前言
本人最近在研究强化学习方式制作游戏AI,目前项目还在进展当中,训练效果只能说是马马虎虎,可能在细节方面处理得不是很好,现在先趁着有空记录一下近阶段的学习情况吧,如果自己的研究能给大家提供一点灵感那最好不过了。
关于AI制作的方向
传统算法方式
传统算法这边不是我这次研究的重点,但确实是一个很经典的方向,很多游戏AI都是使用传统算法加以实现,比如NPC一定范围内随机走动之类的。
说是说传统算法,它的算法类型还是很多的,比如一些最短路径算法、随机分布算法之类的。
一般来说就是将游戏情况抽象成有限状态机,然后根据不同的状态施加不同的算法或者执行不同的动作,具体的话我就不深入了,传统算法网上讲解还是很多的。
强化学习方式
其实很多时候我们的机器学习也可以利用一些传统算法的,但是我这次研究的主题是强化学习方式来做AI,所以其他方式我就不谈了(毕竟没做过,不能误人子弟。。)。

先来说一下最近的新闻,OpenAI制作的Dota2游戏AI战胜了一群半职业选手,震惊众人。我也是很兴奋啊,竟然已经智能到能够协同作战了,人工智能的时代已经拉开的序幕!!
有兴趣的小伙伴也可以去了解一下OpenAI(马斯克创立的)和它的游戏环境gym(传送门),这对于入门级别的选手来说是非常有帮助的(其实我是强烈推荐的)。

DQN简介
这里只是简单介绍一下DQN,更加细节的方面就不加以赘述了。
最初的强化学习方法叫Q-Learning,它会维护一张Q表,我们会根据Q表在不同的状态选择不同的动作,同时最后根据执行动作之后的获得的奖励,反过来更新Q表(这两点是强化学习的核心,也表明其能力必须由不断的探索来加强)。
贴上伪代码(来自莫烦Python):
之后由DeepMind(没错,就是AlphaGo的创造者)提出了一种结合深度学习和强化学习的方式,就是DQN(Deep Q Network),我们的Q表不再是一张二维表,而是利用神经网络对状态值与动作进行构建。
很明显,其实简单情况下,Q-Learning可以也可以用,但是DQN是为了解决现在更复杂的情况,有更多的state(状态)、更多的action(动作),因此我们采用神经网络计算得出state的值,这样就不用维护一张很大的Q表了。


几种优化方式
说到优化我还真是有点羞愧,因为我自己的项目现在还没优化好呢,不过也就周末有空了,只能趁热先抓紧写一下了。
- Double DQN:利用DQN的新老两个神经网络,对内部参数进行更新,解决过估计(overestimate)问题。
- Prioritized Experience Replay :有时候正向奖励的样本会比较少,比如有时候只有游戏成功才给奖励,这时我们可以通过提高正向样本的优先级提升训练的速度。
- Dueling DQN:Dueling DQN是将最终的输出结果差分为动作价值和状态价值,会减少有时训练陷入的局部最优。
我的项目
由于某些原因,代码和游戏目前不能开放,也请大家谅解。
先看一下规则。
游戏规则
这是一个回合制战棋类游戏,大致规则如下:
- 我方敌方随机出生在地图上(12*12),地图上一开始会产生墙(不会消失)
- 回合制,其实是一个路径规划问题,一回合走的格子不限制,我方走到敌方附近四个格子可以进行攻击,但是这回合之前走过的格子不能重复走(Action可以抽象为九个:移动到附近八个格子或者不动结束回合)
- 会产生毒圈,每隔五回合收缩一层,进去会有伤害;同时每五回合还会产生道具,吃了攻击防御会有加成,道具不吃当回合失效
其实大家玩过《火焰之纹章》就很容易想象那个场景了,只不过我这么是一对一,并且没有那么复杂的技能,但是对于我这个新手来说这样难度的AI实现已经是挺累的了。
我们要做的其实就是尽可能多攻击到对面,然后躲到一个相对安全的区域进行防守等待下回合进攻。

