msdn.itellyou.cn这个网站首页是SPA单页应用,所有数据用过请求restfulAPI来获取,然后动态生成页面。
通过chrome的调试工具可以抓取到获取数据的API接口地址,以及参数情况。
get_download_list函数中传入的id是在首页操作系统页面抓到的。


下面脚本是抓取操作系统的下载链接
#!/usr/bin/python
# -*- coding: utf-8 -*-
import re
import json
import requests
API_MSDN_INDEX = 'https://msdn.itellyou.cn/'
API_INDEX = 'http://msdn.itellyou.cn/Category/Index'
API_GET_LANG = 'https://msdn.itellyou.cn/Category/GetLang'
API_GET_LIST = 'https://msdn.itellyou.cn/Category/GetList'
API_GET_PRODUCT = 'https://msdn.itellyou.cn/Category/GetProduct'
headers = {
'Referer':'https://msdn.itellyou.cn/'
}
RESULT = {'data':[]}
def get_product(id):
r = requests.post(API_GET_PRODUCT, headers=headers, data={'id':id})
if r.status_code == requests.codes.ok:
item = r.json().get('result')
print 'FileName:%s' % item.get('FileName')
print 'PostData:%s' % item.get('PostDateString')
print 'SHA1:%s' % item.get('SHA1')
print 'size:%s' % item.get('size')
print 'Download:%s' % item.get('DownLoad')
return item
def get_list(id, lang_id):
r = requests.post(API_GET_LIST, headers=headers, data={'id':id, 'lang':lang_id, 'filter':'true'})
if r.status_code == requests.codes.ok:
product_list = []
for item in r.json().get('result'):
product_info = get_product(item.get('id'))
product_list.append(product_info)
return product_list
def get_lang(id):
r = requests.post(API_GET_LANG, headers=headers, data={'id':id})
if r.status_code == requests.codes.ok:
lang_list = []
for lang in r.json().get('result'):
print lang.get('lang')
info = {'lang':lang.get('lang'), 'product_list':get_list(id,lang.get('id'))}
lang_list.append(info)
return lang_list
def get_download_list(category_id):
