HEVC中在进行运动补偿时只考虑了平移运动,而在真实世界里存在各种运动,例如缩放、旋转、头上运动和其他不规则运动。在VTM5中提出了基于块的仿射变换运动补偿预测。如下图所示,一个块的仿射运动向量由两个控制点(4个参数)或三个控制点(6个参数)生成。


基于块的仿射运动补偿方式如下:
1.首先将块划分为4x4的亮度子块。
2.对每个亮度子块按下式由仿射向量计算其中心像素的运动向量,然后四舍五入到1/16精度。
对于4参数仿射运动模型,中心像素为(x,y)的子块的运动向量计算如下:
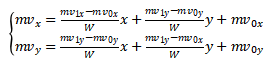
对于6参数仿射运动模型,中心像素为(x,y)的子块的运动向量计算如下:
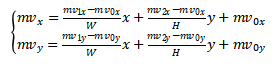
其中(mv0x,mv0y),(mv1x,mv1y),(mv2x,mv2y)分别是左上角、右上角和左下角的控制点的运动向量。
3.每个子块计算出运动向量后(如下图),根据运动向量进行运动补偿插值滤波得到每个子块的预测值。
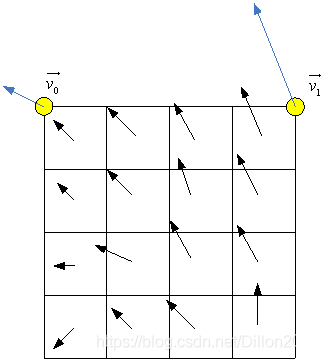
4.对于色度分量同样是划分为4x4的子块,其运动向量等于与其相关的4个4x4的亮度子块运动向量的平均值。
和传统的帧间运动向量预测方式一样,仿射运动向量也有两种预测方式:仿射merge模式、仿射AMVP模式
仿射merge预测(affine merge prediction)
对于宽和高都大于等于8的CU可以使用AF_MERGE模式。在这种模式下当前CU的控制点运动向量(CPMV,control point motion vector)由其空域相邻的CU的运动信息生成。至多生成5个CPMV的预测候选项,且需要传输一个索引表示最终使用了哪个候选项。由下面3种CPMV候选项生成affine merge list:
1.继承其邻居CU的CPMV候选项。
2.由邻居CU的平移运动的MV构建CPMV。
3.0向量。
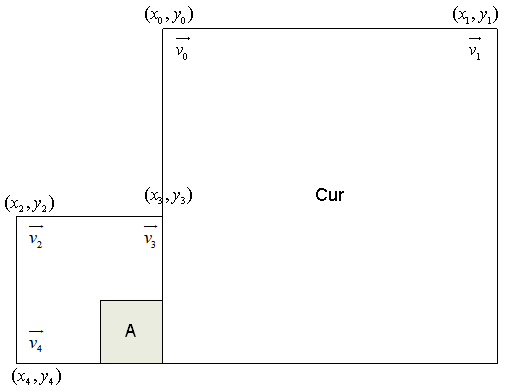
在VTM5中最多有两个类型1的候选项,一个继承自左边邻居CU,另一个继承自上边邻居CU。如下图所示,对于左侧CU扫描顺序是A0->A1,对于上方CU扫描顺序是B0->B1->B2。对于左侧和上方分别只继承扫描顺序中第一个有效的CU。继承的两个候选项间不进行剪枝操作。
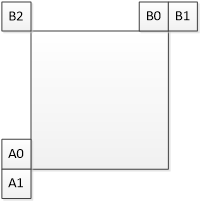
当邻近CU被选定,该邻近CU的CPMV就用来生成当前CU的affine merge list里的候选项。如下图所示,如果左下角的A块被选中,当A是4参数仿射运动模型时,当前CU的两个CPMV根据v2,v3计算得到,当A是6参数仿射运动模型时,当前CU的三个CPMV根据v2,v3,v4计算得到。
对于类型2的候选项,其每个控制点是由特定的空域邻居和时域邻居生成,如下图所示。CPMVk(k=1,2,3,4)表示第k个控制点。对于CPMV1,由B2->B3->A2中第一个有效的块的MV生成。对于CPMV2,由B1->B0中第一个有效的块的MV生成。对于CPMV3,由A1->A0中第一个有效的块的MV生成。如果存在CPVM4的话,由TMVP生成。
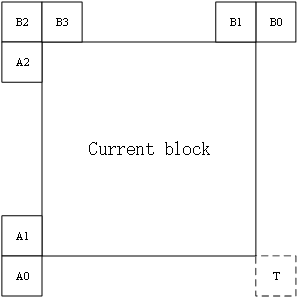
当4个控制点的MV得到后,affine merge的候选项基于这些运动信息构建。下面控制点MV的组合用于构建候选项:
{CPMV1, CPMV2, CPMV3}, {CPMV1, CPMV2, CPMV4}, {CPMV1, CPMV3, CPMV4}, {CPMV2, CPMV3, CPMV4}, { CPMV1, CPMV2}, { CPMV1, CPMV3}
其中3个CPMV的组合构建6参数affine merge候选项,2个CPMV的组合用于构建4参数affine merge候选项。为了避免进行缩放计算,如果控制点的参考图像不同则相关组合被丢弃。
如果类型1和类型2的候选项没有填满affine merge list,则用0向量填充。
仿射AMVP预测(affine AMVP prediction)
对于宽和高都大于等于16的CU可以使用仿射AMVP模式。在merge模式中直接使用预测CPMV,而在AMVP中需要传输的是当前CU的最优CPMV和预测CPMV的残差。affine AVMP candidate list有2个候选项,由下面4类CPMV候选项生成:
1.继承其邻居CU的CPMV候选项。
2.由邻居CU的平移运动的MV构建CPMV。
3.来自邻居CU的平移运动MV。
4.0向量。
类型1的affine AMVP候选项构建和affine merge一样。唯一不同是邻居CU的参考图像和当前CU必须一样。
类型2的affine AMVP候选项构建和affine merge一样。除此之外,邻居块的参考图像索引也要检查,要选择扫描顺序中第一个帧间编码且和当前CU有相同参考图像的块。当当前CU是4参数仿射模型且mv0和mv1都有效时,将它们加入affine AMVP list。当当前CU是6参数仿射模型且3个CPMV都有效时,将它们加入affine AMVP list。否则类型2的候选项无效。
如果类型1和类型2加入之后affine AMVP list中的候选项还是少于2,则按序加入mv0,mv1,mv2用平移运动MV预测当前CU所有控制点的MV。最后如果list还没满则用0向量填充。
在VTM5的定义里affine AMVP有3个候选项如下:
struct AffineAMVPInfo
{
Mv mvCandLT[ AMVP_MAX_NUM_CANDS_MEM ]; ///< array of affine motion vector predictor candidates for left-top corner
Mv mvCandRT[ AMVP_MAX_NUM_CANDS_MEM ]; ///< array of affine motion vector predictor candidates for right-top corner
