功能部件来实现。
把多个处理过程在时间上错开,依次通过各功能段,这样,每个子过程就可以与其他的子过程并行进行。

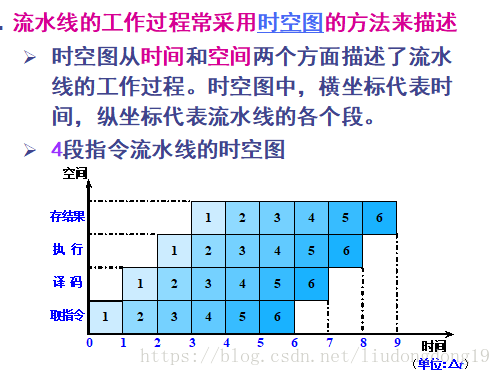
流水线的分类
单功能流水线与多功能流水线
(按照流水线所完成的功能来分类)
单功能流水线:只能完成一种固定功能的流水线。
多功能流水线:流水线的各段可以进行不同的连接,以实现不同的功能。
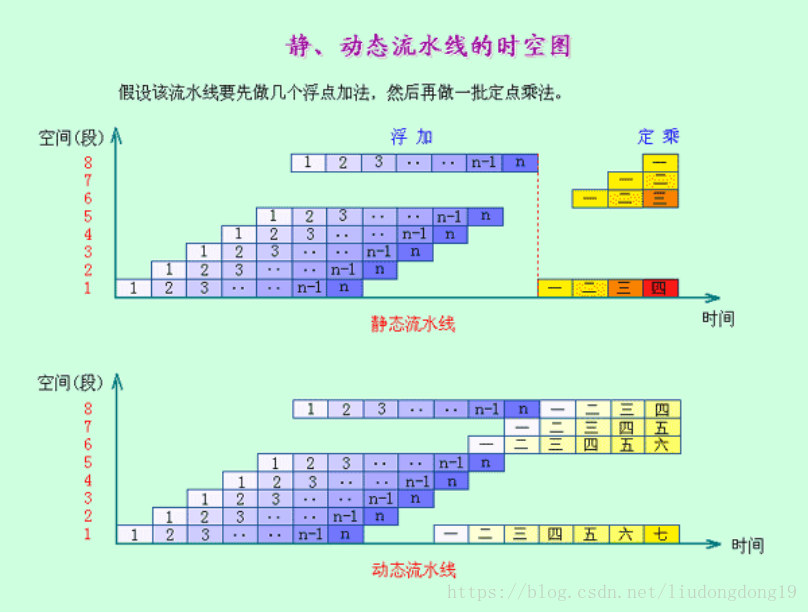
静态流水线与动态流水线
多功能流水线可分为静态流水线(static pipelining )与动态流水线(dynamic pipelining)(按照同一时间内各段之间的连接方式对多功能流水线做进一步的分类)
静态流水线:在同一时间内,多功能流水线中的
各段只能按同一种功能的连接方式工作。
对于静态流水线来说,只有当输入的是一串相同的运算任务时,流水的效率才能得到充分的发挥。例如:ASC的8段流水线
动态流水线:在同一时间内,多功能流水线中的各段可以按照不同的方式连接,同时执行多种功能。
部件级、处理机级及处理机间流水线
(按照流水的级别来进行分类)
部件级流水线(运算操作流水线):把处理机的算术逻辑运算部件分段,使得各种类型的运算操作能够按流水方式进行。
