基本概念
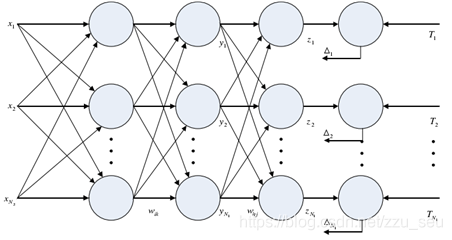
误差反向传播神经网络简称为BP(Back Propagation)网络,它是一种具有三层或三层以上的多层神经网络,每一层都由若干个神经元组成。如图所示为一个BP神经网络的结构图,它的左、右各层之间各个神经元实现全连接,即左层的每一个神经元与右层的每个神经元都有连接,而上下各神经元之间无连接。BP神经网络按有监督学习方式进行训练,当一对学习模式提供给网络后,其神经元的激活值将从输入层经各隐含层向输出层传播,在输出层的各神经元输出对应于输入模式的网络响应。然后,按减少希望输出与实际输出误差的原则,从输出层经各隐含层、最后回到输人层逐层修正各连接权。由于这种修正过程是从输出到输入逐层进行的,所以称它为“误差逆传播算法”。随着这种误差逆传播训练的不断进行,网络对输入模式响应的正确率也将不断提高。

BP神经网络参数
在进行BP神经网络的设计时,应从网络的层数、每层中的神经元数、初始值以及学习速率等几个方面进行考虑。
1)网络的层数。已经证明:三层BP神经网络可以实现多维单位立方体 到 的映射,即能够逼近任何有理函数。这实际上给了一个设计BP神经网络的基本原则。增加层数可以更进一步地降低误差,提高精度,但同时也使网络复杂化,从而增加网络权值的训练时间。而误差精度的提高实际上也可以通过增加隐含层中的神经元数目来获得,其训练结果也比增加层数更容易观察和调整。所以一般情况下,应优先考虑增加隐含层中的神经元数。
2)隐含层的神经元数。网络训练精度的提高,可以通过采用一个隐含层而增加神经元数的方法来获得。这在结构的实现上要比增加更多的隐含层简单得多。在具体设计时,比较实际的做法是隐含层取输人层的两倍,然后适当地加上一点余量。评价一个网络设计得好坏,首先是它的精度,其次是训练时间。时间包含有两层: 一层是循环次数,二是每一次循环中计算所花的时间。
3)初始权值的选取。由于系统是非线性的,初始值的选取对于学习是否达到局部最小、是否能够收敛以及训练时间的长短有很大关系。初始值过大过小都会影响学习速度,因此权值的初始值应选为均匀分布的小数经验值,一般取初始权值在(-1,1)之间的随机数,也可选取在[-2.4/n,2.4/n] 之间的随机数,其中n为输人特征个数。为避免每步权值的调整方向是同向的,应将初始值设为随机数。
4)学习速率。学习速率决定每次循环训练中 所产生的权值变化量。高的学习速率可能导致系统的不稳定;但低的学习速率导致较长的训练时间,可能收敛很慢,不过能保证网络的误差值跳出误差表面的低谷而最终趋于最小误差值。在一般情况下,倾向于选取较小的学习速率以保证系统的稳定性。学习速率的选取0.01 ~0. 8。
如同初始权值的选取过程一样,在一个神经网络的设计中,网络要经过几个不同的学习速率的训练,通过观察每一次训练后的误差平方和的下降速率来判断所选定的学习速率是否合适,若
下降很快,则说明学习速率合适,若
