翻译自吴恩达的deeplearning.ai课程,及时记录下来。原网址:点击打开链接
1、残差网络(Residual Networks (ResNets))
非常非常深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸问题。这节课我们学习跳跃连接(Skip connection),它可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。我们可以利用跳跃连接构建能够训练深度网络的ResNets,有时深度能够超过100层,让我们开始吧。
ResNets是由残差块(Residual block)构建的,首先我解释一下什么是残差块。

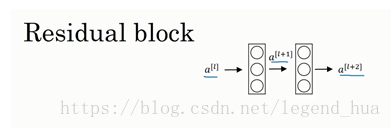
这是一个两层神经网络,在l层进行激活,得到a[l+1],再次进行激活,两层之后得到a[l+2]。计算过程是从a[l]开始,首先进行线性激活,根据这个公式:z=wx+b,通过算出z,即x(图中a[l])乘以权重矩阵w,再加上偏差因子b。然后通过ReLU非线性激活函数得到a,计算得出a[l+1]。接着再次进行线性激活,依据等式z = wx+b,最后根据这个等式再次进行ReLu非线性激活,即,这里的是指ReLU非线性函数,得到的结果就是a[l+2]。换句话说,信息流从到需要经过以上所有步骤,即这组网络层的主路径。
在残差网络中有一点变化,我们将直接向后,拷贝到神经网络的深层,在ReLU非线性激活函数前加上,这是一条捷径。a[l]的信息直接到达神经网络的深层,不再沿着主路径传递,这就意味着最后这个等式(a[l+1]=g(wa[l]+b))去掉了,取而代之的是另一个ReLU非线性函数,仍然对a[l+1]进行g函数处理,但这次要加上a[l],即:a[l+2]=g(wa[l+1]+b+a[l]),也就是加上的这个产生了一个残差块。
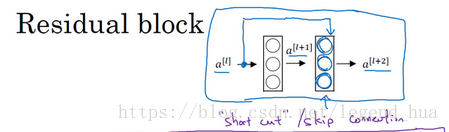
在上面这个图中,我们也可以画一条捷径,直达第二层。实际上这条捷径是在进行ReLU非线性激活函数之前加上的,而这里的每一个节点都执行了线性函数和ReLU激活函数。所以插入的时机是在线性激活之后,ReLU激活之前。除了捷径,你还会听到另一个术语“跳跃连接”,就是指跳过一层或者好几层,从而将信息传递到神经网络的更深层。
ResNet的发明者是何凯明(Kaiming He)、张翔宇(Xiangyu Zhang)、任少卿(Shaoqing Ren)和孙剑(Jian Sun),他们发现使用残差块能够训练更深的神经网络。所以构建一个ResNet网络就是通过将很多这样的残差块堆积在一起,形成一个很深神经网络,我们来看看这个网络。

这并不是一个残差网络,而是一个普通网络(Plain network),这个术语来自ResNet论文。
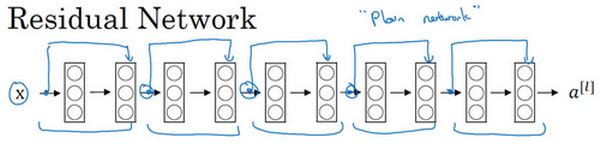
把它变成ResNet的方法是加上所有跳跃连接,正如前一张幻灯片中看到的,每两层增加一个捷径,构成一个残差块。如图所示,5个残差块连接在一起构成一个残差网络。
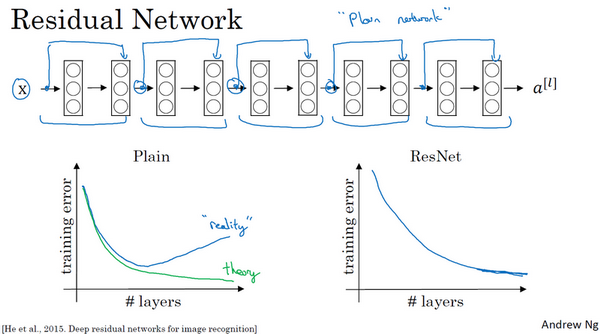
如果我们使用标准优化算法训练一个普通网络,比如说梯度下降法,或者其它热门的优化算法。如果没有残差,没有这些捷径或者跳跃连接,凭经验你会发现随着网络深度的加深,训练错误会先减少,然后增多。而理论上,随着网络深度的加深,应该训练得越来越好才对。也就是说,理论上网络深度越深越好。但实际上,如果没有残差网络,对于一个普通网络来说,深度越深意味着用优化算法越难训练。实际上,随着网络深度的加深,训练错误会越来越多。
但有了ResNets就不一样了,即使网络再深,训练的表现却不错,比如说训练误差减少,就算是训练深达100层的网络也不例外。有人甚至在1000多层的神经网络中做过实验,尽管目前我还没有看到太多实际应用。但是对x的激活,或者这些中间的激活能够到达网络的更深层。这种方式确实有助于解决梯度消失和梯度爆炸问题,让我们在训练更深网络的同时,又能保证良好的性能。也许从另外一个角度来看,随着网络越来深,网络连接会变得臃肿,但是ResNet确实在训练深度网络方面非常有效。
2、残差网络为什么有用?(Why ResNets work?)