处理机级流水线(指令流水线):把指令的解释执行过程按照流水方式处理。把一条指令的执行过程分解为若干个子过程,每个子过程在独立的功能部件中执行。
处理机间流水线(宏流水线):它是由两个或者两个以上的处理机串行连接起来,对同一数据流进行处理,每个处理机完成整个任务中的一部分。
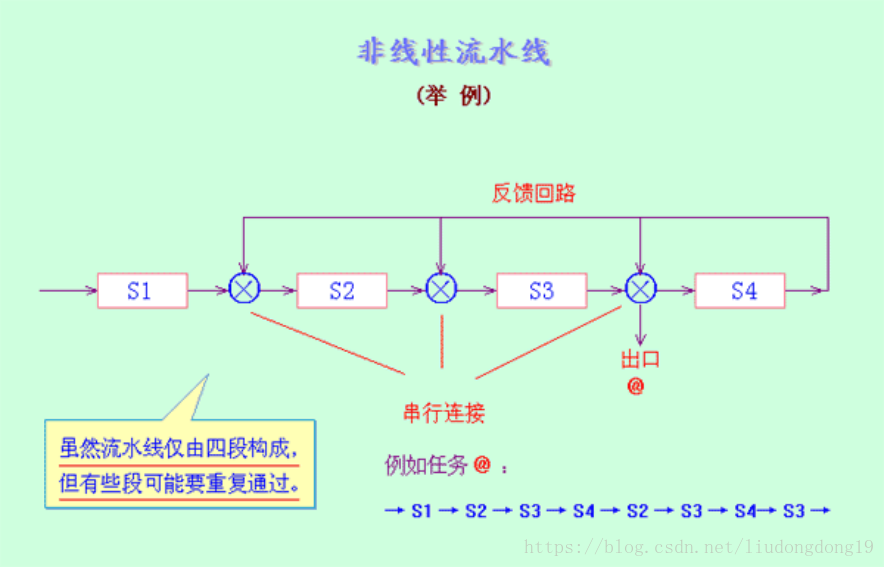
线性流水线与非线性流水线
线性流水线:流水线的各段串行连接,没有反馈回路。数据通过流水线中的各段时,每一个段最多只流过一次。
非线性流水线:流水线中除了有串行的连接外,还有反馈回路。
顺序流水线与乱序流水线
顺序流水线:流水线输出端任务流出的顺序与输
入端任务流入的顺序完全相同。每一个任务在流
水线的各段中是一个跟着一个顺序流动的。
乱序流水线:流水线输出端任务流出的顺序与输
入端任务流入的顺序可以不同,允许后进入流水
线的任务先完成(从输出端流出)。
标量处理机与向量流水处理机
把指令执行部件中采用了流水线的处理机称为流
水线处理机。
标量处理机:处理机不具有向量数据表示和向量
指令,仅对标量数据进行流水处理。
向量流水处理机:具有向量数据表示和向量指令
的处理机。

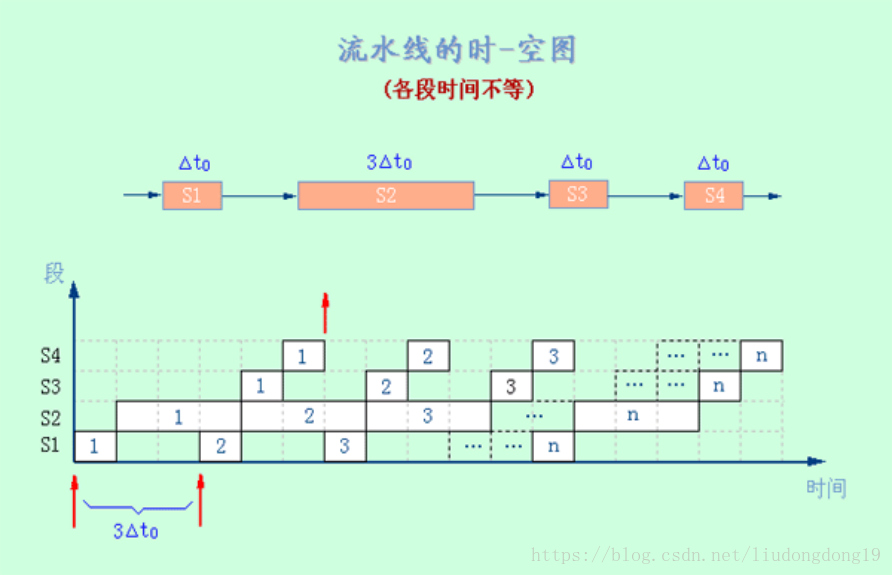
各段时间不完全相等的流水线

解决流水线瓶颈问题的常用方法
细分瓶颈段
