Flume概述:
Apache Flume是一个分布式的、可靠的、可用的系统,用于有效地收集、
聚合和将大量日志数据从许多不同的源移动到一个集中的数据存储。
Apache Flume的使用不仅仅局限于日志数据聚合。由于数据源是可定制的,
Flume可以用于传输大量事件数据,包括但不限于网络流量数据、
社交媒体生成的数据、电子邮件消息和几乎所有可能的数据源。
=================================================================
flume的优点:
1.可以和任意集中式存储进行集成(HDFS,HBASE)
2.输入的数据速率大于写入存储目的地速率,flume会进行缓冲
3.flume提供上下文路由(数据流路线)
4.flume中的事物基于channel,使用了两个事物模型(sender+receiver)
确保消息被可靠发送
5.flume是 可靠的,容错的,可扩展的,。
flume特点
----------------------------------------
1.flume高效收集web server的log到HDFS HBASE)
2.高校获取数据到hadoop
3.导入大量数据
4.flume支持大量的source和destination类型
5.flume支持多级跳跃,source和destination的扇入和扇出
6.flume可以水平伸缩
为什么用flume而不用hdfs的put
------------------------------------------
1.同一时刻只能传输一个文件
2.put处理的是静态文件
架构-组件-配置说明

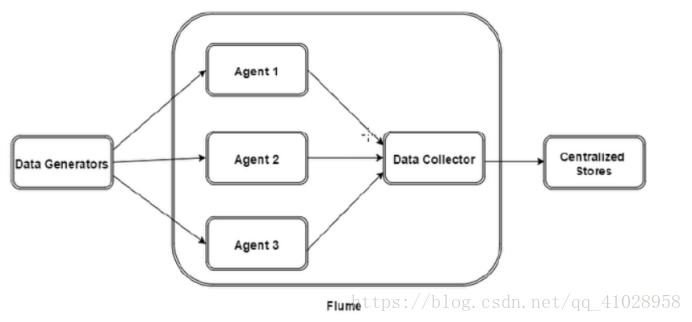
Flume架构:
1. 描述
在数据生成器运行的节点上启动单独的flume agent。来收集数据
数据收集器收集数据,推送到HDFS,HBASE
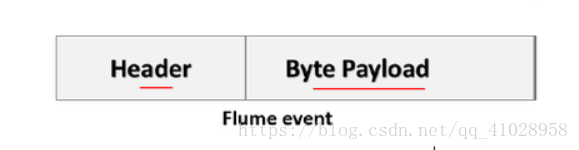
2. Flume Event
事件是flume的传输单元,主要是byte[],可以含有一些header信息
在source和destination之间
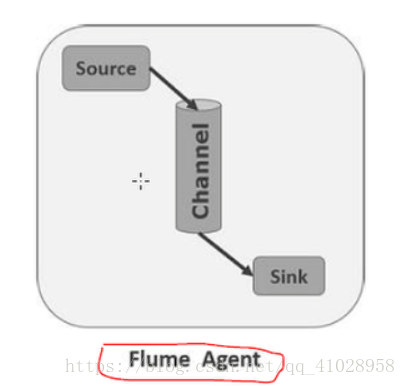
3. Flume agent
每个agent是一个独立的Java进程,从客户端(其他agent)接收数据
然后转发到下一个destination(sink(沉槽) | agent)
Agent包含三个组件:
A. Source(源)->生成数据的地方
从事件生成器接收数据,以event事件的形式传给一个或多个channel
B. Channel(通道)
从source中接受flume event,作为临时存放地,缓存到buffer中,直到sink
将其消费掉,是source和sink之间的桥梁
Channel是事务的,可以和多个source或sink协同
C.sink(沉槽)
存放数据到HDFS,从channel中消费event,并分发给destination,sink的
Destination 也可以是另一个agent或者HDFS,HBASE
注意:一个flume的agent,可以有多个source,channel,sink
Flume的附加组件
1. 拦截器
2. 通道选择器
3. Sink处理器
安装flumn-1.6.0
------------------------
1.下载flume-
2.tar ln -s apahe-flume-1.6.-bin flume
3.配置环境变量
export FLUMN_HOME=/usr/local/soft/flume-1.6.0
export PATH=$PATH:$FLUMN_HOME/bin
4.验证安装
[hadoop@master conf]$ flume-ng version