Mv mvCandLB[ AMVP_MAX_NUM_CANDS_MEM ]; ///< array of affine motion vector predictor candidates for left-bottom corner
unsigned numCand; ///< number of motion vector predictor candidates
};以下是affine AMVP list构建的代码:
void PU::fillAffineMvpCand(PredictionUnit &pu, const RefPicList &eRefPicList, const int &refIdx, AffineAMVPInfo &affiAMVPInfo)
{
affiAMVPInfo.numCand = 0;
if (refIdx < 0)
{
return;
}
//!<继承其邻居CU的CPMV候选项
// insert inherited affine candidates
Mv outputAffineMv[3];
Position posLT = pu.Y().topLeft();
Position posRT = pu.Y().topRight();
Position posLB = pu.Y().bottomLeft();
// check left neighbor
if ( !addAffineMVPCandUnscaled( pu, eRefPicList, refIdx, posLB, MD_BELOW_LEFT, affiAMVPInfo ) )
{
addAffineMVPCandUnscaled( pu, eRefPicList, refIdx, posLB, MD_LEFT, affiAMVPInfo );
}
// check above neighbor
if ( !addAffineMVPCandUnscaled( pu, eRefPicList, refIdx, posRT, MD_ABOVE_RIGHT, affiAMVPInfo ) )
{
if ( !addAffineMVPCandUnscaled( pu, eRefPicList, refIdx, posRT, MD_ABOVE, affiAMVPInfo ) )
{
addAffineMVPCandUnscaled( pu, eRefPicList, refIdx, posLT, MD_ABOVE_LEFT, affiAMVPInfo );
}
}
if ( affiAMVPInfo.numCand >= AMVP_MAX_NUM_CANDS )
{
for (int i = 0; i < affiAMVPInfo.numCand; i++)
{
affiAMVPInfo.mvCandLT[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
affiAMVPInfo.mvCandRT[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
affiAMVPInfo.mvCandLB[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
}
return;
}
//!<由邻居CU的平移运动的MV构建CPMV
// insert constructed affine candidates
int cornerMVPattern = 0;
//------------------- V0 (START) -------------------//
AMVPInfo amvpInfo0;
amvpInfo0.numCand = 0;
// A->C: Above Left, Above, Left
addMVPCandUnscaled( pu, eRefPicList, refIdx, posLT, MD_ABOVE_LEFT, amvpInfo0 );
if ( amvpInfo0.numCand < 1 )
{
addMVPCandUnscaled( pu, eRefPicList, refIdx, posLT, MD_ABOVE, amvpInfo0 );
}
if ( amvpInfo0.numCand < 1 )
{
addMVPCandUnscaled( pu, eRefPicList, refIdx, posLT, MD_LEFT, amvpInfo0 );
}
cornerMVPattern = cornerMVPattern | amvpInfo0.numCand;
//------------------- V1 (START) -------------------//
AMVPInfo amvpInfo1;
amvpInfo1.numCand = 0;
// D->E: Above, Above Right
addMVPCandUnscaled( pu, eRefPicList, refIdx, posRT, MD_ABOVE, amvpInfo1 );
if ( amvpInfo1.numCand < 1 )
{
addMVPCandUnscaled( pu, eRefPicList, refIdx, posRT, MD_ABOVE_RIGHT, amvpInfo1 );
}
cornerMVPattern = cornerMVPattern | (amvpInfo1.numCand << 1);
//------------------- V2 (START) -------------------//
AMVPInfo amvpInfo2;
amvpInfo2.numCand = 0;
// F->G: Left, Below Left
addMVPCandUnscaled( pu, eRefPicList, refIdx, posLB, MD_LEFT, amvpInfo2 );