例如:对前面的4段流水线,把瓶颈段S3细分为3个子流水线段:S3a,S3b,S3c

重复设置瓶颈段
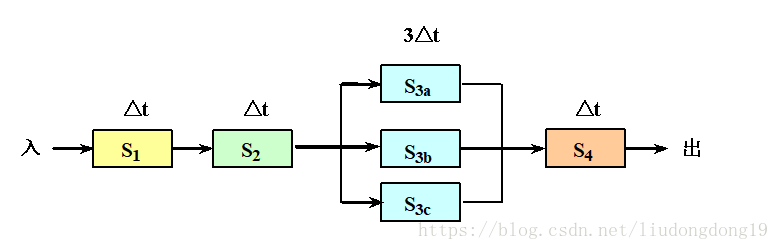
加速比:完成同样一批任务,不使用流水线所用的时间与使用流水线所用的时间之比。
效率:流水线中的设备实际使用时间与整个运行时间
的比值,即流水线设备的利用率。
流水线设计中的若干问题:
瓶颈问题
理想情况下,流水线在工作时,其中的任务是同步地每一个时钟周期往前流动一段。
当流水线各段不均匀时,机器的时钟周期取决于瓶颈段的延迟时间。
在设计流水线时,要尽可能使各段时间相等。
流水线的额外开销
①流水寄存器延迟
流水寄存器需要建立时间和传输延迟
建立时间:在触发写操作的时钟信号到达之前,寄存器输入必须保持稳定的时间。
传输延迟:时钟信号到达后到寄存器输出可用的时间。
②时钟偏移开销: 流水线中,时钟到达各流水寄存器的最大差值时间。(时钟到达各流水寄存器的时间不是完全相同)
冲突问题
相关与流水线冲突
相关:两条指令之间存在某种依赖关系。
如果两条指令相关,则它们就有可能不能在流水线中重叠执行或者只能部分重叠执行。
相关有3种类型
数据相关(也称真数据相关)
名相关
控制相关
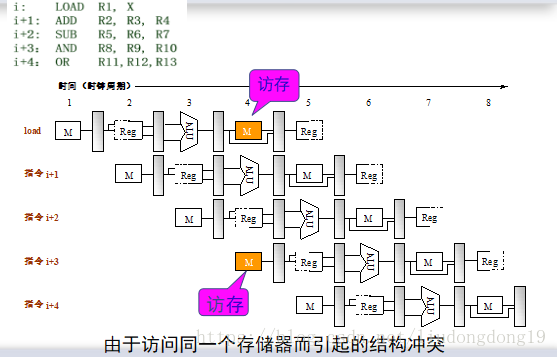