为什么ResNets能有如此好的表现,我们来看个例子,它解释了其中的原因,至少可以说明,如何构建更深层次的ResNets网络的同时还不降低它们在训练集上的效率。希望你已经通过第三门课了解到,通常来讲,网络在训练集上表现好,才能在Hold-Out交叉验证集或dev集和测试集上有好的表现,所以至少在训练集上训练好ResNets是第一步。
先来看个例子,上节课我们了解到,一个网络深度越深,它在训练集上训练的效率就会有所减弱,这也是有时候我们不希望加深网络的原因。而事实并非如此,至少在训练ResNets网络时,并非完全如此,举个例子。
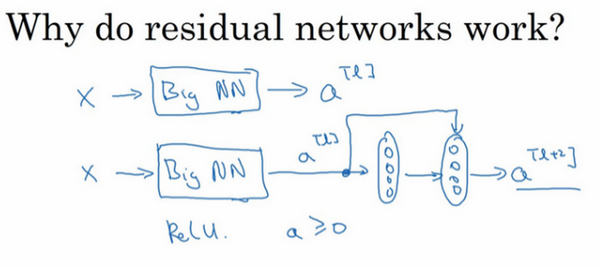
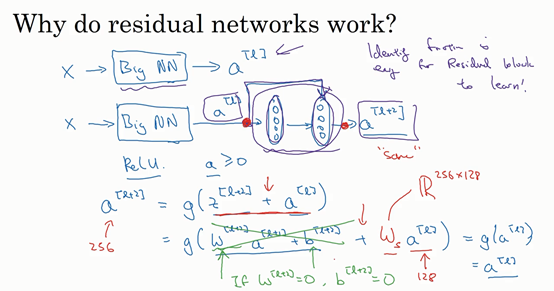
假设有一个大型神经网络,其输入为x,输出激活值。假如你想增加这个神经网络的深度,那么用Big NN表示,输出为a[l]。再给这个网络额外添加两层,依次添加两层,最后输出为a[l+2],可以把这两层看作一个ResNets块,即具有捷径连接的残差块。为了方便说明,假设我们在整个网络中使用ReLU激活函数,所以激活值都大于等于0,包括输入的非零异常值。因为ReLU激活函数输出的数字要么是0,要么是正数。
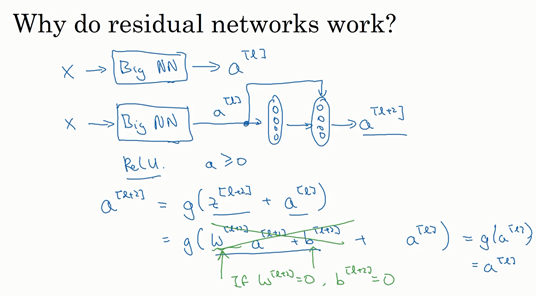
我们看一下a[l+2]的值,也就是上节课讲过的表达式,即a[l+2]=g(z[l+1]+a[l]),添加项是刚添加的跳跃连接的输入。展开这个表达式,注意一点,如果使用L2正则化或权重衰减,它会压缩w的值。如果对b应用权重衰减也可达到同样的效果,尽管实际应用中,你有时会对应用权重衰减,有时不会。这里的是关键项,如果w,为方便起见,假设w,b,这几项就没有了,因为它们的值为0。最后,因为我们假定使用ReLU激活函数,并且所有激活值都是非负的,是应用于非负数的ReLU函数,所以a[l+2]的值基本由a[l]决定。
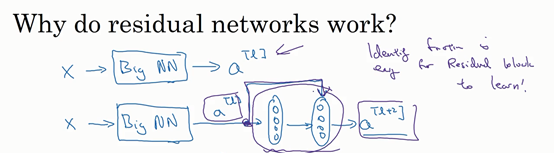
结果表明,残差块学习这个恒等式函数并不难,跳跃连接使我们很容易得出。这意味着,即使给神经网络增加了这两层,它的效率也并不逊色于更简单的神经网络,因为学习恒等函数对它来说很简单。尽管它多了两层,也只把a[l]的值赋值给a[l+2]。所以给大型神经网络增加两层,不论是把残差块添加到神经网络的中间还是末端位置,都不会影响网络的表现。
当然,我们的目标不仅仅是保持网络的效率,还要提升它的效率。想象一下,如果这些隐藏层单元学到一些有用信息,那么它可能比学习恒等函数表现得更好。而这些不含有残差块或跳跃连接的深度普通网络情况就不一样了,当网络不断加深时,就算是选用学习恒等函数的参数都很困难,所以很多层最后的表现不但没有更好,反而更糟。