if ( amvpInfo2.numCand < 1 )
{
addMVPCandUnscaled( pu, eRefPicList, refIdx, posLB, MD_BELOW_LEFT, amvpInfo2 );
}
cornerMVPattern = cornerMVPattern | (amvpInfo2.numCand << 2);
outputAffineMv[0] = amvpInfo0.mvCand[0];
outputAffineMv[1] = amvpInfo1.mvCand[0];
outputAffineMv[2] = amvpInfo2.mvCand[0];
outputAffineMv[0].roundAffinePrecInternal2Amvr(pu.cu->imv);
outputAffineMv[1].roundAffinePrecInternal2Amvr(pu.cu->imv);
outputAffineMv[2].roundAffinePrecInternal2Amvr(pu.cu->imv);
if ( cornerMVPattern == 7 || (cornerMVPattern == 3 && pu.cu->affineType == AFFINEMODEL_4PARAM) )
{
affiAMVPInfo.mvCandLT[affiAMVPInfo.numCand] = outputAffineMv[0];
affiAMVPInfo.mvCandRT[affiAMVPInfo.numCand] = outputAffineMv[1];
affiAMVPInfo.mvCandLB[affiAMVPInfo.numCand] = outputAffineMv[2];
affiAMVPInfo.numCand++;
}
if ( affiAMVPInfo.numCand < 2 )
{
// check corner MVs
for ( int i = 2; i >= 0 && affiAMVPInfo.numCand < AMVP_MAX_NUM_CANDS; i-- )
{
if ( cornerMVPattern & (1 << i) ) // MV i exist
{
affiAMVPInfo.mvCandLT[affiAMVPInfo.numCand] = outputAffineMv[i];
affiAMVPInfo.mvCandRT[affiAMVPInfo.numCand] = outputAffineMv[i];
affiAMVPInfo.mvCandLB[affiAMVPInfo.numCand] = outputAffineMv[i];
affiAMVPInfo.numCand++;
}
}
// Get Temporal Motion Predictor
if ( affiAMVPInfo.numCand < 2 && pu.cs->slice->getEnableTMVPFlag() )
{
const int refIdxCol = refIdx;
Position posRB = pu.Y().bottomRight().offset( -3, -3 );
const PreCalcValues& pcv = *pu.cs->pcv;
Position posC0;
bool C0Avail = false;
Position posC1 = pu.Y().center();
#if !JVET_N0266_SMALL_BLOCKS
bool C1Avail = ( posC1.x < pcv.lumaWidth ) && ( posC1.y < pcv.lumaHeight ) ;
#endif
Mv cColMv;
if ( ((posRB.x + pcv.minCUWidth) < pcv.lumaWidth) && ((posRB.y + pcv.minCUHeight) < pcv.lumaHeight) )
{
Position posInCtu( posRB.x & pcv.maxCUWidthMask, posRB.y & pcv.maxCUHeightMask );
if ( (posInCtu.x + 4 < pcv.maxCUWidth) && // is not at the last column of CTU
(posInCtu.y + 4 < pcv.maxCUHeight) ) // is not at the last row of CTU
{
posC0 = posRB.offset( 4, 4 );
C0Avail = true;
}
else if ( posInCtu.x + 4 < pcv.maxCUWidth ) // is not at the last column of CTU But is last row of CTU
{
// in the reference the CTU address is not set - thus probably resulting in no using this C0 possibility
posC0 = posRB.offset( 4, 4 );
}
else if ( posInCtu.y + 4 < pcv.maxCUHeight ) // is not at the last row of CTU But is last column of CTU
{
posC0 = posRB.offset( 4, 4 );
C0Avail = true;
}
else //is the right bottom corner of CTU
{
// same as for last column but not last row
posC0 = posRB.offset( 4, 4 );
}
}
#if JVET_N0266_SMALL_BLOCKS
