from:https://blog.csdn.net/gavin_john/article/details/51511180
1.XML历史
gml(1969)->sgml(1985)->html(1993)->xml(1998)
- 1969 gml(通用标记语言),主要目的是要在不同的机器之间进行通信的数据规范
- 1985 sgml(标准通用标记语言)
- 1993 html(超文本标记语言,www网)
html语言本身是有一些缺陷的
(1)不能自定义标签
(2)html本身缺少含义
(3)html没有真正的国际化有一个中间过渡语言,xhtml:
html->xhtml->xml
- 1998 xml extensiable markup language 可扩展标记语言
2.为什么需要XML
1.需求1
两个程序间进行数据通信?
2.需求2
给一台服务器,做一个配置文件,当服务器程序启动时,去读取它应当监听的端口号,还有连接数据库的用户名和密码?
在XML语言中,它允许用户自定义标签。一个标签用于描述一段数据;一个标签可以分为开始标签和结束标签,在开始标签和结束标签之间,又可以使用其他标签描述其他数据,以此来实现数据关系的描述。
3.XML常见应用
1.XML的出现解决了程序间数据传输的问题:
比如QQ之间的数据传送,用XML格式来传送数据,具有良好的可读性,可维护性
2.XML可以做配置文件
XML文件做配置文件可以说非常普遍,比如我们的Tomcat服务器的server.xml,web.xml。再比如我们的structs中的structs-config.xml文件,和hibernate的hibernate.cfg.xml等等。
3.XML可以充当小型的数据库
XML文件可以做小型数据库,也是不错的选择,我们程序中可能用到一些经常要人工配置的数据,如果放在数据库中读取不合适(因为这会增加维护数据库的工作),则可以考虑直接用XML来做小型数据库。这种方式直接读取文件显然要比读数据库快。比如msn中保存用户聊天记录就是用XML文件。
入门案例:用XML来记录一个班级信息。
<?xml version="1.0" encoding="gb2312"?>
<class>
<stu id="001">
<name>杨过</name>
<sex>男</sex>
<age>20</age>
</stu>
<stu id="002">
<name>小龙女</name>
<sex>女</sex>
<age>21</age>
</stu>
</class>我们可以用浏览器打开:

那么我们的XML能不能像html那样显示在网页上呢?也是可以的,它也可以用css来修饰,但我们不用,我们只需要使用XML来存储数据。
在这个例子中,如果我们把第一行的编码改为utf-8,再用浏览器打开会报错,这是为什么呢?
因为xml文件的默认编码是ANSI,即美国国家标准协会制定的编码,它根据不同的国家和地区制定了不同的标准,那么在中国就是GB2312,所以我们用GB2312编码不会出错,而用UTF-8会报错。
解决办法就是将该XML文件更改为UTF-8的编码模式即可。
4.XML语法
一个XML文件分为如下几部分内容:
1.文档声明
2.元素
3.属性
4.注释
5.CDATA区、特殊字符
6.处理指令(processing instruction)
4.1.XML语法-文档声明
<?xml version="1.0" encoding="utf-8" standalone="yes" ?>- XML声明放在XML文档的第一行
XML声明由以下几个部分组成:
version –文档符合XML1.0规范,我们学习1.0
encoding –文档字符编码,比如”GB2312”或者”UTF-8”
standalone –文档定义是否独立使用
standalone=”no”为默认值。yes代表是独立使用,而no代表不是独立使用
4.2.XML语法-元素(或者叫标记、节点)
(1)每个XML文档必须有且只有一个根元素
- 根元素是一个完全包括文档中其他所有元素的元素
- 根元素的起始标记要放在所有其他元素的起始标记之前
- 跟元素的结束标记要放在所有其他元素的结束标记之后
(2)XML元素指的是XML文件中出现的标签,一个标签分为开始标签和结束标签,一个标签有如下几种书写方式,例如
- 包含标签体:
<a>www.sohu.com</a>- 不含标签体的:
<a></a>,简写为:<a/>- (3)一个标签中也可以嵌套若干子标签。但所有标签必须合理地嵌套,绝对不允许交叉嵌套,例如
<a>welcome to <b> www.sohu.com </a></b>- 这种情况肯定是要报错的。
(4)对于XML标签中出现的所有空格和换行,XML解析程序都会当做标签内容进行处理。例如下面两段内容的意义是不一样的。
<stu>xiaoming</stu>- 和如下:
<stu>
xiaoming
</stu>(5)由于在XML中,空格和换行都作为原始内容被处理,所以,在编写XML文件时,要特别注意。
(6)命名规范:一个XML元素可以包含字母、数字以及其它一些可见字符,但必须遵守以下规范:
- 区分大小写,例如,元素P和元素p是两个不同的元素
- 不能以数字或下划线”_”开头
- 元素内不能包含空格
- 名称中间不能包含冒号(:)
- 可以使用中文,但一般不这么用
4.3.XML语法-属性
<student id="100">
<name>Tom</name>