我认为残差网络起作用的主要原因就是这些残差块学习恒等函数非常容易,你能确定网络性能不会受到影响,很多时候甚至可以提高效率,或者说至少不会降低网络的效率,因此创建类似残差网络可以提升网络性能。
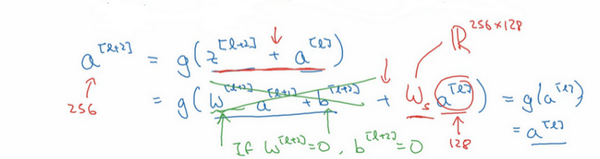
除此之外,关于残差网络,另一个值得探讨的细节是,假设与具有相同维度,所以ResNets使用了许多same卷积,所以这个的维度等于这个输出层的维度。之所以能实现跳跃连接是因为same卷积保留了维度,所以很容易得出这个捷径连接,并输出这两个相同维度的向量。
如果输入和输出有不同维度,比如输入的维度是128,的维度是256,再增加一个矩阵,这里标记为,是一个256×128维度的矩阵,所以的维度是256,这个新增项是256维度的向量。你不需要对做任何操作,它是网络通过学习得到的矩阵或参数,它是一个固定矩阵,padding值为0,用0填充,其维度为256,所以者几个表达式都可以。
最后,我们来看看ResNets的图片识别。这些图片是我从何凯明等人论文中截取的,这是一个普通网络,我们给它输入一张图片,它有多个卷积层,最后输出了一个Softmax。

如何把它转化为ResNets呢?只需要添加跳跃连接。这里我们只讨论几个细节,这个网络有很多层3×3卷积,而且它们大多都是same卷积,这就是添加等维特征向量的原因。所以这些都是卷积层,而不是全连接层,因为它们是same卷积,维度得以保留,这也解释了添加项(维度相同所以能够相加)。
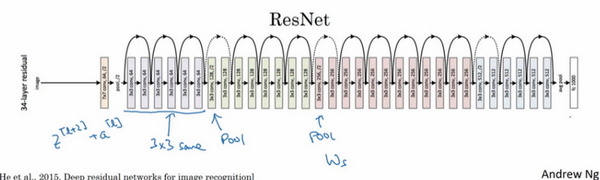
ResNets类似于其它很多网络,也会有很多卷积层,其中偶尔会有池化层或类池化层的层。不论这些层是什么类型,正如我们在上一张幻灯片看到的,你都需要调整矩阵的维度。普通网络和ResNets网络常用的结构是:卷积层-卷积层-卷积层-池化层-卷积层-卷积层-卷积层-池化层……依此重复。直到最后,有一个通过softmax进行预测的全连接层。
以上就是ResNets的内容。使用1×1的过滤器,即1×1卷积,这个想法很有意思,为什么呢?我们下节课再讲。
3、网络中的网络以及 1×1 卷积(Network in Network and 1×1 convolutions)
在架构内容设计方面,其中一个比较有帮助的想法是使用1×1卷积。也许你会好奇,1×1的卷积能做什么呢?不就是乘以数字么?听上去挺好笑的,结果并非如此,我们来具体看看。
过滤器为1×1,这里是数字2,输入一张6×6×1的图片,然后对它做卷积,起过滤器大小为1×1×1,结果相当于把这个图片乘以数字2,所以前三个单元格分别是2、4、6等等。用1×1的过滤器进行卷积,似乎用处不大,只是对输入矩阵乘以某个数字。但这仅仅是对于6×6×1的一个通道图片来说,1×1卷积效果不佳。

如果是一张6×6×32的图片,那么使用1×1过滤器进行卷积效果更好。具体来说,1×1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用ReLU非线性函数。