实现方式
我们之前说到了强化学习方式,但是强化学习方式也是有很多的,如果入门的话也很推荐莫烦Python的网站。我有很多东西都是从上面学到的。
我最终选取的方式是DQN及其改进方法,因为我的动作是离散的(只有八个方向可以移动,这点比较关键),比较符合应用场景。
如果你的动作是连续的,可以考虑将其转化为离散的动作,或者选用其他方式比如Policy Gradients或者Actor-Critic这些强化学习方法。
我们一般会写成如下三个结构:
- 游戏环境——执行动作、返回游戏状态、可视化游戏界面(可选)等
- 神经网络——构建神经网络、进行动作选择
- 交互模块——调用上面两个模块,控制训练过程以及轮数
只要按照一定的规则写成上面三个模块,会让我们的神经网络复用性大大提高。我参照的是gym模块的方式,将游戏环境进行了构建,这块莫烦教程也有涉及。但是学习的话,我感觉侧重应该在神经网络那一块。
游戏环境
游戏环境是整个过程中最最复杂的一块,因为环境的设计也会很大程度上影响你的训练效果。我的问题初步排查也在这里,因为代码写得还不是那么规范,且所有项目基本都是一个人完成,编写的时候出现很多bug,后期排查了很久,虽然现在能运行了,但是还是有点问题。这一块如果用gym是不需要编写的,这也是推荐新手用gym的原因,抓住学习的重点,而不是死在第一步。。。
初始化
初始化的话,一般会有一些属性,当我们创建对象的时候,这些属性就跟着生成了。我就设置了很多属性(具体还是要看游戏是怎么样的),比如我方位置、我方血量、敌方位置、敌方血量等。这些属性在之后的判定是需要用到的,除非真的是完全靠图像来处理。
观测状态
OpenAI发了一篇很有名的论文《Playing Atari with Deep Reinforcement Learning》,他们利用像素游戏的图像,获取动作和指定奖励之后,让机器自动打像素游戏,比如超级马里奥之类的。也有很多大佬做了flappy bird的AI,反正就很有趣啦,可以多去看看。
我根据这个得到了一些启发,既然是像素图像,简单了解过数字图像处理的人应该知道,计算机里面存储的图像一般都是一个个数值,然后由很多像素组成,彩色图的话一般会有RGB三个轨道,如果是灰度图的话就只有一个轨道数值在0~255区间内。
这款游戏我无法直接获取游戏图像,因此我通过后台传来的数据给计算机生成了一个简单的图像。比如人物就标记为8,敌人标记为9,空地标记为0等,这样就形成了一个12*12的观测值,最后通过这个观测值进行训练。
执行动作
这一步也是关键的一步。首先我们要清楚,到底有几个动作,因为游戏里面的动作是不可能通用的吧,比如我这个游戏可以有九个动作,另一个游戏说不定就只有四个方向可以走,所以我们要根据具体情况进行编写,并且我们还要记得编写一轮训练结束的条件是什么。
与此同时,执行动作之后,游戏环境的状态还会发生变化,这里游戏环境编写最最复杂的一块,我之前的错误大多在这里,比如移动一步之后英雄的位置就肯定会发生变化、道具有没有被吃掉等等,因为我们还需要返回一个新的观测值,供AI继续进行判断。
奖励设置
其实如果其他模块什么问题的话,AI之间的真正差距就在这里了。这里其实也没有什么理论。反正我觉得有一句话挺对的,会打游戏才会做游戏。同理,会打游戏才会做AI。当然考虑的情况越多,当前AI可能会有更好的表现,但是参数的调整也是很有必要的,否则容易陷入局部最优之中。
神经网络
构建
神经网络我是采用tensorflow实现的,讲道理自己不是那么强啦,还是借鉴了一下别人的轮子进行修改的,毕竟单纯靠自己进行论文复现的话还是挺复杂的,当然也不失为一种锻炼,我因为开发比较急促,所以直接改了轮子(大家不要学啊)。
最终我采用了Dueling DQN的结构,首先将图片经过两轮的卷积池化输出到第一个全连接层,然后第二个全连接层就是DuelingDQN的核心,它将单纯的输出转变为状态价值和动作价值的和。编完之后,可以用tensorboard观察一下有没有构建错误。
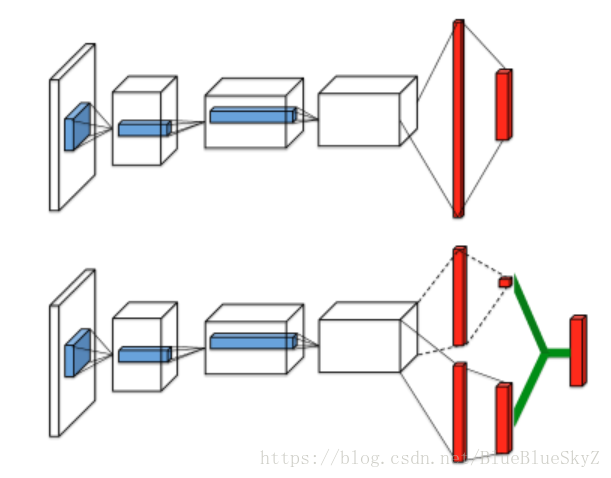
两个神经网络
我们会构建两个网络target_net和eval_net,eval_net用于预测选择动作并时时更新的,target_net是不是时时更新的。一段时间后,eval_net会将自己的数值重新给target_net。
我们进行梯度下降的对象,其实是这两个网络的均方差,用自己以前的状态进行调整。
交互模块
环境和网络构建好之后,我们就可以进行交互了,其实这一步之前写好也没关系,就没多少行代码。我们获取观测值之后选取动作,然后获得新的观测值,过一定回合结束。同时会有一轮游戏结束的判断。
def run_maze():
step = 0 # 用来控制什么时候学习
for episode in range(300):
# 初始化环境
observation = env.reset()
while True:
# 刷新环境
env.render()
# DQN 根据观测值选择行为
action = RL.choose_action(observation)
# 环境根据行为给出下一个 state, reward, 是否终止
observation_, reward, done = env.step(action)
# DQN 存储记忆
RL.store_transition(observation, action, reward, observation_)
# 控制学习起始时间和频率 (先累积一些记忆再开始学习)
if (step > 200) and (step % 5 == 0):
RL.learn()
# 将下一个 state_ 变为 下次循环的 state
observation = observation_
# 如果终止, 就跳出循环
if done:
break
step += 1 # 总步数
# end of game
print('game over')
env.destroy()
结语
总结了一波,其实还是挺菜的,争取让我的AI能够战斗吧,也希望这篇文章能给你的思路有一点点启发。
2019.4.14 补充
昨日,OpenAI Five登场的半年后正式击败了TI8的冠军队伍,按照机器训练的速度,感觉情理之中。
人类已经在星际、Dota、围棋上全部落败,但强化学习何时能突破游戏的应用场景,上升到生产生活中去,让我们拭目以待。
参考:
1.莫烦Python
2.http://www.siyuzhou.com/2018/04/11/基于-deep-qdqn-的快速避障路径规划/
转载自原文链接, 如需删除请联系管理员。
原文链接:用强化学习制作游戏AI,转载请注明来源!