本文从深度学习角度阐述步态识别领域的近期发展与优劣,并对相关算法进行总结。
1 问题定义
1.1 任务流程
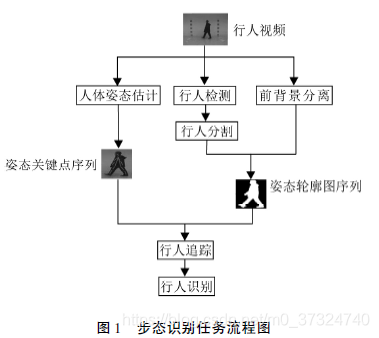
对于一段给定的包含一个或多个行人行走过程的视频序列对于一段行人视频序列,广义上的步态识别流程可以分为4 个主要阶段:
- 行人检测
- 行人分
- 行人追踪
- 行人识别
其中涉及到的一些通用的技术:
- 掩码区域卷积神经网络(He, Gkioxari, Dollár, & Girshick, 2017)
- 前背景分离技术
任务流程图如下所示:

1.2 任务类型
步态识别任务可以根据任务目标分为两类.
- 第一类为验证( Verification ) 任务
给定注册样本( Probe Sample) 和验证样本( Gallery Sample) ,依据某种相似度指标或给定的阈值判断它们是否具相同身份。
- 第二类为辨别( Identification) 任务
即给定注册样本和验证集( Gallery Set) 中N 个样本找出验证集中和注册样本具有相同身份的验证样本。
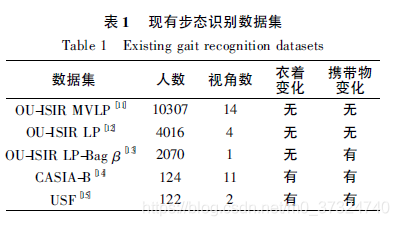
2 常用数据集:
当前的研究主要采用下图的数据集。由于人在行走过程中可能处于各种不同的状态,现有的步态识别数据集为了保证能够对算法进行有效评估,引入视角、衣着和携带物等协变量。
3 常用方法
过去的方法主要为手工提取轮廓图序列中的信息,利用机器学习方法判别。今年研究以步态模板为输入,核心在于如何提取有效的身份特征信息。
数据采取的视角是对步态是被性能影响最大的协变量。
有学者提出视角变换模型( View Transform Model)对步态模板进行视角变换的工作(Makihara, Sagawa, Mukaigawa, Echigo, & Yagi, 2006)。
有学者使用典型相关分析学习针对特定视角的投影矩阵。挖掘数据的低维几何结构,学习视角无关的判别投影矩阵(Hu, Wang, Zhang, Little, & Huang, 2013)。
有学者通过学习投影的方式将处于不同视角下的步态模板投影到一个视角无关的公共子空间中进行识别(Kusakunniran, Wu, Zhang, Li, & Wang, 2014)。
有学者提出视角变换模型( View Transform Model)对步态模板进行视角变换的工作(Makihara et al., 2006)。
等等。
传统研究对于解决不同视角下步态特征之间的高度非线性相关性依然缺乏有效的建模手段。
4 深度学习的应用
下面按照判别式模型和生成式模型两大类介绍深度学习在步态识别中的应用。
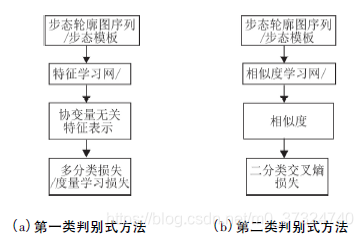
4.1 判别式
主要分为两类:
- 学习特征表示的方法
- 利用基于深度神经网络的特征学习网络建模投影f,得到低维欧氏空间中x 的协变量无关的特征表示z = f( x) ,利用学习到的特征表示z;
- 使用k 近邻分类器在验证集中找到与z 距离最近的样本.