出现震荡现象,这说明学习速率过大。对于每一个具体网络都存在一个合适的学习速率,但对于较复杂网络,在误差曲面的不同部位可能需要不同的学习速率。为了减少寻找学习速率的训练次数以及训练时间,比较合适的方法是采用变化的自适应学习速率,使网络的训练在不同的阶段自动设置不同学习的速率。一般来说,学习速率越高,收敛越快.但容易震荡而学习速率越低.收敛越慢。
5)期望误差的选取。在网络的训练过程中期望误差值也应当通过对比训练后确定一个合适的值。所谓的“合适”,是相对于所需要的隐含层的结点数来确定的,因为较小的期望误差要靠增加隐含层的结点,以及训练时间来获得。一般情况下,作为对比,可以同时对两个不同期望误差的网络进行训练,最后通过综合因素的考虑来确定采用其中
尽管含有隐含层的神经网络能实现任意连续函数的逼近,但在训练过程中如果一些参数选取得合适,可以加快神经网络的训练,缩短神经网络的训练时间和取得满意的训练结果。对训练过程有较大影响的是权系数的初值、学习速率等。
实验背景
本次实验采用的数据集是从网上下载的使用近红外变换光谱仪对不同的汽油样本进行扫描后得到的实验数据,以此数据使用BP神经网络建立既有样品近红外光谱以及辛烷值之间的数学模型。辛烷值是汽油中十分重要的意向品质指标,在传统的实验检测方法中存在样品用量过大,测试周期长和费用高的问题。近年来发展的近红外光谱法可以快速的对辛烷含量进行分析。
数据集中包含采集到的60组汽油样品,利用傅立叶近红外变换光谱仪对其进行扫描,扫描间隔为2nm,每个样品的光谱曲线包含401个波长点,样品的近红外光谱曲线如图所示,其中包含对曲线的局部放大图。同时数据集中包含使用传统的检测方法测定的辛烷含量值。
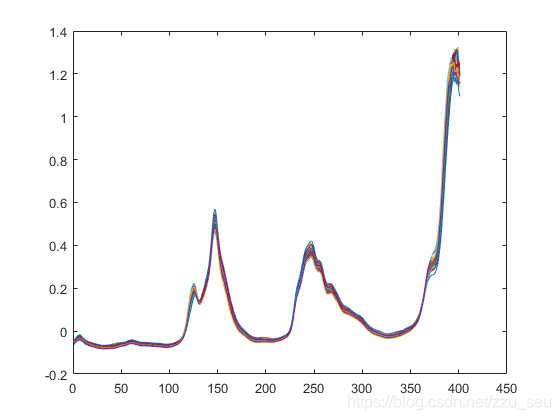
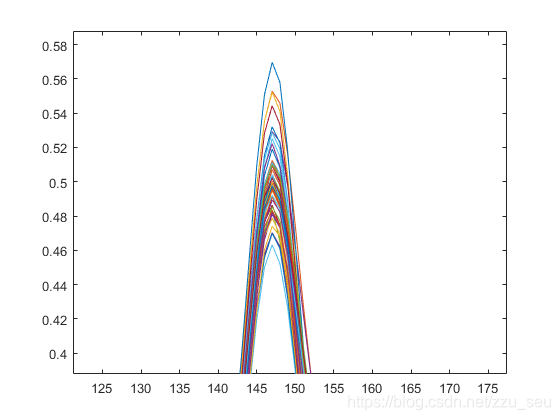
从图可以看出,不同浓度的汽油的近红外光谱在一些峰值的地方会表现出一些差异。我们主要根据这些差异来建立模型进行辛烷浓度的预测。整个60组数据随机抽取50组作为训练集,剩下的10组作为测试集。
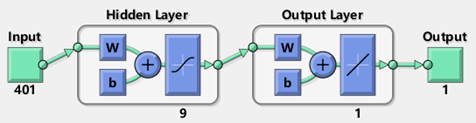
如图所示为使用MATLAB建立的神经网络结构,其中神经网络的输入值个数为401个,隐含层的个数为9层。神经网络训练参数的设置分别为:迭代次数1000次,训练目标为10-3,学习率设置为0.01。
实验结果
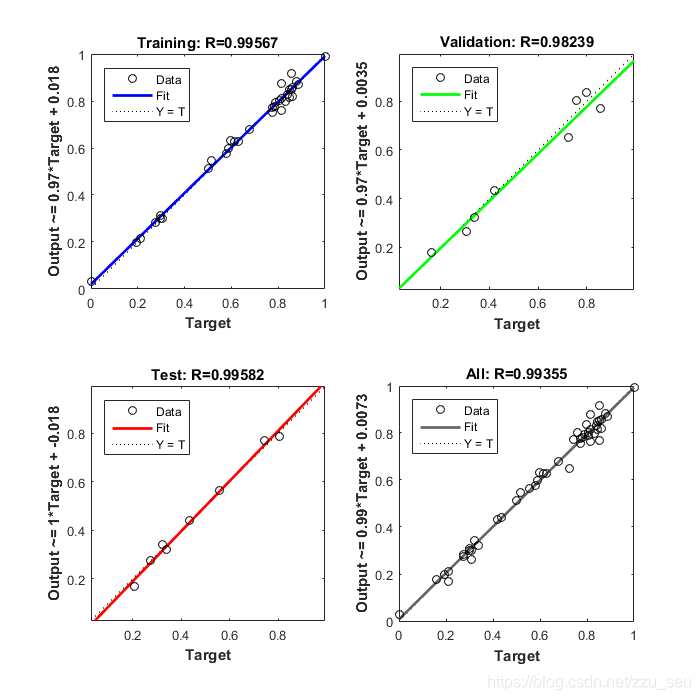
如图所示为使用MATLAB进行神经网络进行训练之后的回归结果,可以看出目标值和输出结果基本上在同一个直线上,训练结果比较好。
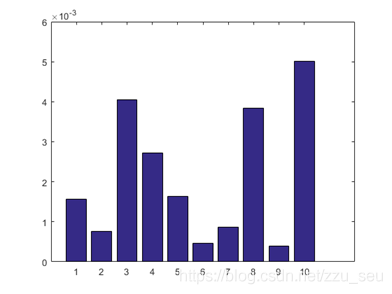
然后对训练后得到的10组结果进行反归一化后,再计算出结果与标准结果的相对误差,画出10组测试集所得出的结果与答案的相对误差的柱形图如图7所示。从图中我们可以看出训练得到的结果是比较准确的,相对误差最大只为0.6%。然后再计算出魔性的决定系数,决定系数也称为拟合优度,决定系数越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比高。观察点在回归直线附近越密集。决定系数的范围在[0,1]之内,越接近1代表魔性的性能越好,越接近0代表性能越差。本次训练得到的模型计算出的结果的决定系数为0.966,可以很好的对结果进行预测。