if ( ( C0Avail && getColocatedMVP( pu, eRefPicList, posC0, cColMv, refIdxCol ) ) || getColocatedMVP( pu, eRefPicList, posC1, cColMv, refIdxCol ) )
#else
if ( (C0Avail && getColocatedMVP( pu, eRefPicList, posC0, cColMv, refIdxCol )) || (C1Avail && getColocatedMVP( pu, eRefPicList, posC1, cColMv, refIdxCol ) ) )
#endif
{
cColMv.roundAffinePrecInternal2Amvr(pu.cu->imv);
affiAMVPInfo.mvCandLT[affiAMVPInfo.numCand] = cColMv;
affiAMVPInfo.mvCandRT[affiAMVPInfo.numCand] = cColMv;
affiAMVPInfo.mvCandLB[affiAMVPInfo.numCand] = cColMv;
affiAMVPInfo.numCand++;
}
}
//!<0向量
if ( affiAMVPInfo.numCand < 2 )
{
// add zero MV
for ( int i = affiAMVPInfo.numCand; i < AMVP_MAX_NUM_CANDS; i++ )
{
affiAMVPInfo.mvCandLT[affiAMVPInfo.numCand].setZero();
affiAMVPInfo.mvCandRT[affiAMVPInfo.numCand].setZero();
affiAMVPInfo.mvCandLB[affiAMVPInfo.numCand].setZero();
affiAMVPInfo.numCand++;
}
}
}
for (int i = 0; i < affiAMVPInfo.numCand; i++)
{
affiAMVPInfo.mvCandLT[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
affiAMVPInfo.mvCandRT[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
affiAMVPInfo.mvCandLB[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
}
}以下是affine merge list构建的代码:
void PU::getAffineMergeCand( const PredictionUnit &pu, AffineMergeCtx& affMrgCtx, const int mrgCandIdx )
{
const CodingStructure &cs = *pu.cs;
const Slice &slice = *pu.cs->slice;
const uint32_t maxNumAffineMergeCand = slice.getMaxNumAffineMergeCand();
for ( int i = 0; i < maxNumAffineMergeCand; i++ )
{
for ( int mvNum = 0; mvNum < 3; mvNum++ )
{
affMrgCtx.mvFieldNeighbours[(i << 1) + 0][mvNum].setMvField( Mv(), -1 );
affMrgCtx.mvFieldNeighbours[(i << 1) + 1][mvNum].setMvField( Mv(), -1 );
}
affMrgCtx.interDirNeighbours[i] = 0;
affMrgCtx.affineType[i] = AFFINEMODEL_4PARAM;
affMrgCtx.mergeType[i] = MRG_TYPE_DEFAULT_N;
affMrgCtx.GBiIdx[i] = GBI_DEFAULT;
}
affMrgCtx.numValidMergeCand = 0;
affMrgCtx.maxNumMergeCand = maxNumAffineMergeCand;
bool enableSubPuMvp = slice.getSPS()->getSBTMVPEnabledFlag() && !(slice.getPOC() == slice.getRefPic(REF_PIC_LIST_0, 0)->getPOC() && slice.isIRAP());
bool isAvailableSubPu = false;
if ( enableSubPuMvp && slice.getEnableTMVPFlag() )
{
MergeCtx mrgCtx = *affMrgCtx.mrgCtx;
bool tmpLICFlag = false;
CHECK( mrgCtx.subPuMvpMiBuf.area() == 0 || !mrgCtx.subPuMvpMiBuf.buf, "Buffer not initialized" );
mrgCtx.subPuMvpMiBuf.fill( MotionInfo() );
int pos = 0;
// Get spatial MV
const Position posCurLB = pu.Y().bottomLeft();
MotionInfo miLeft;
//left
const PredictionUnit* puLeft = cs.getPURestricted( posCurLB.offset( -1, 0 ), pu, pu.chType );
