一、框架介绍
上一篇从总体上介绍了推荐系统,推荐系统online和offline是两个组成部分。其中offline负责数据的收集,存储,统计,模型的训练等工作;online部分负责处理用户的请求,模型数据的使用,online learning等。因为online中有比较复杂的ranking,ranking又分为离线训练和online learning,本篇主要介绍online部分的recall,ranking部分下篇介绍。
先从整体流程图开始介绍,数据流分为两部分:
- 用户请求数据,一般是由用户下拉刷新或APP发送的默认请求,通过连接网关,请求发送到推进引擎;
- 用户产生的【隐式反馈或显示反馈】这部分数据是由APP从后台收集,通过网关进入flume,然后进入kafka为后面模块使用做准备。

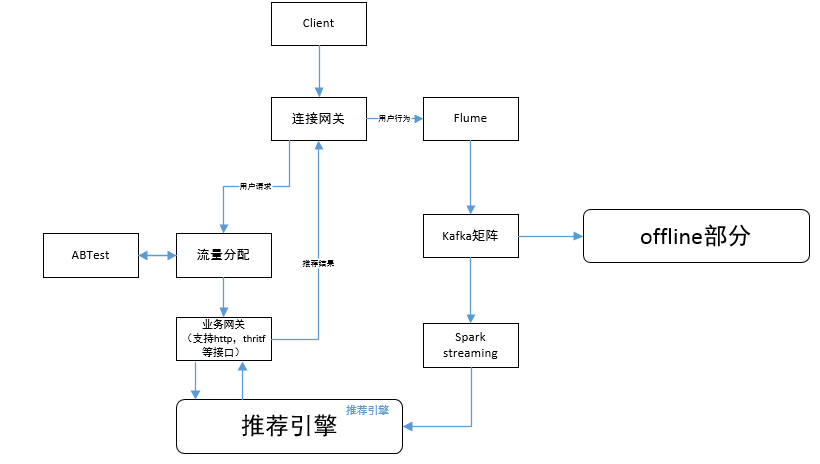
下面会根据这两部分展开讨论。
1.1 流量分配
这部分包括流量分配和ABTest两个模块,流量分配模块主要是根据需求来动态进行流量的分配,需要做到线上实时修改实时响应;ABTest是为Web和App的页面或流程设计两个版本(A/B)或多个版本(A/B/n),同时随机的分别让一定比例的客户访问,然后通过统计学方法进行分析,比较各版本对于给定目标的转化效果。你们可能觉得这两个模块功能有些冗余,其实并非如此,有一些单纯营运的需求是不需要进ABTest的。
以视频推荐为例解释一下 这个问题,假设营运有这样的需求:“他们根据数据发现,iOS用户观看视频更喜欢购买会员进行免除广告,Andriod用户更倾向于观看网剧”(当然这只是一种假设),所以iOS在进行流量分配的时候会把付费视频比例提高,而Andriod会把原创网剧比例提高。然后新的一种算法或者UI希望知道是否会表现更好,这种情况就需要进行ABTest了,对照组和实验组里面iOS和Android都是包含的。这个部分并非是推荐系统的重点,以后有机会再开专题讲ABTest,所以这里就不再详细介绍了。
1.2 推荐引擎
推荐引擎主要就包括,gateway,recall(match),ranking,其中recall主要offline通过各种算法,最经典的就是基于用户行为的矩阵分解,包括itemCF、userCF、ALS,还有基于深度学习的wise&&deep等方法,后面讲offline的时候会着重说各种算法如何使用和适合的场景。
现在我们就默认为,各种算法已经训练完毕,然后会生成一些二进制文件,如下图,这些就是offline算法收敛后的权重向量结果

文件格式都是二进制,打开我们也看不懂,这里就不打开了,如果有人好奇可以私信我。这些产生后,如何到线上使用呢?用最土的办法,通过脚本每天定时cp到线上的server。也可以通过sql或者nosql数据库等方法,但是这个文件一般比较大,图里展示的只是我其中一个实验,日活大约百万级用户的训练结果数据,如果后面用户更多,item更丰富这个文件也就越大,使用数据库是不是好方式有待商榷。
1.2.1 gateway
这个模块只要负责用户请求的处理,主要功能包括请求参数检查,参数解析,结果组装返回。gateway业务比较轻量级,其中只有一个问题就是“假曝光”,假曝光是相对真曝光而言的,真曝光是指推送给用户的内容且用户看到了,假曝光就是指,推送给用户,但是未向用户展示的内容。推荐系统为了避免重复推荐,所以基于UUID存储推荐历史,存储时间是几小时,或者1天,再或几天,这个需要根据各自的业务情况,也要考虑资源库的大小。假曝光的处理可以在gateway中,把推送的message_id在gateway写入到nosql中,然后根据真曝光数据在离线pipeline中可以获取到,在离线pipeline定时运行时把假曝光的message_id的数据归还到recall队列中。
1.2.2 recall
用户请求到recall引擎后,会根据用户行为和相关配置,启动不同的召回器,下发召回任务,用户行为只要是看是否为新用户进冷启动,相关配置可能就是地区,国家等差异。用户的userprofile如果少于几个行为,一般建议为5-10个点击行为,少于这个标准属于冷启动用户,那么在recall manager的队列里只有冷启动召回器和热门召回器。热门召回器是为了保证推荐内容的热门度,而冷启动召回器是保证推荐结果的新鲜度。recall引擎还要负责任务分配,根据推荐场景,按召回源进行任务拆分,关键是让分布式任务到达负载均衡。
在各个召回器返回后recall manager收集返回结果,也就是各个召回器的返回的message_id的倒排队列,然后再进行一次整体的ranking。

下面再展开介绍一下召回器内部框架
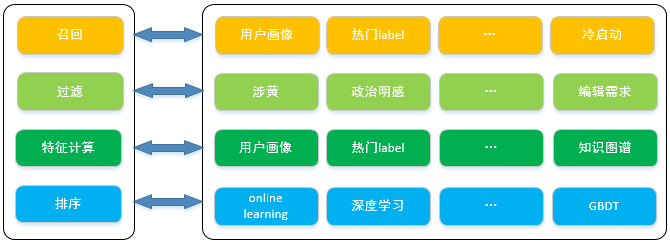
-
召回阶段,获取候选集,一般从基于用户画像、用户偏好、热门label等维度进行召回,如果是用户画像中点击少于10个会使用冷启动服务进行召回;
-
过滤阶段,基于人工规则,和政策规则,避免涉黄,避免政治明感等内容,例如最近的未成年孕妇等进行过滤,总之计算保留合法的,合乎运营需要的结果;
-
特征计算阶段,结合用户实时行为、用户画像、知识图谱,计算出召回的候选集的特征向量;
-
排序阶段,使用算法模型对召回候选集进行粗排序,因为一般用户请求10条数据,召回样本大概在200-400个所以在召回器的排序内会进行序列重新调整,然后总体ranking时会选取粗排序的前100或前200结果,并非召回结果都是用,避免不必要的计算,增加响应时间。
在召回、排序阶段都是基于message_id,并没有包含文章内容或是视频信息,这些内容会在ranking后,在detial服务中对推荐的返回结果的进行拼装,detail服务后还会有一层对整体结果的调整服务即tuner,下篇会详细介绍。
PS:最近小红和小熊都在忙着修改冷启动部分,后面会把我们的实践经验分享出来,经过了一个清明假期,更新有些晚了。
原文地址:https://www.cnblogs.com/redbear/p/8628687.html
转载自原文链接, 如需删除请联系管理员。
原文链接:B_推荐系统——online(上),转载请注明来源!