5.配置flume
flume-env.sh
export JAVA_HOME=/usr/local/soft/jdk1.8.0
配置Flume
1.命名agent组件
2.描述配置source
3.描述配置channel
4.描述配置sink
5.绑定source,sink,到channel
agent_name)
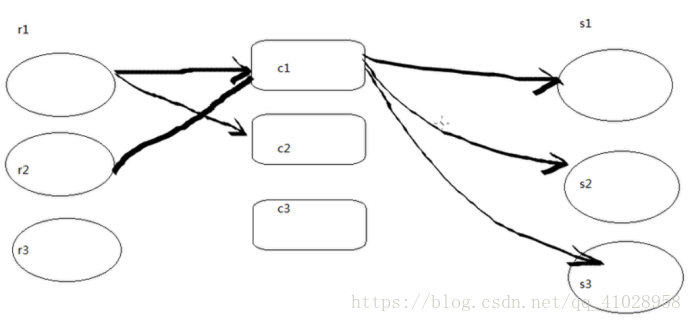
a1.sources=r1,r2
a1.sinks=s1,s2
a1.channels=c1,c2
#sources-r1
a1.sources.r1.type=
a1.sources.r1.xxx=
a1.sources.r1.yyy=
#sink-s1
a1.source.r1.type=
a1.sources.r1.xxx=
#channels-c1
a1.channels.c1.type=
a1.channels.c1.xxx=
#binding(绑定)一个source可以配置多个channel
a1.sources.r1.channels=c1 (可以配多个通道)
a1.sinks.s1.channel=c1 (sink只能配置一个channel)
Flume核心类考察
Simple案例
flume-conf.properties:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind =localhost //0.0.0.0 (统配到本机的所有ip上面去)
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger -->通过控制台或者文件可以控制输出
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
运行flume agent
#--conf :配置目录
#--conf-file :配置文件
#--name :代理名称
#-D :指定额外的参数
$>cd flume/conf
$>flume-ng agent --conf .--conf-file flume-conf.properties --name a1 -Dflume.root.logger=INFO,console
flume-ng agent --conf . --conf-file flume-conf.properties --name a1 -Dflume.root.logger=INFO,console(控制台)
打开另一个终端:
[hadoop@master ~]$ nc localhost 44444
helloworld
OK
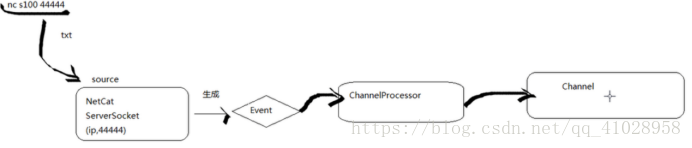
核心类考察
1. Source
生成Event,调用ChannelProcessor的方法,将Event put到Channel中去
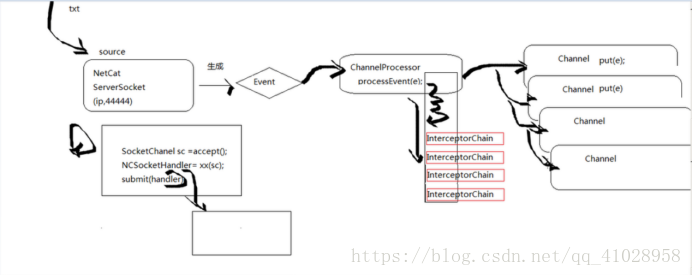
2.Sink
连接到Channel,消费里面的Event,将其发送到destination,有很多相应的sink类型你
Sink可以根据Sinkgroup和Sinkprocessor进行分组
Sink的process()方法只能有一个线程访问
SetChannel() getCannel() process()
3.Channel
连接Source(Event Procuder)和Sink(Event Consumer),本质上Channel就是Buffer
支持事务处理,保证原子性(Put+take)
Channel是线程安全的
Put() take() getTransaction()
转载自原文链接, 如需删除请联系管理员。
原文链接:Flume的简单介绍,转载请注明来源!