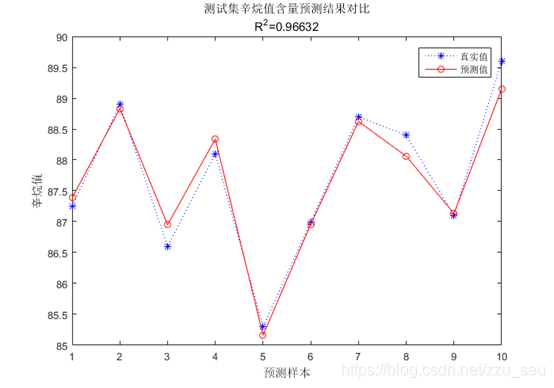
最后画出真实结果与使用BP神经网络预测结果的对比图,从图8中我们可以看出,预测的结果与实际的结果是十分相近的,说明该模型具有较好的回归结果。
源码
clear all
clc
%导入数据
load spectra_data.mat
% 随机产生训练集和测试集
temp = randperm(size(NIR,1));
% 训练集——50个样本
P_train = NIR(temp(1:50),:)';
T_train = octane(temp(1:50),:)';
% 测试集——10个样本
P_test = NIR(temp(51:end),:)';
T_test = octane(temp(51:end),:)';
N = size(P_test,2);
%数据归一化
[p_train, ps_input] = mapminmax(P_train,0,1);
p_test = mapminmax('apply',P_test,ps_input);
[t_train, ps_output] = mapminmax(T_train,0,1);
%创建网络
net = newff(p_train,t_train,9);
% 设置训练参数
net.trainParam.epochs = 1000;
net.trainParam.goal = 1e-3;
net.trainParam.lr = 0.01;
%训练网络
net = train(net,p_train,t_train);
%仿真测试
t_sim = sim(net,p_test);
%数据反归一化
T_sim = mapminmax('reverse',t_sim,ps_output);
%相对误差error
error = abs(T_sim - T_test)./T_test;
%决定系数R^2
R2 = (N * sum(T_sim .* T_test) - sum(T_sim) * sum(T_test))^2 / ((N * sum((T_sim).^2) - (sum(T_sim))^2) * (N * sum((T_test).^2) - (sum(T_test))^2));
%结果对比
result = [T_test' T_sim' error']
%绘图
figure
plot(1:N,T_test,'b:*',1:N,T_sim,'r-o')
legend('真实值','预测值')
xlabel('预测样本')
ylabel('辛烷值')
string = {'测试集辛烷值含量预测结果对比';['R^2=' num2str(R2)]};
title(string)
转载自原文链接, 如需删除请联系管理员。
原文链接:基于BP神经网络的回归预测,转载请注明来源!