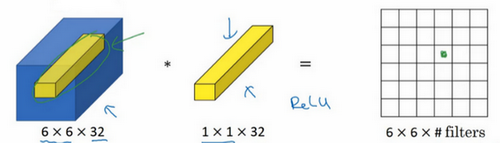
我们以其中一个单元为例,它是这个输入层上的某个切片,用这36个数字乘以这个输入层上1×1切片,得到一个实数,像这样把它画在输出中。
这个1×1×32过滤器中的32个数字可以这样理解,一个神经元的输入是32个数字(输入图片中左下角位置32个通道中的数字),即相同高度和宽度上某一切片上的32个数字,这32个数字具有不同通道,乘以32个权重(将过滤器中的32个数理解为权重),然后应用ReLU非线性函数,在这里输出相应的结果。
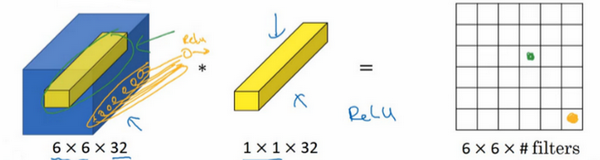
一般来说,如果过滤器不止一个,而是多个,就好像有多个输入单元,其输入内容为一个切片上所有数字,输出结果是6×6过滤器数量。
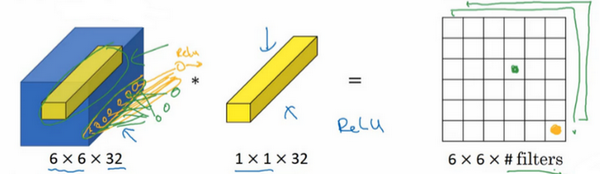
所以1×1卷积可以从根本上理解为对这32个不同的位置都应用一个全连接层,全连接层的作用是输入32个数字(过滤器数量标记为,在这36个单元上重复此过程),输出结果是6×6×#filters(过滤器数量),以便在输入层上实施一个非平凡(non-trivial)计算。
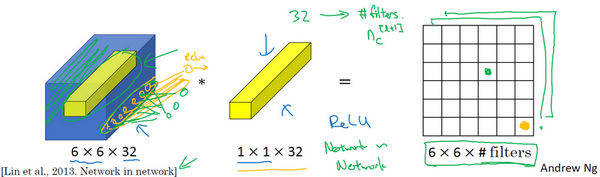
这种方法通常称为1×1卷积,有时也被称为Network in Network,在林敏、陈强和杨学成的论文中有详细描述。虽然论文中关于架构的详细内容并没有得到广泛应用,但是1×1卷积或Network in Network这种理念却很有影响力,很多神经网络架构都受到它的影响,包括下节课要讲的Inception网络。
举个1×1卷积的例子,相信对大家有所帮助,这是它的一个应用。
假设这是一个28×28×192的输入层,你可以使用池化层压缩它的高度和宽度,这个过程我们很清楚。但如果通道数量很大,该如何把它压缩为28×28×32维度的层呢?你可以用32个大小为1×1的过滤器,严格来讲每个过滤器大小都是1×1×192维,因为过滤器中通道数量必须与输入层中通道的数量保持一致。但是你使用了32个过滤器,输出层为28×28×32,这就是压缩通道数()的方法,对于池化层我只是压缩了这些层的高度和宽度。
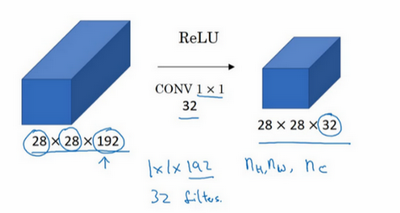
在之后我们看到在某些网络中1×1卷积是如何压缩通道数量并减少计算的。当然如果你想保持通道数192不变,这也是可行的,1×1卷积只是添加了非线性函数,当然也可以让网络学习更复杂的函数,比如,我们再添加一层,其输入为28×28×192,输出为28×28×192。
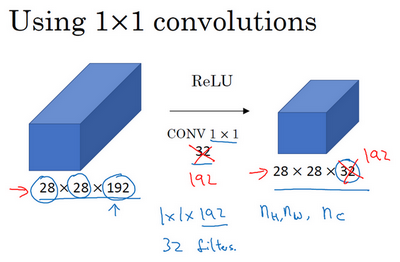