const bool isAvailableA1 = puLeft && isDiffMER( pu, *puLeft ) && pu.cu != puLeft->cu && CU::isInter( *puLeft->cu );
if ( isAvailableA1 )
{
miLeft = puLeft->getMotionInfo( posCurLB.offset( -1, 0 ) );
// get Inter Dir
mrgCtx.interDirNeighbours[pos] = miLeft.interDir;
// get Mv from Left
mrgCtx.mvFieldNeighbours[pos << 1].setMvField( miLeft.mv[0], miLeft.refIdx[0] );
if ( slice.isInterB() )
{
mrgCtx.mvFieldNeighbours[(pos << 1) + 1].setMvField( miLeft.mv[1], miLeft.refIdx[1] );
}
pos++;
}
mrgCtx.numValidMergeCand = pos;
isAvailableSubPu = getInterMergeSubPuMvpCand( pu, mrgCtx, tmpLICFlag, pos
, 0
);
if ( isAvailableSubPu )
{
for ( int mvNum = 0; mvNum < 3; mvNum++ )
{
affMrgCtx.mvFieldNeighbours[(affMrgCtx.numValidMergeCand << 1) + 0][mvNum].setMvField( mrgCtx.mvFieldNeighbours[(pos << 1) + 0].mv, mrgCtx.mvFieldNeighbours[(pos << 1) + 0].refIdx );
affMrgCtx.mvFieldNeighbours[(affMrgCtx.numValidMergeCand << 1) + 1][mvNum].setMvField( mrgCtx.mvFieldNeighbours[(pos << 1) + 1].mv, mrgCtx.mvFieldNeighbours[(pos << 1) + 1].refIdx );
}
affMrgCtx.interDirNeighbours[affMrgCtx.numValidMergeCand] = mrgCtx.interDirNeighbours[pos];
affMrgCtx.affineType[affMrgCtx.numValidMergeCand] = AFFINE_MODEL_NUM;
affMrgCtx.mergeType[affMrgCtx.numValidMergeCand] = MRG_TYPE_SUBPU_ATMVP;
if ( affMrgCtx.numValidMergeCand == mrgCandIdx )
{
return;
}
affMrgCtx.numValidMergeCand++;
// early termination
if ( affMrgCtx.numValidMergeCand == maxNumAffineMergeCand )
{
return;
}
}
}
if ( slice.getSPS()->getUseAffine() )
{
///> Start: inherited affine candidates
const PredictionUnit* npu[5];
int numAffNeighLeft = getAvailableAffineNeighboursForLeftPredictor( pu, npu );
int numAffNeigh = getAvailableAffineNeighboursForAbovePredictor( pu, npu, numAffNeighLeft );
for ( int idx = 0; idx < numAffNeigh; idx++ )
{
// derive Mv from Neigh affine PU
Mv cMv[2][3];
const PredictionUnit* puNeigh = npu[idx];
pu.cu->affineType = puNeigh->cu->affineType;
if ( puNeigh->interDir != 2 )
{
xInheritedAffineMv( pu, puNeigh, REF_PIC_LIST_0, cMv[0] );
}
if ( slice.isInterB() )
{
if ( puNeigh->interDir != 1 )
{
xInheritedAffineMv( pu, puNeigh, REF_PIC_LIST_1, cMv[1] );
}
}
for ( int mvNum = 0; mvNum < 3; mvNum++ )
{
affMrgCtx.mvFieldNeighbours[(affMrgCtx.numValidMergeCand << 1) + 0][mvNum].setMvField( cMv[0][mvNum], puNeigh->refIdx[0] );
affMrgCtx.mvFieldNeighbours[(affMrgCtx.numValidMergeCand << 1) + 1][mvNum].setMvField( cMv[1][mvNum], puNeigh->refIdx[1] );
}
affMrgCtx.interDirNeighbours[affMrgCtx.numValidMergeCand] = puNeigh->interDir;
affMrgCtx.affineType[affMrgCtx.numValidMergeCand] = (EAffineModel)(puNeigh->cu->affineType);
