最近尝试将百度的图片爬取下来,下面讲解下我的整个爬取思路的流程。首先打开百度图片首页,输入搜索图片的关键字,浏览器就展示给我们许多的指定图片。

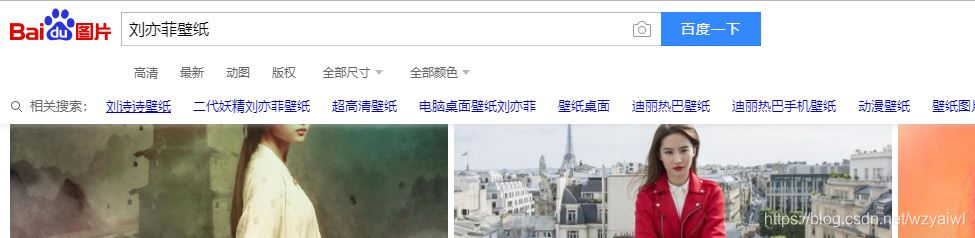
我们知道,爬取图片的核心在于获取到对应图片的url。我一如往常般的打开网页源代码,F12审查元素来获取指定图片在源代码的位置。可是发现源代码里根本就找不到。

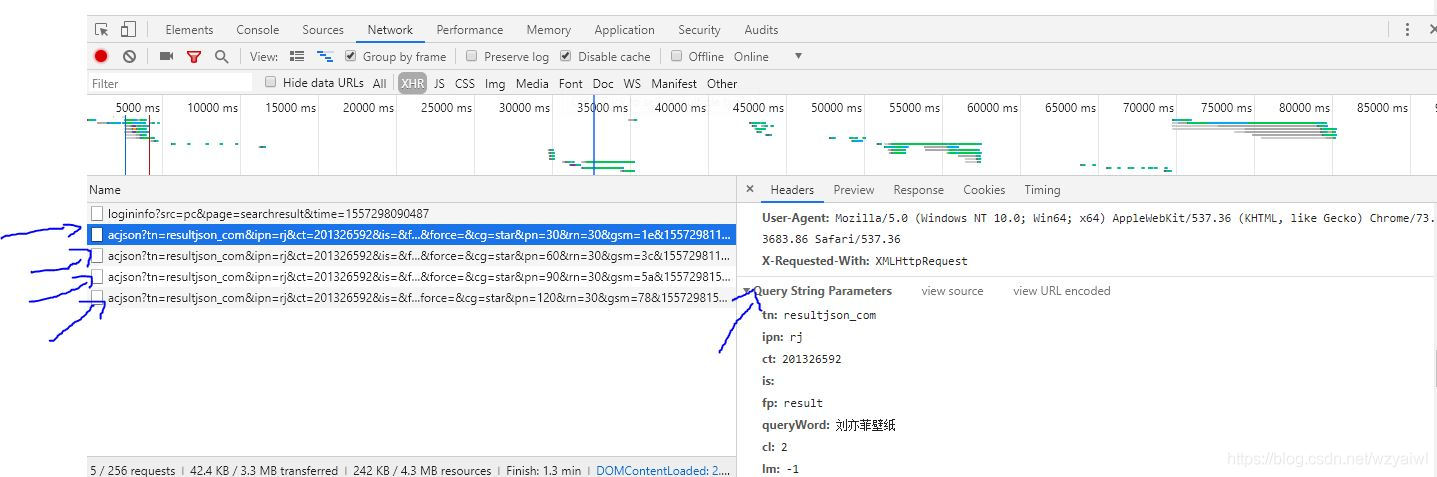
这个时候我就想到,这应该是通过js请求来获取到图片的。所以我下一个目标就是找到js请求的url及其所带的参数。为了方便省时,我并没有使用Fidder来分析,而是直接F12中的network中来查看。果不其然,成功找到了请求图片的url。如下图所示,随着你的鼠标向下滚动,js会不停请求,依此获得更多的图片。每个url请求的参数都可在Query String Parameters中查看。
通过观察我们可以发现以下几点:
- 每一次请求的url参数,几乎都一样,只有一个参数是不同的,那就是pn,他指的是当前页面中已经展示的图片数目。
- url参数的queryWord、word是搜索的关键字,对于不同关键字的搜索,这两个参数是不同的。
- url参数rn指的是每次获取图片的数量,可以发现,一次请求的返回图片数量是30.
- url的协议、ip、端口、目录成分为:https://image.baidu.com/search/acjson