1×1卷积层就是这样实现了一些重要功能的(doing something pretty non-trivial),它给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变,当然如果你愿意,也可以增加通道数量。后面你会发现这对构建Inception网络很有帮助,我们放在下节课讲。
这节课我们演示了如何根据自己的意愿通过1×1卷积的简单操作来压缩或保持输入层中的通道数量,甚至是增加通道数量。下节课,我们再讲讲1×1卷积是如何帮助我们构建Inception网络的,下节课见。
2.6 谷歌 Inception 网络简介(Inception network motivation)
构建卷积层时,你要决定过滤器的大小究竟是1×1(原来是1×3,猜测为口误),3×3还是5×5,或者要不要添加池化层。而Inception网络的作用就是代替你来决定,虽然网络架构因此变得更加复杂,但网络表现却非常好,我们来了解一下其中的原理。
例如,这是你28×28×192维度的输入层,Inception网络或Inception层的作用就是代替人工来确定卷积层中的过滤器类型,或者确定是否需要创建卷积层或池化层,我们演示一下。
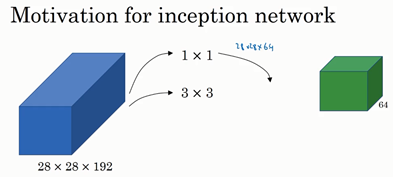
如果使用1×1卷积,输出结果会是28×28×#(某个值),假设输出为28×28×64,并且这里只有一个层。
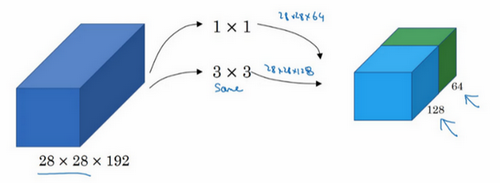
如果使用3×3的过滤器,那么输出是28×28×128。然后我们把第二个值堆积到第一个值上,为了匹配维度,我们应用same卷积,输出维度依然是28×28,和输入维度相同,即高度和宽度相同。
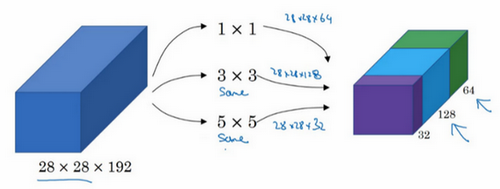
或许你会说,我希望提升网络的表现,用5×5过滤器或许会更好,我们不妨试一下,输出变成28×28×32,我们再次使用same卷积,保持维度不变。
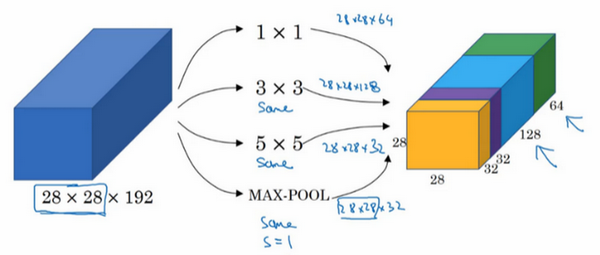
或许你不想要卷积层,那就用池化操作,得到一些不同的输出结果,我们把它也堆积起来,这里的池化输出是28×28×32。为了匹配所有维度,我们需要对最大池化使用padding,它是一种特殊的池化形式,因为如果输入的高度和宽度为28×28,则输出的相应维度也是28×28。然后再进行池化,padding不变,步幅为1。
这个操作非常有意思,但我们要继续学习后面的内容,一会再实现这个池化过程。
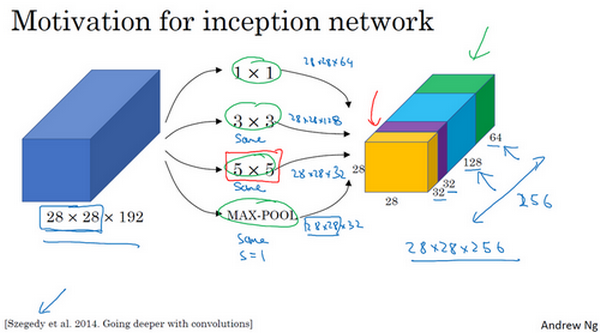