r = requests.post(API_INDEX, headers=headers, data={'id':category_id})
if r.status_code == requests.codes.ok:
for item in r.json():
print 'System Name: %s'% item.get('name')
system_info = get_lang(item.get('id'))
system_info = {'name':item.get('name'), 'lang_list':system_info}
RESULT['data'].append(system_info)
print 'finishied!!!'
return RESULT
if __name__ == '__main__':
json_buffer = get_download_list('7ab5f0cb-7607-4bbe-9e88-50716dc43de6')
with open('./msdn.json','w') as f:
json.dump(json_buffer,f)
抓取效果
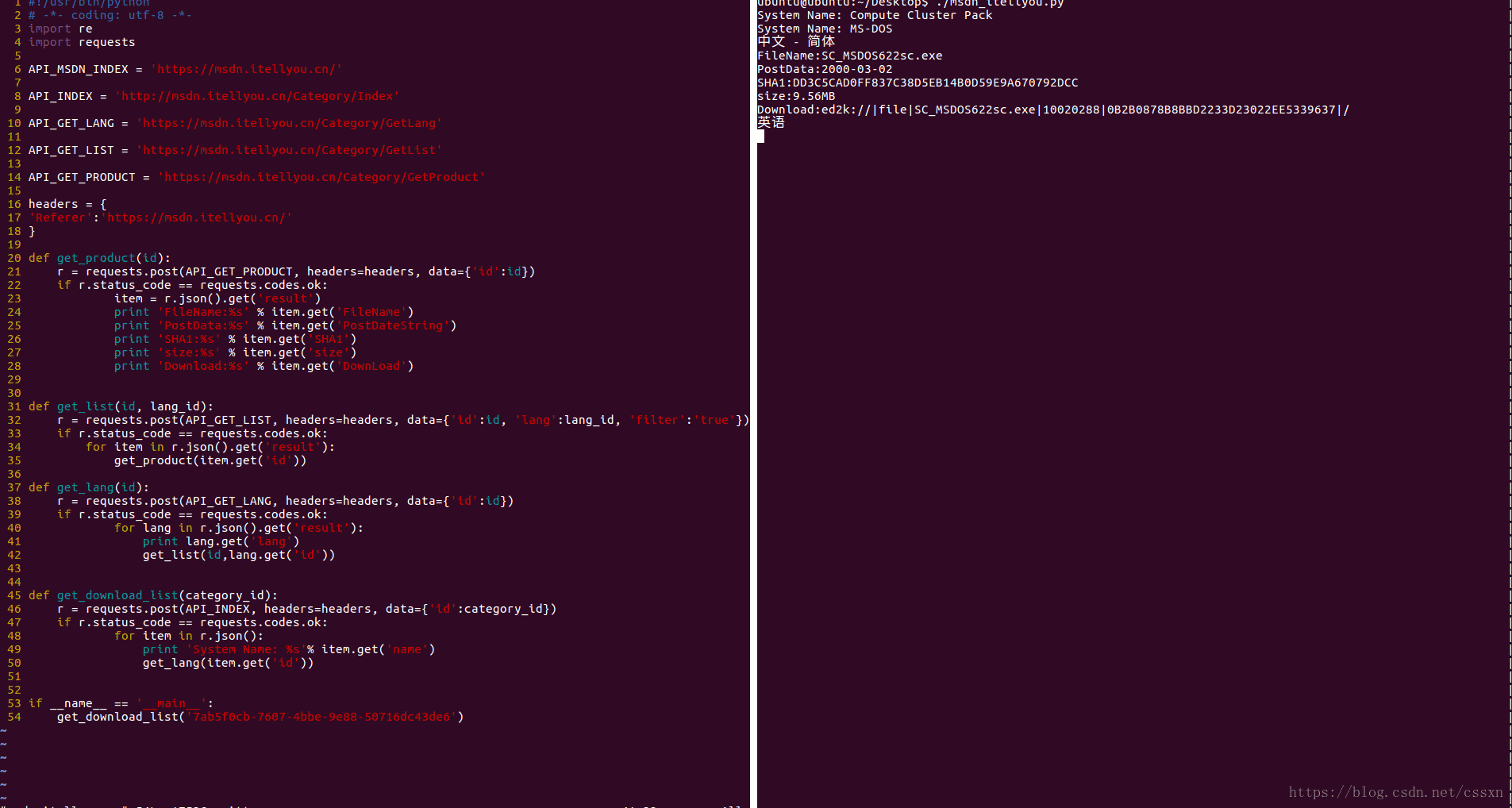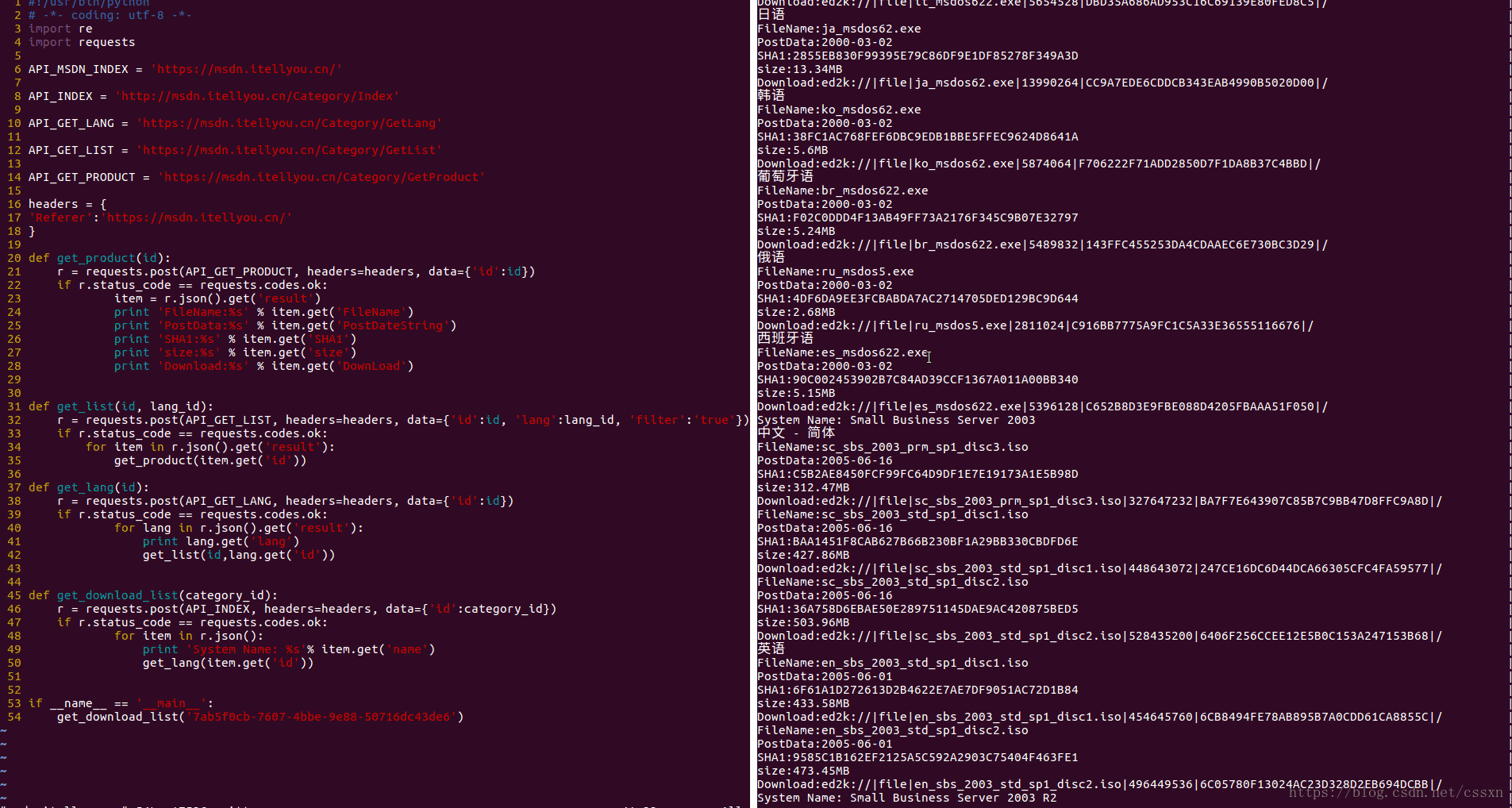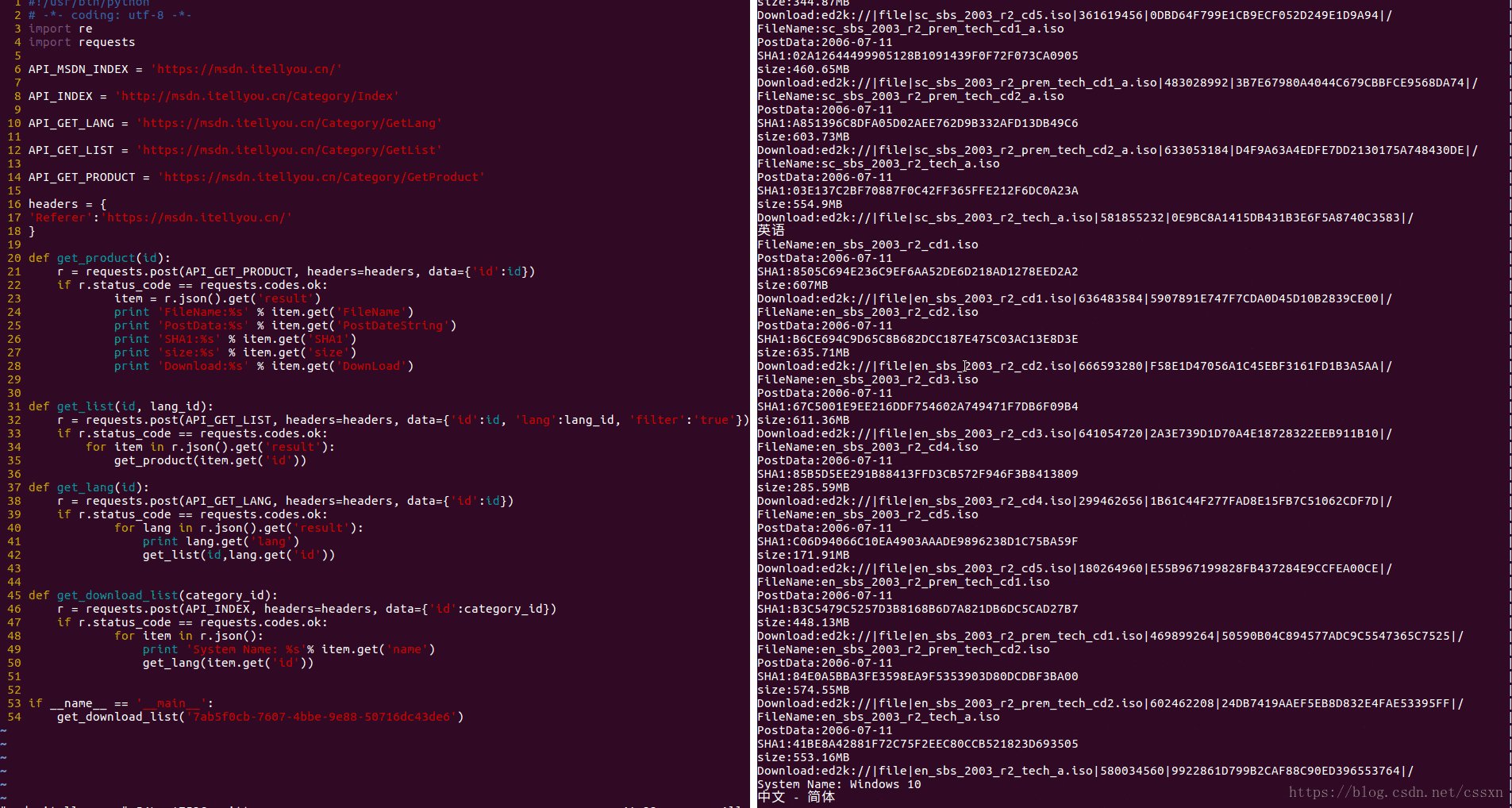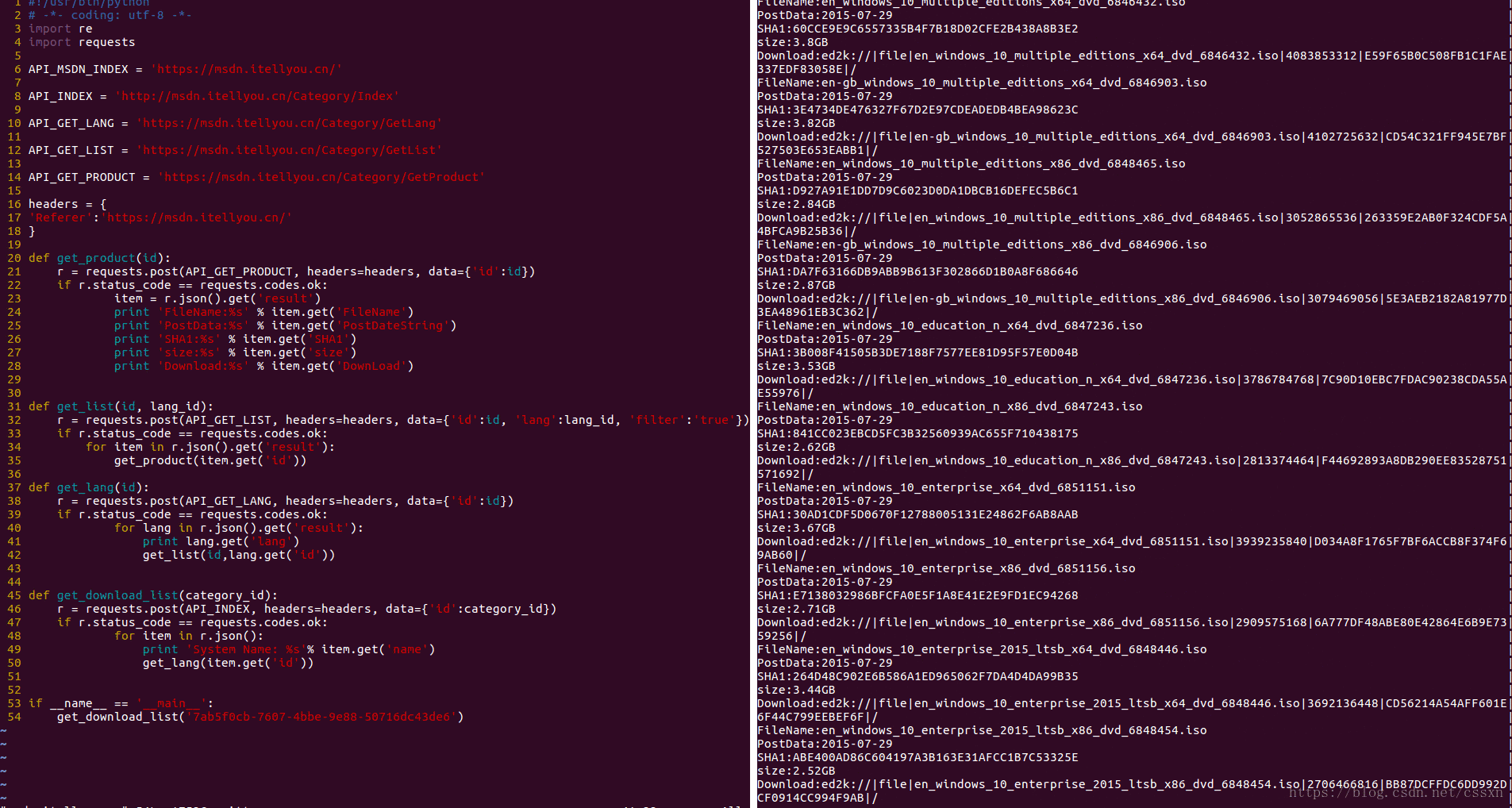
抓取所有操作系统的下载链接后,保存在本地msdn.json,现在把这些操作系统的文件,自动离线下载到百度云网盘里面。
通过chrome浏览器的开发人员调试工具,可以抓到百度云创建目录以及离线下载这两个功能的xhr请求,我们可以构造一下请求,然后读取保存的json文件,实现自动离线下载
import requests,json