结构冲突:因硬件资源满足不了指令重叠执行的要求而发生的冲突。
插入暂停周期 设置相互独立的指令存储器和数据存储器或设置相互独立的指令Cache和数据Cache。
数据冲突:当指令在流水线中重叠执行时,因需要用到前面指令的执行结果而发生的冲突。
写后读冲突(RAW)写后写冲突(WAW) 读后写冲突(WAR)
采用定向技术; 停顿数据冲突; 依靠编译器。
控制冲突:流水线遇到分支指令和其他会改变PC值的指令所引起的冲突。
处理分支指令最简单的方法:
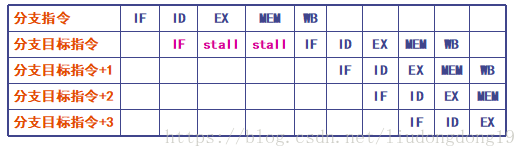
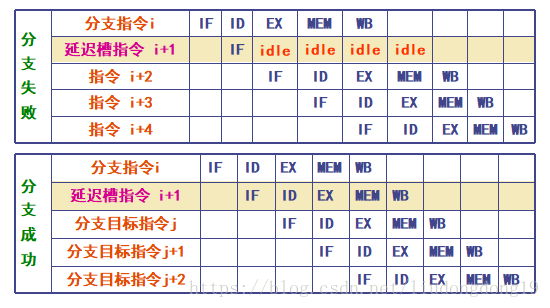
分支延迟:把由分支指令引起的延迟称为分支延迟。
从前调度
从目标处调度
从失败处调度
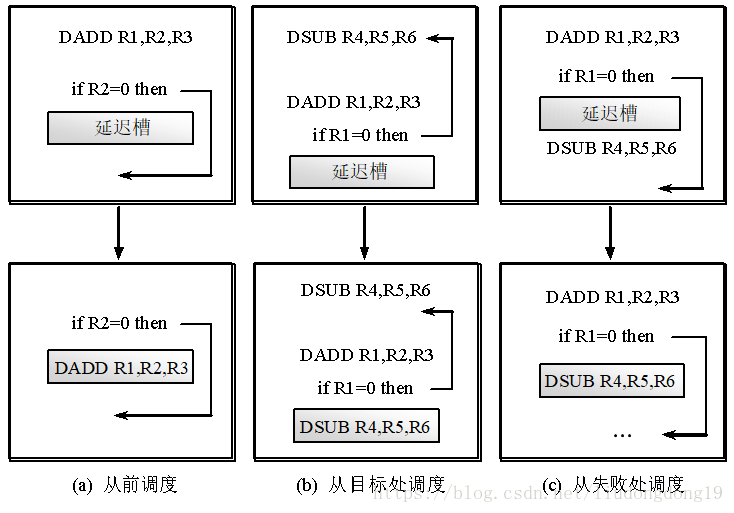
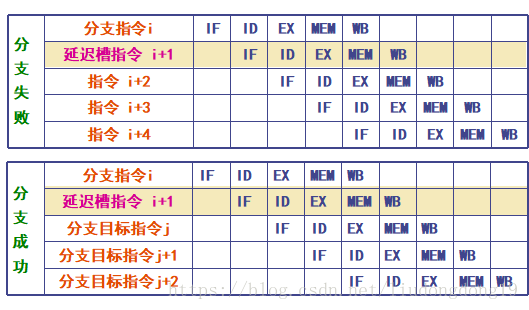
①预测分支失败
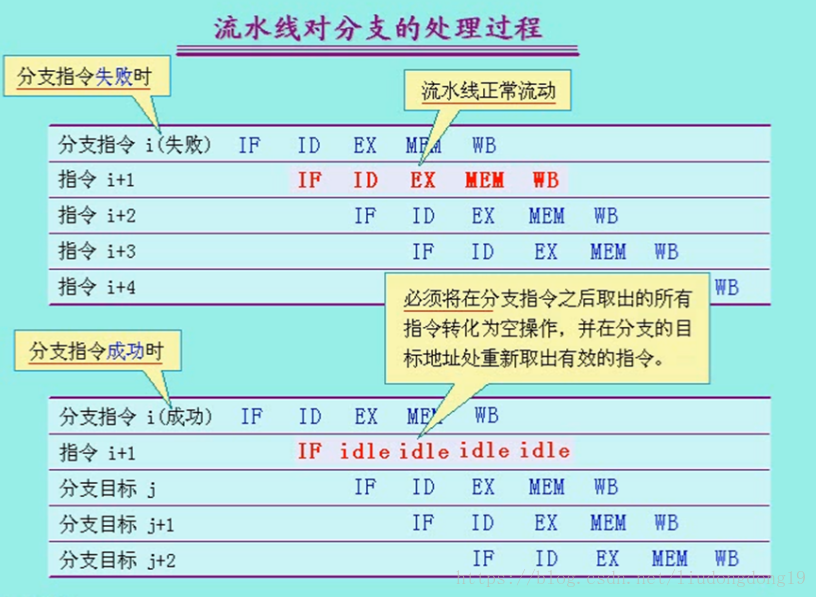
②预测分支成功
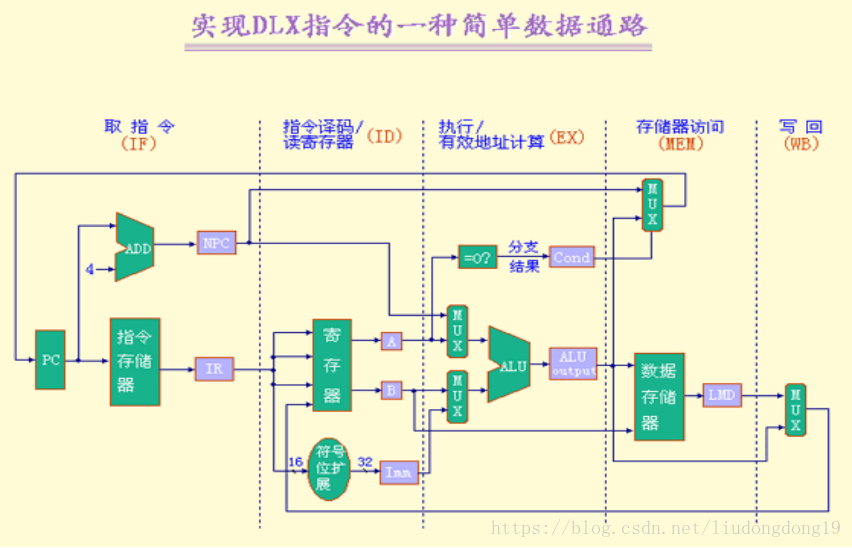

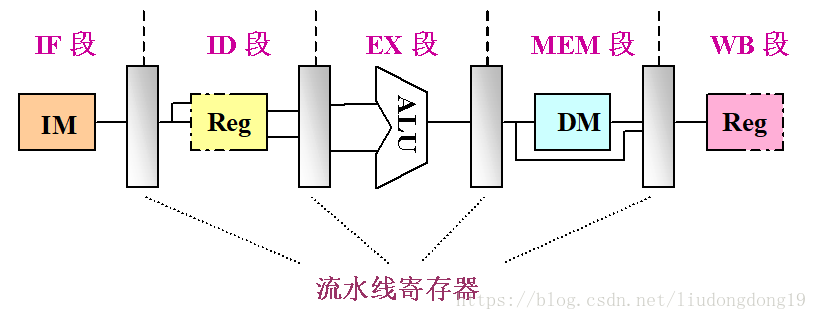