有了这样的Inception模块,你就可以输入某个量,因为它累加了所有数字,这里的最终输出为32+32+128+64=256。Inception模块的输入为28×28×129,输出为28×28×256。这就是Inception网络的核心内容,提出者包括Christian Szegedy、刘伟、贾阳青、Pierre Sermanet、Scott Reed、Dragomir Anguelov、Dumitru Erhan、Vincent Vanhoucke和Andrew Rabinovich。基本思想是Inception网络不需要人为决定使用哪个过滤器或者是否需要池化,而是由网络自行确定这些参数,你可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。
不难发现,我所描述的Inception层有一个问题,就是计算成本,下一张幻灯片,我们就来计算这个5×5过滤器在该模块中的计算成本。
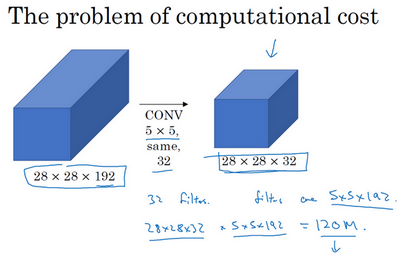
我们把重点集中在前一张幻灯片中的5×5的过滤器,这是一个28×28×192的输入块,执行一个5×5卷积,它有32个过滤器,输出为28×28×32。前一张幻灯片中,我用一个紫色的细长块表示,这里我用一个看起来更普通的蓝色块表示。我们来计算这个28×28×32输出的计算成本,它有32个过滤器,因为输出有32个通道,每个过滤器大小为5×5×192,输出大小为28×28×32,所以你要计算28×28×32个数字。对于输出中的每个数字来说,你都需要执行5×5×192次乘法运算,所以乘法运算的总次数为每个输出值所需要执行的乘法运算次数(5×5×192)乘以输出值个数(28×28×32),把这些数相乘结果等于1.2亿。即使在现在,用计算机执行1.2亿次乘法运算,成本也是相当高的。下一张幻灯片会介绍1×1卷积的应用,也就是我们上节课所学的。为了降低计算成本,我们用计算成本除以因子10,结果它从1.2亿减小到原来的十分之一。请记住120这个数字,一会还要和下一页看到的数字做对比。
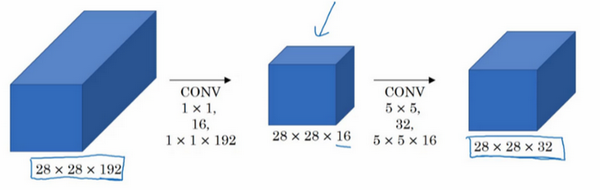
这里还有另外一种架构,其输入为28×28×192,输出为28×28×32。其结果是这样的,对于输入层,使用1×1卷积把输入值从192个通道减少到16个通道。然后对这个较小层运行5×5卷积,得到最终输出。请注意,输入和输出的维度依然相同,输入是28×28×192,输出是28×28×32,和上一页的相同。但我们要做的就是把左边这个大的输入层压缩成这个较小的的中间层,它只有16个通道,而不是192个。
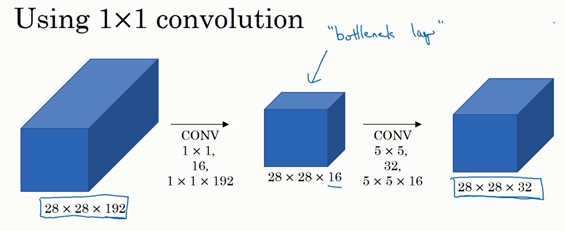
有时候这被称为瓶颈层,瓶颈通常是某个对象最小的部分,假如你有这样一个玻璃瓶,这是瓶塞位置,瓶颈就是这个瓶子最小的部分。

同理,瓶颈层也是网络中最小的部分,我们先缩小网络表示,然后再扩大它。
接下来我们看看这个计算成本,应用1×1卷积,过滤器个数为16,每个过滤器大小为1×1×192,这两个维度相匹配(输入通道数与过滤器通道数),28×28×16这个层的计算成本是,输出28×28×192中每个元素都做192次乘法,用1×1×192来表示,相乘结果约等于240万。