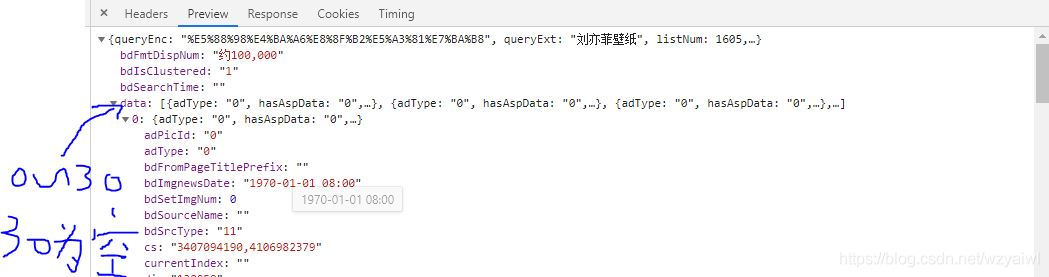
得到每一次的请求,我们的下一个目标就是得到每一次请求返回的30个图片的url。所以我们需要对请求的响应进行分析。可以发现它是以json的数据返回的。返回的内容最外面是一对{},我们所要的信息在key为data中。data的值是一个大小为31的数组,其中最后一个元素是一个空字典。data的每一个元素又是一个字典,而我们需要的图片url就在key为thumbURL内。如下图所示:
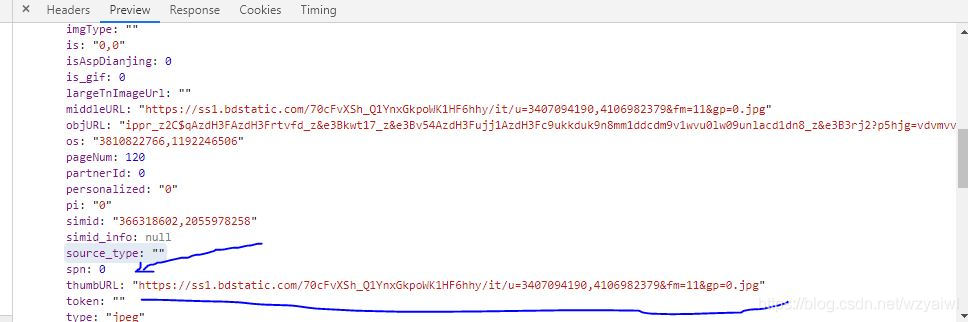
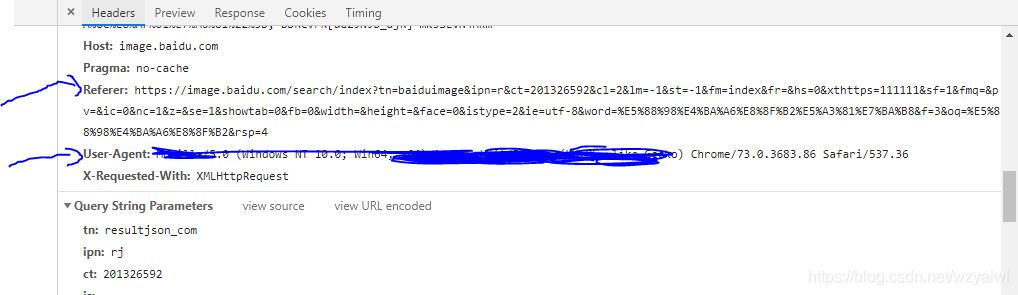
获取到图片url,这时我们就可以请求获取图片了。即requests.get(url,headers=headers).content,再将得到的图片写进文件。这里要注意的是,图片请求的请求头中一定要携带User-Agent和Referer,否则会被返回403.
附带demo
import requests
import os
import urllib
class Spider_baidu_image():
def __init__(self):
self.url = 'http://image.baidu.com/search/acjson?'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.\
3497.81 Safari/537.36'}
self.headers_image = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.\
3497.81 Safari/537.36','Referer':'http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1557124645631_R&pv=&ic=&nc=1&z=&hd=1&latest=0©right=0&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E8%83%A1%E6%AD%8C'}
# self.keyword = '刘亦菲壁纸'
self.keyword = input("请输入搜索图片关键字:")
self.paginator = int(input("请输入搜索页数,每页30张图片:"))
# self.paginator = 50
# print(type(self.keyword),self.paginator)
# exit()
def get_param(self):
"""
获取url请求的参数,存入列表并返回
:return:
"""
keyword = urllib.parse.quote(self.keyword)
params = []
for i in range(1,self.paginator+1):
params.append('tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=1&latest=0©right=0&word={}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&cg=star&pn={}&rn=30&gsm=78&1557125391211='.format(keyword,keyword,30*i))
return params
def get_urls(self,params):
"""
由url参数返回各个url拼接后的响应,存入列表并返回
:return:
"""
urls = []
for i in params:
urls.append(self.url+i)
return urls
def get_image_url(self,urls):
image_url = []
for url in urls:
json_data = requests.get(url,headers = self.headers).json()
json_data = json_data.get('data')
for i in json_data:
if i:
image_url.append(i.get('thumbURL'))
return image_url
def get_image(self,image_url):
"""
根据图片url,在本地目录下新建一个以搜索关键字命名的文件夹,然后将每一个图片存入。
:param image_url:
:return:
"""
cwd = os.getcwd()
file_name = os.path.join(cwd,self.keyword)
if not os.path.exists(self.keyword):
os.mkdir(file_name)
for index,url in enumerate(image_url,start=1):
with open(file_name+'\\{}.jpg'.format(index),'wb') as f:
f.write(requests.get(url,headers = self.headers_image).content)
if index != 0 and index % 30 == 0:
print('{}第{}页下载完成'.format(self.keyword,index/30))
def __call__(self, *args, **kwargs):
params = self.get_param()
urls = self.get_urls(params)
image_url = self.get_image_url(urls)
self.get_image(image_url)
if __name__ == '__main__':
spider = Spider_baidu_image()
spider()
转载自原文链接, 如需删除请联系管理员。
原文链接:爬取百度图片——详细思路,转载请注明来源!