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Cookie': '这里改成你的cookie',
'Referer':'https://pan.baidu.com/disk/home?'
}
def download(source_url, path):
host = 'https://pan.baidu.com/rest/2.0/services/cloud_dl?channel=chunlei&web=1&app_id=250528&bdstoken=a1ca97d6f5763c08df76e5497c66c936&logid=MTUzNjg4NzA3MjI2MjAuNzIxMTE4MDY2NDI0NDg1Ng==&clienttype=0'
payload = {
'method': 'add_task',
'app_id': '250528',
'source_url': source_url,
'save_path': path,
'type': '3'
}
r = requests.post(host, headers = headers, data = payload)
if r.status_code == requests.codes.ok:
if r.json().get('status') == 0:
return True
return False
def create(path):
host = 'https://pan.baidu.com/api/create?a=commit&channel=chunlei&web=1&app_id=250528&bdstoken=a1ca97d6f5763c08df76e5497c66c936&logid=MTUzNjg4NzMyODE2MzAuMTU4NTI4OTI3NDUxNDY1ODU=&clienttype=0'
payload = {
'path': path,
'isdir': '1',
'block_list': '[]',
}
r = requests.post(host, headers = headers, data = payload)
if r.status_code == requests.codes.ok:
if r.json().get('status') == 0:
return path
return False
def main():
with open('./msdn.json','r') as f:
temp = json.loads(f.read())['data']
for system in temp:
for lang in system['lang_list']:
tree_folder = '/msdn_itellyou/%s/%s' % (system['name'],lang['lang'])
if create(tree_folder):
print 'Create folder %s success!!'% tree_folder
for product in lang['product_list']:
if product and download(product['DownLoad'], tree_folder):
print 'Download ISO %s success!!' % product['FileName']
if __name__ == '__main__':
main()由于百度云的离线下载功能有验证,频繁调用离线下载的API会让你输入验证码。到此不再深入。

转载自原文链接, 如需删除请联系管理员。
原文链接:【爬虫】抓取msdn.itellyou.cn所有操作系统镜像下载链接,转载请注明来源!