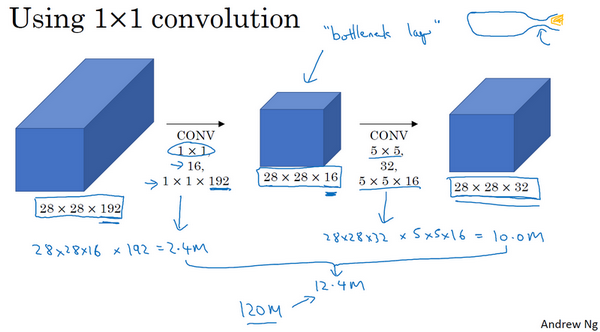
那第二个卷积层呢?240万只是第一个卷积层的计算成本,第二个卷积层的计算成本又是多少呢?这是它的输出,28×28×32,对每个输出值应用一个5×5×16维度的过滤器,计算结果为1000万。
所以所需要乘法运算的总次数是这两层的计算成本之和,也就是1240万,与上一张幻灯片中的值做比较,计算成本从1.2亿下降到了原来的十分之一,即1240万。所需要的加法运算与乘法运算的次数近似相等,所以我只统计了乘法运算的次数。
总结一下,如果你在构建神经网络层的时候,不想决定池化层是使用1×1,3×3还是5×5的过滤器,那么Inception模块就是最好的选择。我们可以应用各种类型的过滤器,只需要把输出连接起来。之后我们讲到计算成本问题,我们学习了如何通过使用1×1卷积来构建瓶颈层,从而大大降低计算成本。
你可能会问,仅仅大幅缩小表示层规模会不会影响神经网络的性能?事实证明,只要合理构建瓶颈层,你既可以显著缩小表示层规模,又不会降低网络性能,从而节省了计算。
这就是Inception模块的主要思想,我们在这总结一下。下节课,我们将演示一个完整的Inception网络。
2.7 Inception 网络(Inception network)
在上节视频中,你已经见到了所有的Inception网络基础模块。在本视频中,我们将学习如何将这些模块组合起来,构筑你自己的Inception网络。
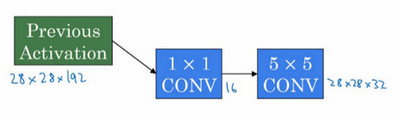
Inception模块会将之前层的激活或者输出作为它的输入,作为前提,这是一个28×28×192的输入,和我们之前视频中的一样。我们详细分析过的例子是,先通过一个1×1的层,再通过一个5×5的层,1×1的层可能有16个通道,而5×5的层输出为28×28×32,共32个通道,这就是上个视频最后讲到的我们处理的例子。
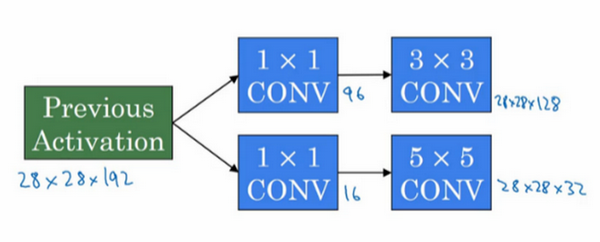
为了在这个3×3的卷积层中节省运算量,你也可以做相同的操作,这样的话3×3的层将会输出28×28×128。
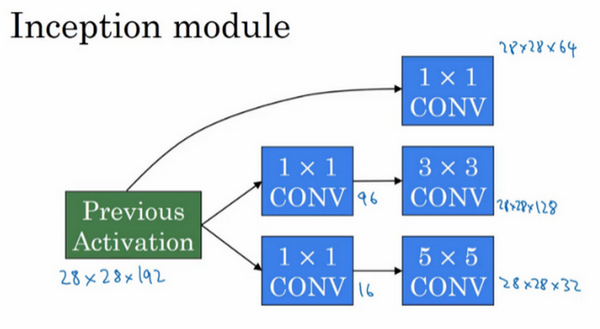
或许你还想将其直接通过一个1×1的卷积层,这时就不必在后面再跟一个1×1的层了,这样的话过程就只有一步,假设这个层的输出是28×28×64。
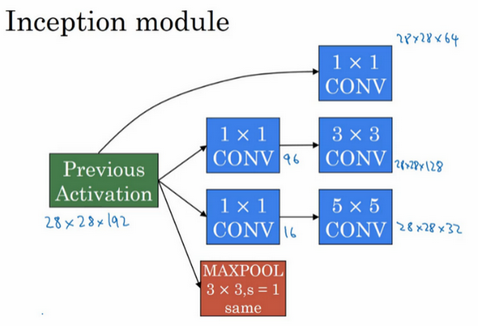
最后是池化层。
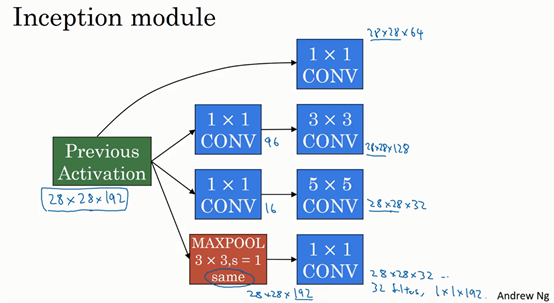