</student>(1)属性值用双引号(”)或单引号(’)分隔,如果属性值中有单引号,则用双引号分隔;如果有双引号,则用单引号分隔。那么如果属性值中既有单引号还有双引号怎么办?这种要使用实体(转义字符,类似于html中的空格符),XML有5个预定义的实体字符,如下:

(2)一个元素可以有多个属性,它的基本格式为:
<元素名 属性名1="属性值1" 属性名2="属性值2">- (3)特定的属性名称在同一个元素标记中只能出现一次
(4)属性值不能包括<,>,&,如果一定要包含,也要使用实体
4.4.XML语法-注释
XML的注释类似于HTML中的注释:
<!--这是一个注释-->- (1)注释内容不要出现
--
(2)不要把注释放在标记中间;
(3)注释不能嵌套
(4)可以在除标记以外的任何地方放注释
4.5.XML语法-CDATA节
假如有这么一个需求,需要通过XML文件传递一幅图片,怎么做呢?其实我们看到的电脑上的所有文件,本质上都是字符串,不过它们都是特殊的二进制字符串。我们可以通过XML文件将一幅图片的二进制字符串传递过去,然后再解析成一幅图片。那么这个字符串就会包含大量的<,>,&或者“等一些特殊的不合法的字符。这时候解析引擎是会报错的。
所以,有些内容可能不想让解析引擎解析执行,而是当做原始内容处理,用于把整段文本解释为纯字符数据而不是标记。这就要用到CDATA节。
语法如下:
<![CDATA[
......
]]>CDATA节中可以输入任意字符(除]]>外),但是不能嵌套!
如下例,这种情况它不会报错,而如果不包含在CDATA节中,就会报错:
<stu id="001">
<name>杨过</name>
<sex>男</sex>
<age>20</age>
<intro><![CDATA[ad<<&$^#*k]]></intro>
</stu>.6.XML语法-处理指令
处理指令,简称PI(processing instruction)。处理指令用来指示解析引擎如何解析XML文件,看下面一个例子:
比如我们也可以使用css样式表来修饰XML文件,编写my.css如下:
name{
font-size:80px;
font-weight:bold;
color:red;
}
sex{
font-size:60px;
font-weight:bold;
color:blue;
}
sex{
font-size:40px;
font-weight:bold;
color:green;
}我们在xml文件中使用处理指令引入这个css文件,如下:
<?xml version="1.0" encoding="gb2312"?>
<?xml-stylesheet href="my.css" type="text/css"?>
<class>
<stu id="001">
<name>杨过</name>
<sex>男</sex>
<age>20</age>
</stu>
<stu id="002">
<name>小龙女</name>
<sex>女</sex>
<age>21</age>
</stu>
</class>这时候我们再用浏览器打开这个xml文件,会发现浏览器解析出一个带样式的视图,而不再是单纯的目录树了:
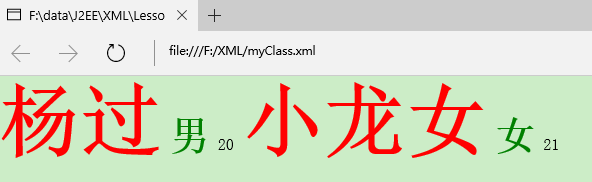
但是XML的处理指令不要求掌握,因为用到的很少。
5.格式正规的XML文档-小结
语法规范:
1.XML声明语句
2.必须有一个根元素
3.标记大小写敏感
4.属性值用引号
5.标记成对
6.空标记关闭
7.元素正确嵌套
from:https://blog.csdn.net/qq_38254978/article/details/77870598
什么是xml文件格式
- 我们要给对方传输一段数据,数据内容是“too young,too simple,sometimes naive”,要将这段话按照属性拆分为三个数据的话,就是,年龄too young,阅历too simple,结果sometimes naive。我们都知道程序不像人,可以体会字面意思,并自动拆分出数据,因此,我们需要帮助程序做拆分,因此出现了各种各样的数据格式以及拆分方式。比如,可以是这样的数据为“too young,too simple,sometimes naive”然后按照逗号拆分,第一部分为年龄,第二部分为阅历,第三部分为结果。
- 也可以是这样的数据为“too_young* too_simple*sometimes_naive”从数据开头开始截取前面十一个字符,去掉号并把下划线替换为空格作为第一部分,再截取接下来的十一个字符同样去掉并替换下划线为空格作为第二部分,最后把剩下的字符同样去号体会空格作为第三部分。
- 这两种方式都可以用来容纳数据并能够被解析,但是不直观,通用性也不好,而且如果出现超过限定字数的字符串就容纳不了,也可能出现数据本身就下划线字符导致需要做转义。基于这种情况,出现了xml这种数据格式, 上面的数据用XML表示的话可以是这样
<person age="too young" experience="too simple" result="sometimes naive" />也可以是这样
<person>
<age value="too young" />
<experience value="too simple" />
<result value="sometimes naive" />