ID/EX.IR:流水寄存器ID/EX中的子寄存器IR
ID/EX.IR[op]:该寄存器的op字段(即操作码字段)
流水寄存器的作用:
将各段的工作隔开,使得它们不会互相干扰。
保存相应段的处理结果。
增加了向后传递IR和从MEM/WB.IR回送到通用寄存器组的连接。
将对PC的修改移到了IF段,以便PC能及时地加
为取下一条指令做好准备。
向量处理机



基本结构
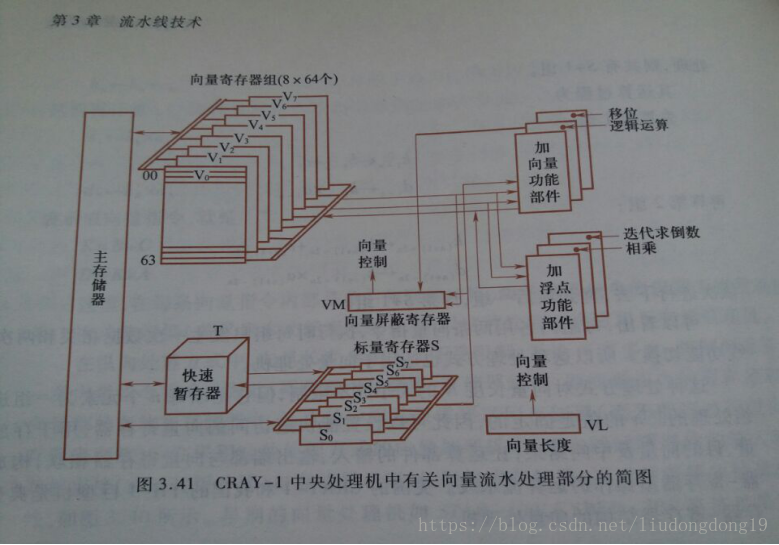
功能部件
共有12条可并行工作的单功能流水线,可分别流水地进行地址、向量、标量的各种运算。
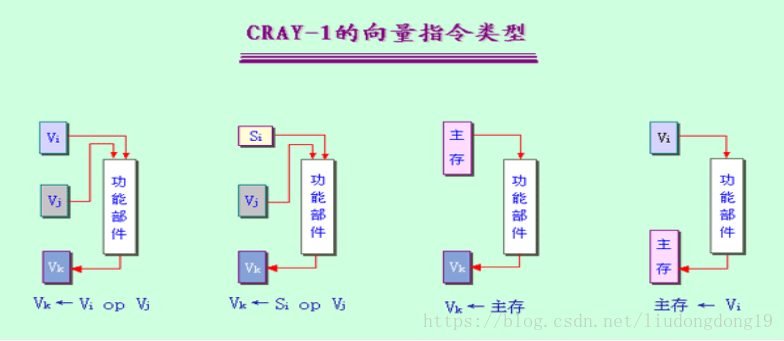
提高向量处理机性能的方法::
设置多个功能部件,使它们并行工作。
采用链接技术,加快一串向量指令的执行。
采用循环开采技术,加快循环的处理。( 如果向量的长度大于向量寄存器的长度,)
采用多处理机系统,进一步提高性能。
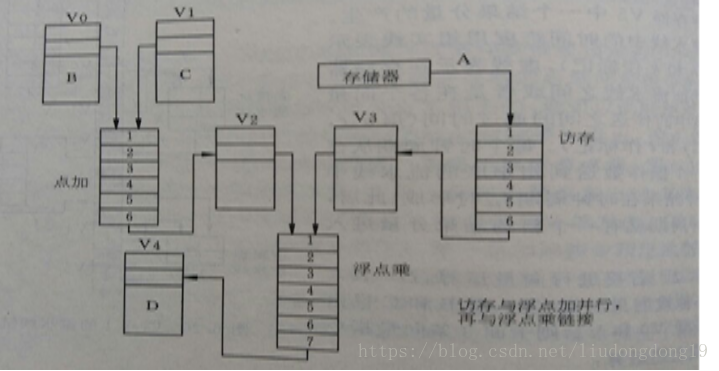
例3.3 在CRAY-1上用链接技术进行向量运算 D=A×(B+C)
假设向量长度N≤64,向量元素为浮点数,且向量B、C已存放在V0和V1中。
画出链接示意图,并分析非链接执行和链接执行两种情况下的执行时间。
解:用以下三条向量完成上述运算:
V3 ← 存储器 // 访存取向量A
V2 ← V0 + V1 // 向量B和向量C进行浮点加
V4 ← V2 × V3 // 浮点乘,结果存入V4
第1、2条指令既无向量寄存器使用冲突,也无功能部件冲突。所以这两条指令可以并行执行。
第3条指令与第1、2条向量指令均存在先写后读冲突,因而第3条指令与第1、2条向量指令链接执行。
假设:把向量数据元素送往向量功能部件以及把结果存入向量寄存器需要一拍时间,从存储器中把数据送入访存功能部件需要一拍时间。
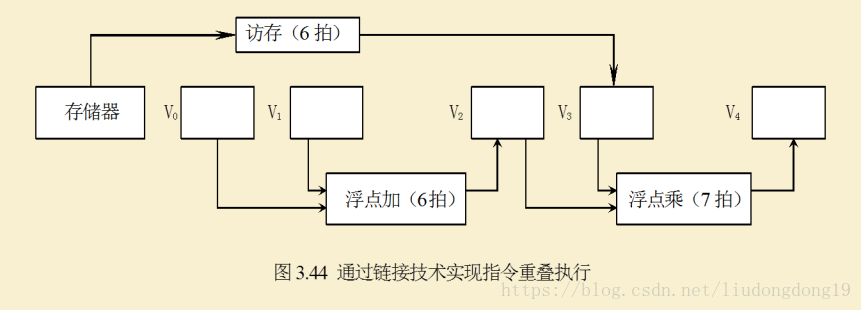
从访存开始到把第一个结果元素存入V4所需的拍数
(亦称为链接流水线的建立时间)为:
[(1+6+1)] +[(1+7+1)] = 17 (拍)
3条指令的执行时间为:
[(1+6+1)]+ [(1+7+1)] +(N-1)
= N+16 (拍)

3条指令全部用串行方法执行,则执行时间为:
[(1+6+1)+N-1]+[(1+6+1)+N-1]
+[(1+7+1)+N-1] = 3N +22 (拍)
前两条指令并行执行,然后再串行执行第3条指令,则执行时间为:
[(1+6+1)+N-1]+[(1+7+1)+N-1]
= 2N +15 (拍)
转载自原文链接, 如需删除请联系管理员。
原文链接:流水线技术,转载请注明来源!