CSDN的博客确实太难写编辑了,最常用的还是WORD,我是从word导过来,图片什么的重新插入的,麻烦死了。所以排版什么的可能有点不规则,见谅。
汉字模板制作:
汉字模板即是对字模图片进行特征提取,将特征数据存放到存储器上构成模板。模板制作与提取待识别汉字特征需要将原始汉字图片进行归一化,可增加特征的鲁棒性。汉字数据尺度归一化到为64*64,归一化方法很多,最常用的是基于重心的归一化,不做详细介绍。
网格特征:
在实际中,为了增加特征的鲁棒性,常常采用网格技术。即统计汉字某一区域内特征的总和,这样可以削弱局部干扰。网格结构主要是等分网格和弹性网格。等分网格即是把原图像按尺寸平均分割为若干小网格,弹性网格则根据笔画密度划分原始图像。弹性网格对字符位置偏移、扭曲更加不敏感,是目前使用最多的网格结构,考虑到 “一” “l”等极端过窄字符,限制弹性网格弹力范围。

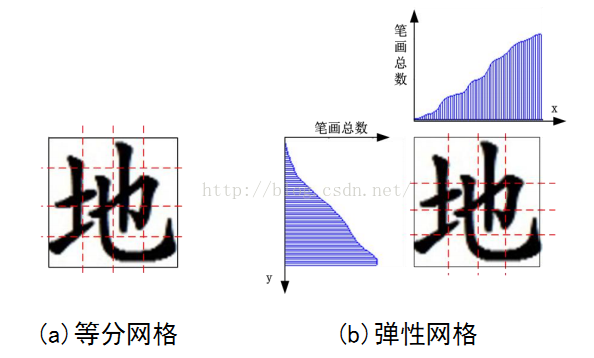
汉字的网格特征:
汉字常用特征有:粗外围特征、外轮廓特征、内轮廓特征、方向线素特征。其中粗外围、外轮廓用于粗分类,外轮廓、内轮廓、方向线素用于细分类。
1)粗外围特征
该特征用于描述汉字较粗糙的结构信息。
首先对原汉字进行细化处理,得到汉字的骨架图像。常用的图像细化算法均可,推荐使用R方法其速度较快。R算法的一个链接:http://download.csdn.net/detail/jy02660221/9584580

原图像与骨架图像
首先对骨架图像进行内部区域填充处理。若该点为白色(非笔画区域),则检测其上下左右四个方向是否有笔画,若都有笔画则认为该点为内部区域,将白色置为黑色,依次处理完所有白点。然后将填充图分成4*4共16个小块,统计每一小块黑色点数(笔画)数量,构成16维粗外围特征。特征提取示意如下。
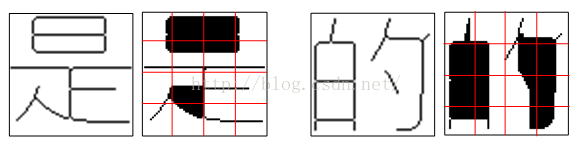
填充图及粗外围特征
2)外轮廓特征
该特征用于描述汉字外部轮廓信息。 原汉字二值图像沿上下左右 4个方向进行扫描。为了提高对字符形变的鲁棒性,本文用弹性网格对扫描区域进行划分,统计该
部分第一次碰到笔画的面积。如下图(箭头表示的扫描方向) ,每个方向被分为了 4 个区域,每个区域阴影面积即是 1维特征。那么经该处理后,得到 4*4=16 维特征。

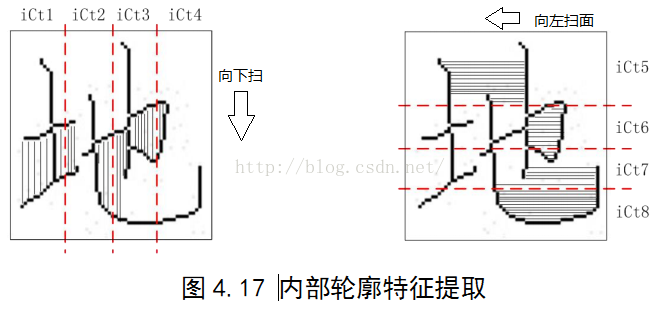
3)内轮廓特征
该特征用于描述汉字内部结构信息。对汉字细化后的骨架图像沿上下左右4个方向扫描,扫描方式同外轮廓特征提取,统计第一次穿过笔画与第二次再次碰到笔画之间的面积(下图 阴影部分,箭头表示扫描方向)。该特征描述了汉字更加细节的内部结构,特征维度为 16维。
4)方向线素特征
1.该特征用于描述汉字较细腻的笔画结构信息。对汉字原图像进行一阶微分运算,得到汉字的外部轮廓线图像,如下所示。
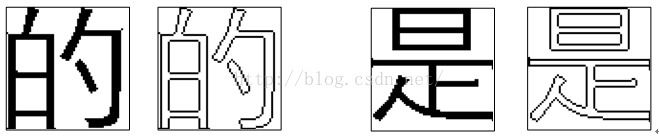
原图像与外轮廓线图像
2.把外轮廓线图像分成8*8=64个区域,统计每个小块中有效像素(笔画)的方向线素累积和。计算每个像素的方向线素:在局部区域里(3X3区域),计算中心像素的方向矢量。该矢量是4维特征,对应“横、竖、撇、捺”4个方向。即在4个方向基础上,对轮廓做顺时针跟踪,将每个方向又分成2个指向,例如:“横”可以分成“左向横”和“右向横”。在3X3邻域里包围中心点的8个像素可以产生256种组合,采用查表的方式分别给方向矢量的4个元素赋值,如下表(表中数值仅为示意,具体比例系数以程序为准)。这样共构成8*8*4=256维特征。
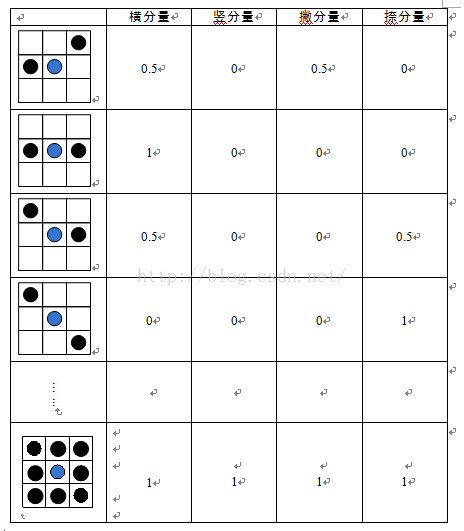
这里我们介绍了4种汉字常用特征,其中方向线素特征与梯度方向直方图很类似,可用梯度方向直方图替代,产生更精细的效果。
转载自原文链接, 如需删除请联系管理员。
原文链接:汉字常用特征的提取方法详解,转载请注明来源!