

前言
提到数据库索引,大家肯定很熟悉,在日常工作中经常会接触到。这几天看了不少相关文章、书籍和课程。决定自己总结一篇文章,虽然我写的这篇文章肯定不如网上各路大神的好文,但是自己总结一遍总归记得更牢固。这应该也是一种好的学习习惯,别人写的字再漂亮都是别人的,自己写的字就算再潦草起码自己也能认识吧 。
索引是一种提高我们查询效率的数据结构。就好像是字典的目录,一本几百页的字典,如果想快速查询到某个字,总不能靠硬翻吧。
索引结构
结论
MySQL 索引一般是哈希表或 B+ 树,常用的 InnoDB 引擎默认使用的是 B+ 树来作为索引的数据结构。
为什么不用哈希表?
如果使用 B+ 树作为索引数据结构,那么访问或修改一条数据的时间复杂度是 O(log n),但是使用哈希表作为索引结构干这些活的时候,时间复杂度 O(1)。如果只是查一条数据或者修改一条数据,用哈希表做索引肯定给力呀!但是一般业务系统不会这么简单。
在业务开发中,经常会遇到范围查询、排序查询等需求。这个时候哈希表索引就没办法高效的处理这些需求了。它只能通过扫表来实现这些功能,扫表应该是数据库的噩梦吧。
MySQL 使用 B+ 树数据结构非叶子节点只储存键值,叶子节点会储存数据或者是主键。并且在叶子节点中键是按照顺序存储的,使得范围查询、排序查询等变得异常简单。
虽然哈希表索引在操作单列数据的时候十分高效,但是需要范围查询、排序查询的时候,B+ 树数据结构显然更合适。在我们业务开发中,不可能只操作一行数据。综合考虑,还是 B+ 树更适合作为索引的数据结构。
哈希表索引不支持范围查询,不能利用索引来排序,不支持联合索引最左匹配原则,如果重复键值比较多,还容易造成哈希碰撞导致效率进一步降低。
为什么不用 B 树?
B+ 树的非叶子节点上只储存键值,而 B 树的非叶子节点上不仅储存键值还储存数据。在 MySQL 数据库中数据页的大小是固定的,Innodb 引擎数据页默认大小为 16 KB。B+ 树这种做法是为了让树的阶数更大,让树更矮胖。进行查询的时候,磁盘 IO 次数就会减少,查询效率也会更快。
B+ 树的所有数据均储存在叶子节点中,并且是按键值有序排列。但是 B 树的数据分散在各个节点。进行范围查询,排序查询的时候,B 树的效率肯定不如 B+ 树。
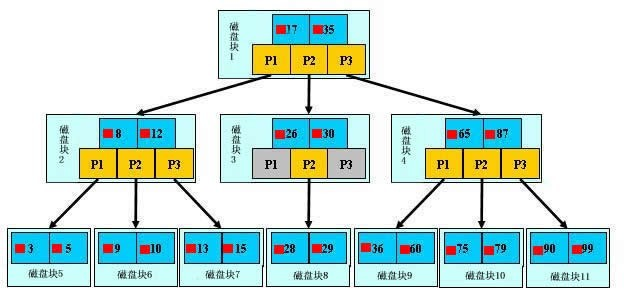
B+ 树查找过程
磁盘块 1 中存储 17 和 35 数据项,还有 P1、P2、P3 指针,P1 表示数据项小于 17 的磁盘块,P2 表示数据项在 17 和 35 之间的数据项,P3 表示数据项大于 35 的数据项。非叶子节点不储存数据,只储存指引搜索方向的数据项。
我们知道每次 IO 读取一个数据页的大小,也就是一个磁盘块。假设我们要查找 29 这个数据项,首先进行第一次 IO 将磁盘块 1 读进内存,发现 17 < 29 < 35,然后选用 P2 指针进行第二次 IO 将磁盘块 3 读进内存,发现 26 < 29 < 30,然后选用 P2 指针将磁盘块 8 读进内存,在内存中做二分查找,找到 29,结束查询。
通过分析查询过程,我们可以知道 IO 次数和 B+ 树的高度成正比。H 为树的高度,M 为每个磁盘块的数据项个数,N 为数据项总数。从下面的公式可以看出如果数据量 N 一定,M 越大相应的 H 就越小。
M 等于磁盘块的大小除以数据项大小,由于磁盘块大小一般是固定的,所以减小数据项大小才能使得 M 更大从而让树更矮胖。这也是为什么 B+ 树把真实数据放在叶子节点而不是非叶子节点的原因,如果真实数据放在非叶子结点,磁盘块存储的数据项会大幅度减少,树就会增高相应查询数据时的 IO 次数就会变多。
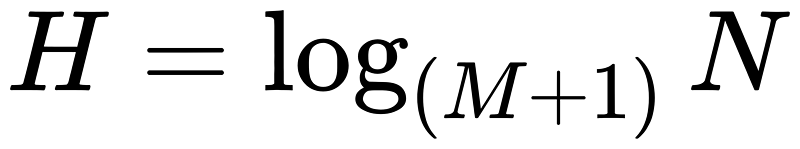
B+ 树一般能储存多少数据?
这里我们先假设 B+ 树高为 2,即存在一个根节点和若干个叶子节点,假设一行记录的数据大小为 1 KB,那么单个叶子节点(页)中的记录数等于 16 KB / 1 KB = 16 条数据。
然后要计算出非叶子节点能存放多少指针,我们假设主键 ID 为 bigint 类型,长度为 8 字节,而指针大小在 InnoDB 源码中设置为 6 字节,这样一共 14 字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即 16 KB / 14 B = 1170。那么可以算出一棵高度为 2 的 B+ 树,大概就能存放下 1170 * 16 = 18720 条数据。
根据同样的原理我们可以算出一个高度为 3 的 B+ 树就可以存放下 21902400 条数据。所以在 InnoDB 中 B+ 树高度一般为 1 - 3 层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次 IO,所以通过主键索引查询通常只需要 1 - 3 次逻辑 IO 操作即可查找到数据。
总结
哈希表索引操作单数据行的时候很快,但是不支持范围查询,不能利用索引来排序,不支持联合索引最左匹配原则。
B 树的数据可以存储在非叶子节点中,范围查询时可能会有额外的随机磁盘 IO。而且由于真实数据存放在非叶子节点中,B 树的高度肯定要高于同样情况下的 B+ 树。这样也不利于提升效率。
B+ 树把真实数据存储在叶子节点中是为了让树更矮胖,减少 IO 次数,提升效率。
最后
这是我学习 MySQL 索引结构记录下的一些笔记,之后也还会总结一篇索引使用的相关注意事项。我发现阅读完各路大神的文章之后,再自己写一遍印象会深刻许多。虽然是炒旧饭,但也是炒给自己吃。希望大家多多给我鼓励,哈哈哈哈哈。
链接:https://segmentfault.com/a/1190000023461927
作者:曾是然
转载自原文链接, 如需删除请联系管理员。
原文链接:再一次学习 MySQL 索引,转载请注明来源!