这里我们要做些有趣的事情,为了能在最后将这些输出都连接起来,我们会使用same类型的padding来池化,使得输出的高和宽依然是28×28,这样才能将它与其他输出连接起来。但注意,如果你进行了最大池化,即便用了same padding,3×3的过滤器,stride为1,其输出将会是28×28×192,其通道数或者说深度与这里的输入(通道数)相同。所以看起来它会有很多通道,我们实际要做的就是再加上一个1×1的卷积层,去进行我们在1×1卷积层的视频里所介绍的操作,将通道的数量缩小,缩小到28×28×32。也就是使用32个维度为1×1×192的过滤器,所以输出的维度其通道数缩小为32。这样就避免了最后输出时,池化层占据所有的通道。
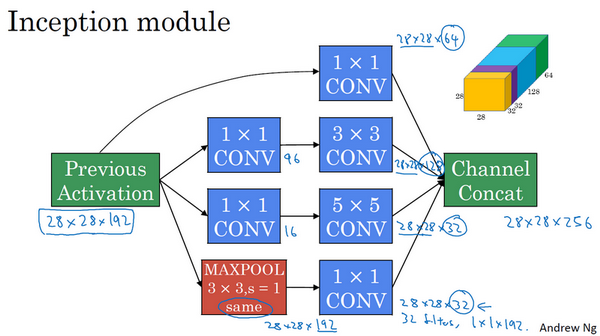
最后,将这些方块全都连接起来。在这过程中,把得到的各个层的通道都加起来,最后得到一个28×28×256的输出。通道连接实际就是之前视频中看到过的,把所有方块连接在一起的操作。这就是一个Inception模块,而Inception网络所做的就是将这些模块都组合到一起。
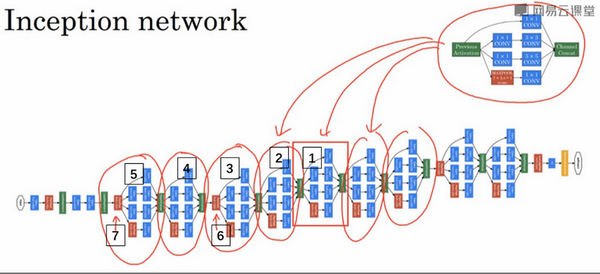
这是一张取自Szegety et al的论文中关于Inception网络的图片,你会发现图中有许多重复的模块,可能整张图看上去很复杂,但如果你只截取其中一个环节(编号1),就会发现这是在前一页ppt中所见的Inception模块。
我们深入看看里边的一些细节,这是另一个Inception模块(编号2),这也是一个Inception模块(编号3)。这里有一些额外的最大池化层(编号6)来修改高和宽的维度。这是另外一个Inception模块(编号4),这是另外一个最大池化层(编号7),它改变了高和宽。而这里又是另一个Inception模块(编号5)。
所以Inception网络只是很多这些你学过的模块在不同的位置重复组成的网络,所以如果你理解了之前所学的Inception模块,你就也能理解Inception网络。
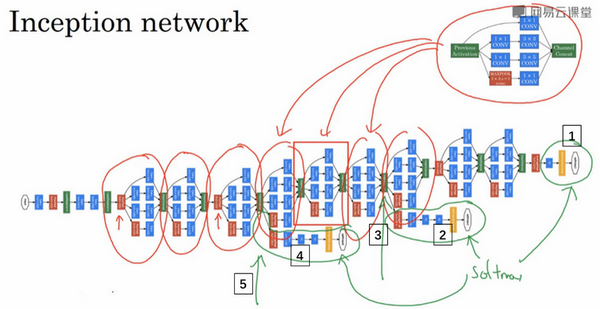
事实上,如果你读过论文的原文,你就会发现,这里其实还有一些分支,我现在把它们加上去。所以这些分支有什么用呢?在网络的最后几层,通常称为全连接层,在它之后是一个softmax层(编号1)来做出预测,这些分支(编号2)所做的就是通过隐藏层(编号3)来做出预测,所以这其实是一个softmax输出(编号2),这(编号1)也是。这是另一条分支(编号4),它也包含了一个隐藏层,通过一些全连接层,然后有一个softmax来预测,输出结果的标签。
你应该把它看做Inception网络的一个细节,它确保了即便是隐藏单元和中间层(编号5)也参与了特征计算,它们也能预测图片的分类。它在Inception网络中,起到一种调整的效果,并且能防止网络发生过拟合。
转载自原文链接, 如需删除请联系管理员。
原文链接:ResNets和Inception的理解,转载请注明来源!