本篇主要分析网站爬虫思路,仅供个人研究分析使用。
(虽然上个月实训老师刚讲过Java的爬虫过程,但当时对爬虫只有一知半解,实在惭愧。作为第一次实战爬虫,我还是选择了比较擅长的Python。
最近实在太忙,白天一直在外面上课,只能晚上回来搞_(:з」∠)_。)
法宝网V6版地址 http://www.pkulaw.com/
1.找到登录界面,分析网页找到POST

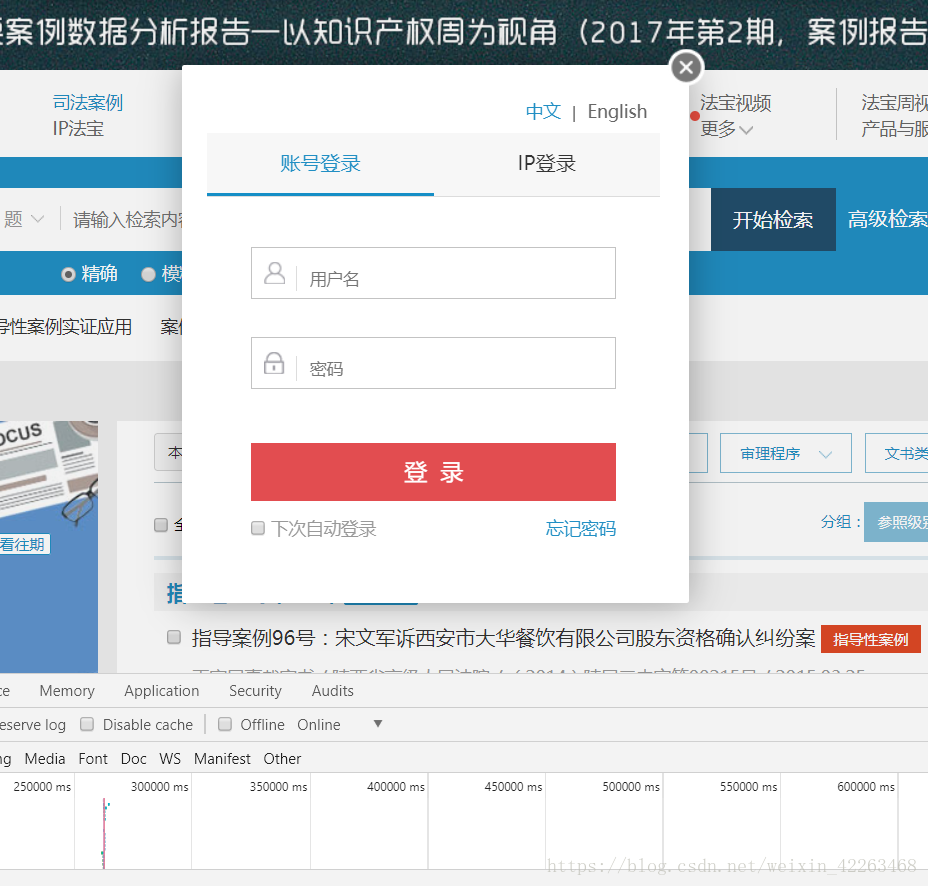

可以编码获取Cookie,我使用的是python