affMrgCtx.GBiIdx[affMrgCtx.numValidMergeCand] = puNeigh->cu->GBiIdx;
if ( affMrgCtx.numValidMergeCand == mrgCandIdx )
{
return;
}
// early termination
affMrgCtx.numValidMergeCand++;
if ( affMrgCtx.numValidMergeCand == maxNumAffineMergeCand )
{
return;
}
}
///> End: inherited affine candidates
///> Start: Constructed affine candidates
{
MotionInfo mi[4];
bool isAvailable[4] = { false };
#if JVET_N0481_BCW_CONSTRUCTED_AFFINE
int8_t neighGbi[4] = { GBI_DEFAULT };
#endif
// control point: LT B2->B3->A2
const Position posLT[3] = { pu.Y().topLeft().offset( -1, -1 ), pu.Y().topLeft().offset( 0, -1 ), pu.Y().topLeft().offset( -1, 0 ) };
for ( int i = 0; i < 3; i++ )
{
const Position pos = posLT[i];
const PredictionUnit* puNeigh = cs.getPURestricted( pos, pu, pu.chType );
if ( puNeigh && CU::isInter( *puNeigh->cu )
)
{
isAvailable[0] = true;
mi[0] = puNeigh->getMotionInfo( pos );
#if JVET_N0481_BCW_CONSTRUCTED_AFFINE
neighGbi[0] = puNeigh->cu->GBiIdx;
#endif
break;
}
}
// control point: RT B1->B0
const Position posRT[2] = { pu.Y().topRight().offset( 0, -1 ), pu.Y().topRight().offset( 1, -1 ) };
for ( int i = 0; i < 2; i++ )
{
const Position pos = posRT[i];
const PredictionUnit* puNeigh = cs.getPURestricted( pos, pu, pu.chType );
if ( puNeigh && CU::isInter( *puNeigh->cu )
)
{
isAvailable[1] = true;
mi[1] = puNeigh->getMotionInfo( pos );
#if JVET_N0481_BCW_CONSTRUCTED_AFFINE
neighGbi[1] = puNeigh->cu->GBiIdx;
#endif
break;
}
}
// control point: LB A1->A0
const Position posLB[2] = { pu.Y().bottomLeft().offset( -1, 0 ), pu.Y().bottomLeft().offset( -1, 1 ) };
for ( int i = 0; i < 2; i++ )
{
const Position pos = posLB[i];
const PredictionUnit* puNeigh = cs.getPURestricted( pos, pu, pu.chType );
if ( puNeigh && CU::isInter( *puNeigh->cu )
)
{
isAvailable[2] = true;
mi[2] = puNeigh->getMotionInfo( pos );
#if JVET_N0481_BCW_CONSTRUCTED_AFFINE
neighGbi[2] = puNeigh->cu->GBiIdx;
#endif
break;
}
}
// control point: RB
if ( slice.getEnableTMVPFlag() )
{
//>> MTK colocated-RightBottom
// offset the pos to be sure to "point" to the same position the uiAbsPartIdx would've pointed to
Position posRB = pu.Y().bottomRight().offset( -3, -3 );
const PreCalcValues& pcv = *cs.pcv;
Position posC0;
bool C0Avail = false;
if ( ((posRB.x + pcv.minCUWidth) < pcv.lumaWidth) && ((posRB.y + pcv.minCUHeight) < pcv.lumaHeight) )
{
Position posInCtu( posRB.x & pcv.maxCUWidthMask, posRB.y & pcv.maxCUHeightMask );
if ( (posInCtu.x + 4 < pcv.maxCUWidth) && // is not at the last column of CTU
(posInCtu.y + 4 < pcv.maxCUHeight) ) // is not at the last row of CTU
{
posC0 = posRB.offset( 4, 4 );
C0Avail = true;
}