</person>两种方式都是xml,都很直观,附带了对数据的说明,并且具备通用的格式规范可以让程序做解析。如果用json格式来表示的话,就是下面这样看出来没,其实数据都是一样的,不同的只是数据的格式而已,同样的数据,我用xml格式传给你,你用xml格式解析出三个数据,用json格式传给你,你就用json格式解析出三个数据,还可以我本地保存的是xml格式的数据,我自己先解析出三个数据,然后构造成json格式传给你,你解析json格式,获得三个数据,再自己构造成xml格式保存起来,说白了,不管是xml还是json,都只是包装数据的不同格式而已,重要的是其中含有的数据,而不是包装的格式。
XML文件创建格式
- 例:
<?xml version="1.0" encoding="utf-8" ?>
<root>
<part id = "01" name="选项一">
<name>我是徐茅山</name>
<age>今年20岁</age>
<sex>男</sex>
</part>
<part id="02" name="选项二">
<name>我是李逍遥</name>
<age>今年22岁</age>
<sex>男</sex>
</part>
</root>- 开始的
xml文件的解析
- 这里只是简单的提一下关于xml文件的解析,我使用的是比较流行的dom4j解析,[dom4j的文件下载地址](“https://dom4j.github.io/“)
- 实例:
package com.xinsi.qi.utils;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
public class Dom4jXml {
public void test(){
try {
File inputFile = new File("F:\\J2EE学习资料\\demoLes03\\web\\WEB-INF\\test.xml");
SAXReader reader = new SAXReader();
Document document = reader.read(inputFile);
System.out.println("Root element :"+document.getRootElement().getName());
Element classElement = document.getRootElement();
List<Node> nodes = document.selectNodes("/class/part[@id='02']");
System.out.println("--------------------");
for (Node node:nodes){
System.out.println("标签名=:"+node.getName());
System.out.println("姓名:"+node.selectSingleNode("name").getText());
System.out.println("年龄:"+node.selectSingleNode("age").getText());
System.out.println("性别:"+node.selectSingleNode("sex").getText());
}
} catch (Exception e1) {
e1.printStackTrace();
}
}
}- 首先创建一个xml文件,这里使用的xml文件就是上面的xml例子,使用dom4j,先创建文件,将文件引入。
File inputFile = new File("F:\\J2EE学习资料\\demoLes03\\web\\WEB-INF\\test.xml");- 再创建dom4j的读取文件类,来读取xml文件
SAXReader reader = new SAXReader();- Document是获取根元素类,控制台输出时,如下
System.out.println("Root element :"+document.getRootElement().getName());
输出Root element :root,该文件的根元素名称为rootElement类是获取根元素内的元素
- List nodes = document.selectNodes(“/class/part[@id=’02’]”) 这段代码的意思是,定位到该元素属性的位置,使用该方法还需要下载,jaxen.jar包,jaxen的下载地址
- @id=’02’的意思是定位到id为02的元素属性,以遍历的形式输出出来。
for (Node node:nodes){
System.out.println("标签名=:"+node.getName());
System.out.println("姓名:"+node.selectSingleNode("name").getText());
System.out.println("年龄:"+node.selectSingleNode("age").getText());
System.out.println("性别:"+node.selectSingleNode("sex").getText());
}- 最终控制台的输出结果为:
标签名=:part
姓名:我是李逍遥
年龄:今年22岁
性别:男转载自原文链接, 如需删除请联系管理员。
原文链接:XML——XML介绍和基本语法,转载请注明来源!