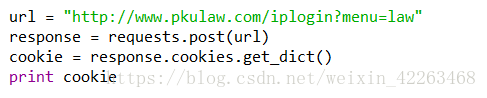
2.然后就可以在查询页面,寻找需要的文书
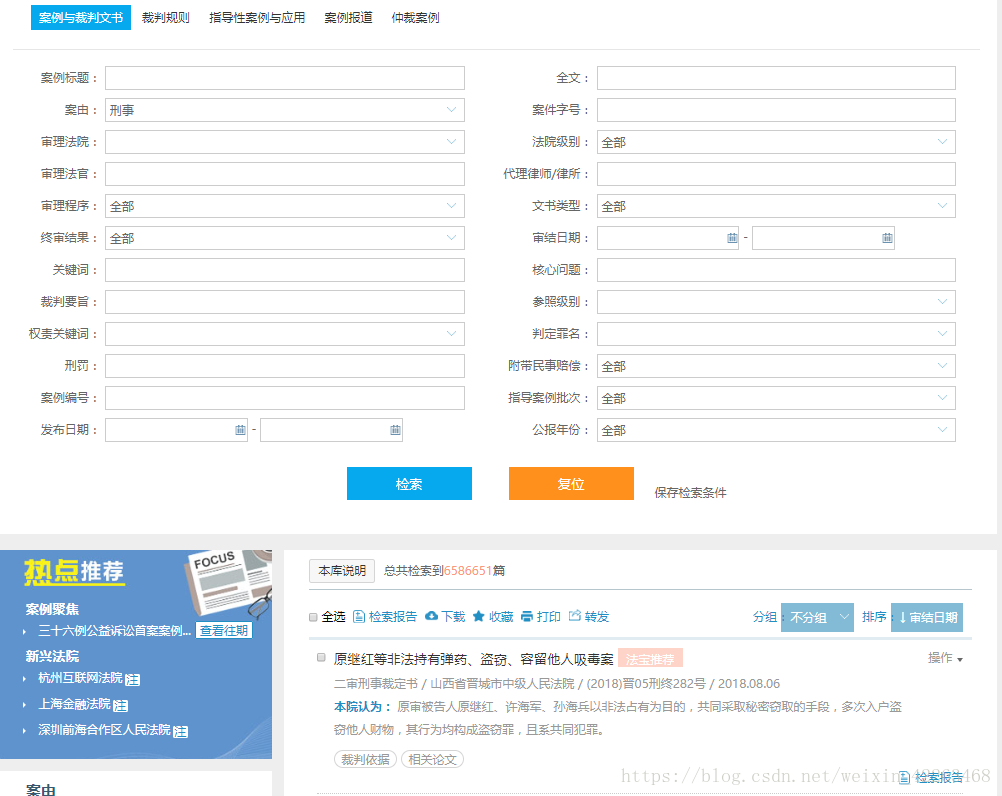
与上面的步骤一样,寻找POST网址,不同的是这里要找到format,替换关键字即可。
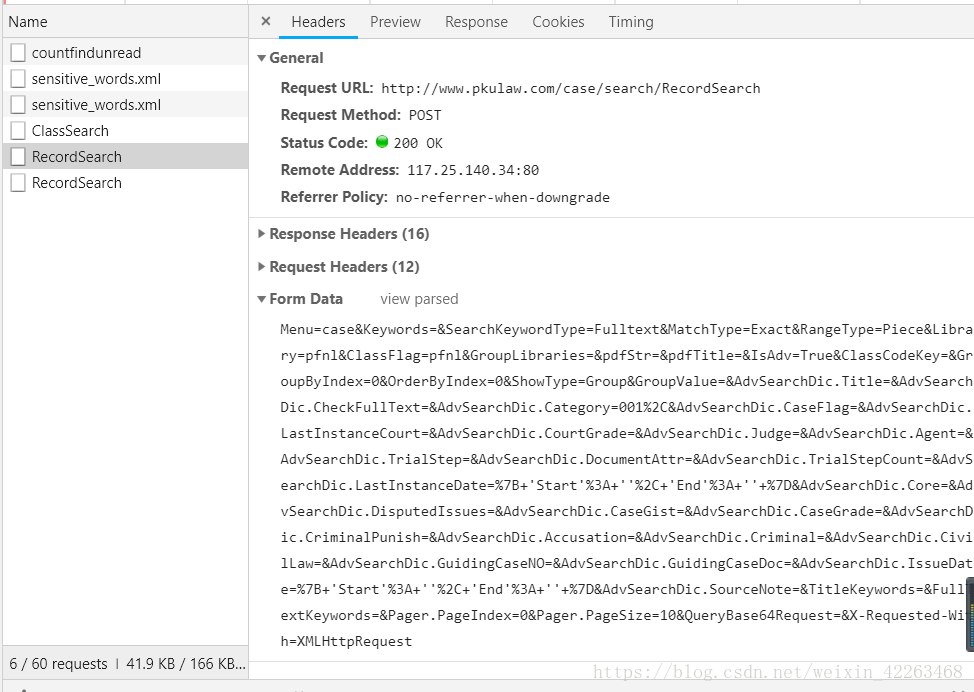
3.查询之后,我们需要通过网页源代码获取案例编号和标题
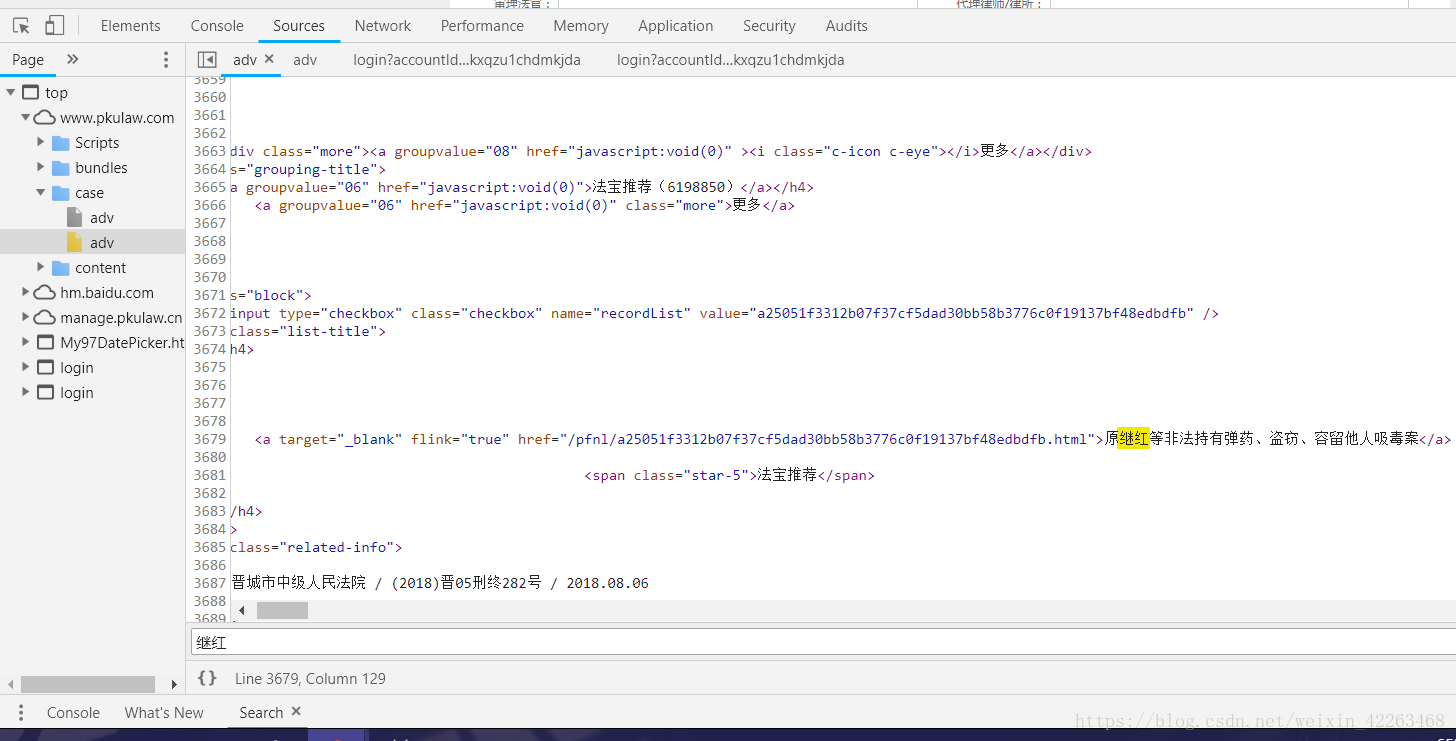
4.最后通过编号找到案例网页,爬取分析
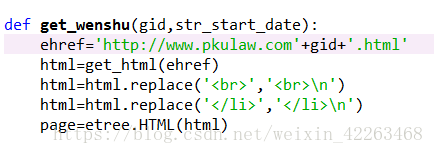
使用正则表达式获取元素,例如下面的标题获取。
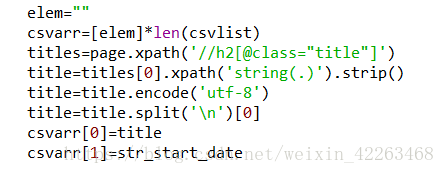
以上就是法宝网最新版网站案例的爬取过程。
其实原本是爬的V5版,已经爬了一部分,结果IP被封,只能慢慢搞,真要命,然后爬了没两天,老版V5更新网址,改动特别多,已经看不懂了=.=,本来就是第一次搞,不能再倒霉。。。只好换到V6版重新来了 囧rz
转载自原文链接, 如需删除请联系管理员。
原文链接:北大法宝网V6爬虫分析,转载请注明来源!