else if ( posInCtu.x + 4 < pcv.maxCUWidth ) // is not at the last column of CTU But is last row of CTU
{
posC0 = posRB.offset( 4, 4 );
// in the reference the CTU address is not set - thus probably resulting in no using this C0 possibility
}
else if ( posInCtu.y + 4 < pcv.maxCUHeight ) // is not at the last row of CTU But is last column of CTU
{
posC0 = posRB.offset( 4, 4 );
C0Avail = true;
}
else //is the right bottom corner of CTU
{
posC0 = posRB.offset( 4, 4 );
// same as for last column but not last row
}
}
Mv cColMv;
int refIdx = 0;
bool bExistMV = C0Avail && getColocatedMVP( pu, REF_PIC_LIST_0, posC0, cColMv, refIdx );
if ( bExistMV )
{
mi[3].mv[0] = cColMv;
mi[3].refIdx[0] = refIdx;
mi[3].interDir = 1;
isAvailable[3] = true;
}
if ( slice.isInterB() )
{
bExistMV = C0Avail && getColocatedMVP( pu, REF_PIC_LIST_1, posC0, cColMv, refIdx );
if ( bExistMV )
{
mi[3].mv[1] = cColMv;
mi[3].refIdx[1] = refIdx;
mi[3].interDir |= 2;
isAvailable[3] = true;
}
}
}
//------------------- insert model -------------------//
int order[6] = { 0, 1, 2, 3, 4, 5 };
int modelNum = 6;
int model[6][4] = {
{ 0, 1, 2 }, // 0: LT, RT, LB
{ 0, 1, 3 }, // 1: LT, RT, RB
{ 0, 2, 3 }, // 2: LT, LB, RB
{ 1, 2, 3 }, // 3: RT, LB, RB
{ 0, 1 }, // 4: LT, RT
{ 0, 2 }, // 5: LT, LB
};
int verNum[6] = { 3, 3, 3, 3, 2, 2 };
int startIdx = pu.cs->sps->getUseAffineType() ? 0 : 4;
for ( int idx = startIdx; idx < modelNum; idx++ )
{
int modelIdx = order[idx];
#if JVET_N0481_BCW_CONSTRUCTED_AFFINE
getAffineControlPointCand(pu, mi, neighGbi, isAvailable, model[modelIdx], modelIdx, verNum[modelIdx], affMrgCtx);
#else
getAffineControlPointCand( pu, mi, isAvailable, model[modelIdx], modelIdx, verNum[modelIdx], affMrgCtx );
#endif
if ( affMrgCtx.numValidMergeCand != 0 && affMrgCtx.numValidMergeCand - 1 == mrgCandIdx )
{
return;
}
// early termination
if ( affMrgCtx.numValidMergeCand == maxNumAffineMergeCand )
{
return;
}
}
}
///> End: Constructed affine candidates
}
///> zero padding
int cnt = affMrgCtx.numValidMergeCand;
while ( cnt < maxNumAffineMergeCand )
{
for ( int mvNum = 0; mvNum < 3; mvNum++ )
{
affMrgCtx.mvFieldNeighbours[(cnt << 1) + 0][mvNum].setMvField( Mv( 0, 0 ), 0 );
}
affMrgCtx.interDirNeighbours[cnt] = 1;
if ( slice.isInterB() )
{
for ( int mvNum = 0; mvNum < 3; mvNum++ )
{
affMrgCtx.mvFieldNeighbours[(cnt << 1) + 1][mvNum].setMvField( Mv( 0, 0 ), 0 );
}
affMrgCtx.interDirNeighbours[cnt] = 3;
}
affMrgCtx.affineType[cnt] = AFFINEMODEL_4PARAM;
if ( cnt == mrgCandIdx )
{
return;
}
cnt++;
affMrgCtx.numValidMergeCand++;
}
}感兴趣的请关注微信公众号Video Coding

转载自原文链接, 如需删除请联系管理员。
原文链接:VVC帧间预测(四)仿射运动补偿预测,转载请注明来源!