LIFT: Learned Invariant Feature Transform
该文介绍了一种深度学习框架,并实现了图像特征点检测、方向估计和描述符提取,其中每一个部分都是基于卷积神经网络CNNs实现,采用了空间转换层来修正图像块得到特征点检测和方向估计。同时,使用argmax function代替传统的非极大值抑制方法,其性能由于其他在这之前已知的方法。总体结构如下:

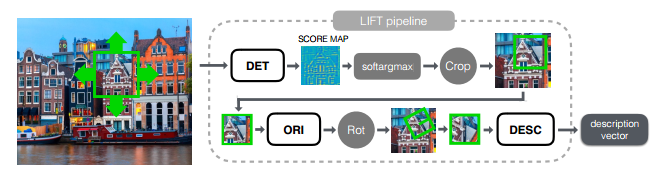
训练方法:
- 建立Siamese网络,训练所使用的特征点事来之SFM算法的结果,输入的是特征点所在的图像块;
- 首先训练描述符,然后用来训练方向估计,最后训练特征点检测;
- 训练是使用的图像块,并且是不同尺度。
训练步骤:
1. 首先训练描述符:训练图像块的位置和方向均来自SFM的特征点,其中会取四个图像块P1,P2,P3,P4;P1,P2是来自同一个3D点在不同视角下的图像,P3是不同3D点投影回来的图像块,P4是不包含任何特征点的图像块。那么损失函数的构建就为:
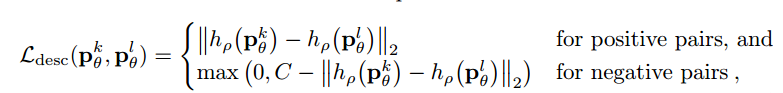
2. 训练方向Orientation Estimator,损失函数就是最小化同一3D点在不同视角下的描述符距离,使用已经训练好的描述符来计算描述符向量:
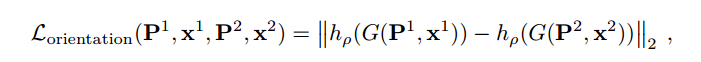
3. 训练特征点检测,输入一个图像块,输出score map。其计算函数为:
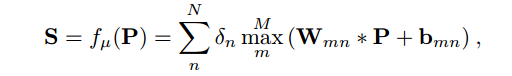
其使用最大分数图的位置代替直接用sfm的位置,使其非常容易的去训练而且可靠,位置x的函数由S得到:
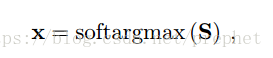
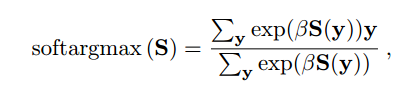
最终损失函数定义为:
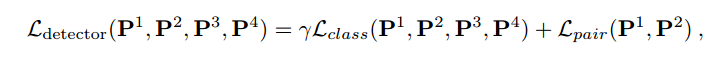
运行流程:
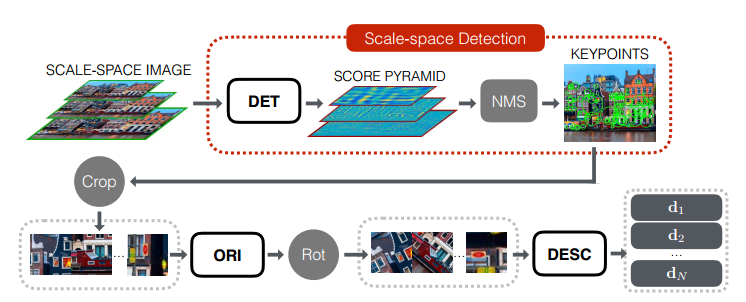
结论:
这篇文章提出了一个深度网络框架,结合了特征点检测,方向估计和描述符计算模块,使用后向传播进行端到端的训练。训练过程从后往前,先训练描述符,在训练方向估计,最后训练特征点检测模块。从作者实验对比效果看,这种方法与传统SIFT方法比较,对光照和季节变化具有很强的鲁棒性。
转载自原文链接, 如需删除请联系管理员。
原文链接:笔记 : LIFT: Learned Invariant Feature Transform 深度学习的特征点检测,转载请注明来源!