适用于聚类或检索任务。
- 学习样本间的相似度函数
该类方法将步态识别问题看成二分类问题,即判断一个二元组步态序列是否来自于同一个对象。
训练架构图如下所示:
- 基于预训练模型
有学者利用预训练模型VRR-16得到基于步态轮廓图的深度卷积特征表示(Zhang, Sun, Li, Zhao, & Hu, 2017)。该方法在无视角变化的情况下对步态图像具有一定的泛化能力,但在跨视角场景及协变量变化时无法有效提取具有判别力的特征。
- 基于步态能量图网络
有学者使用步态能量图作为模型输入(Shiraga, Makihara, Muramatsu, Echigo, & Yagi, 2016)。
- 基于3D 卷积的方法
有学者提出利用3D卷积捕捉步态序列中的时空信息,使用多视角3D 卷积网络( Multi-view 3D Convolutional Neural Network,MV3DCNN)获取步态轮廓图的特征信息(Wolf, Babaee, & Rigoll, 2016)。为了解决卷积网络无法处理不定长步态序列的问题,将一个步态序列切分成若干个固定长度的短序列进行处理。
- 基于度量学习
有学者利用基于输入/ 输出架构的卷积神经网络( Input /Output Architectures Convolutional Neural Network,I /O-ACNN) 分析不同的网络结构和损失函数对步态识别准确率的影响(Takemura, Makihara, Muramatsu, Echigo, & Yagi, 2017)。
- 基于人体姿态关键点
有学者利用开源的姿态估计算法从原始的视频序列中提取人体的姿态信息(Liao, Cao, Garcia, Yu, & Huang, 2017),利用CNN提取关键点中的空间信息,利用LSTM提取时间信息。利用姿态关键点进行步态识别可以有效缓解协变量变化对步态识别性能的影响. 但缺点之一是未能在跨视角的场景下验证模型的有效性。
- 基于相似度学习
有学者提出通过深度卷积神经网络( Deep Convolutional Neural Networks,Deep CNNs) 直接学习步态能量图或步态序列之间的相似度(Wu, Huang, Wang, Wang, & Tan, 2017)。
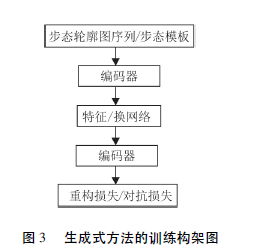
4.2 生成式
步态识别的生成式方法将某种状态下输入的步态特征变换到另一种状态下再进行匹配或特征抽取。
其训练架构图如下:
- 基于长短时记忆模块和人体关节热图
有学者提出利用基于姿态的长短时记忆模块( Pose-Based LSTM,PLSTM) 对人体关节热图序列进行端到端的重构(Feng, Li, & Luo, 2016)。使用CNN获得关节点热图,作为LSTM的输入。人体关节热图对于衣着变化等协变量的影响小于步态轮廓图,但是在于单个模型只能得到两种视角下视角不变的特征表示,无法对三个及三个以上视角下的步态序列同时进行建模。
- 基于生成对抗网络
有学者提出的基于步态生成对抗网络( Gait Generative Adversarial Network,GaitGAN) 的方法能够同时缓解视角、衣着等协变量对识别性能的影响(Yu, Chen, Reyes, & Poh, 2017)。
- 基于多层自编码
为了提高生成式的方法在步态识别中的实用,有学者提出基于多层自编码器( AutoEncoder)的统一模型,缓解步态识别中的视角、衣着、携带物等协变量改变对识别性能的影响(Yu, Chen, Wang, Shen, & Huang, 2017)。
现有的算法中,判别式算法一般准确率(90%)均大于生成式算法(60%)
5 最新的研究
复旦提出GaitSet算法(Chao, He, Zhang, & Feng, 2018),步态识别的重大突破。其核心思想在于:
人类对步态的视觉感知上,步态轮廓图从视觉上看前后关系很容易辨认。因此不再刻意建模步态轮廓图的时序关系,而将步态轮廓图当作没有时序关系的图像集,让深度神经网络自身优化去提取并利用这种关系。
参考文献
Chao, H., He, Y., Zhang, J., & Feng, J. (2018). GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition. arXiv preprint arXiv:1811.06186.
Feng, Y., Li, Y., & Luo, J. (2016). Learning effective gait features using lstm.
He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask r-cnn.
Hu, M., Wang, Y., Zhang, Z., Little, J. J., & Huang, D. (2013). View-invariant discriminative projection for multi-view gait-based human identification. IEEE Transactions on Information Forensics and Security, 8(12), 2034-2045 %@ 1556-6013.
Kusakunniran, W., Wu, Q., Zhang, J., Li, H., & Wang, L. (2014). Recognizing gaits across views through correlated motion co-clustering. IEEE Transactions on Image Processing, 23(2), 696-709 %@ 1057-7149.
Liao, R., Cao, C., Garcia, E. B., Yu, S., & Huang, Y. (2017). Pose-based temporal-spatial network (PTSN) for gait recognition with carrying and clothing variations.
Makihara, Y., Sagawa, R., Mukaigawa, Y., Echigo, T., & Yagi, Y. (2006). Gait recognition using a view transformation model in the frequency domain.
Shiraga, K., Makihara, Y., Muramatsu, D., Echigo, T., & Yagi, Y. (2016). Geinet: View-invariant gait recognition using a convolutional neural network.
Takemura, N., Makihara, Y., Muramatsu, D., Echigo, T., & Yagi, Y. (2017). On input/output architectures for convolutional neural network-based cross-view gait recognition. IEEE Transactions on Circuits and Systems for Video Technology %@ 1051-8215.
Wolf, T., Babaee, M., & Rigoll, G. (2016). Multi-view gait recognition using 3D convolutional neural networks.
Wu, Z., Huang, Y., Wang, L., Wang, X., & Tan, T. (2017). A comprehensive study on cross-view gait based human identification with deep cnns. IEEE Transactions on Pattern Analysis & Machine Intelligence(2), 209-226 %@ 0162-8828.
Yu, S., Chen, H., Reyes, E. B. G., & Poh, N. (2017). GaitGAN: Invariant Gait Feature Extraction Using Generative Adversarial Networks.
Yu, S., Chen, H., Wang, Q., Shen, L., & Huang, Y. (2017). Invariant feature extraction for gait recognition using only one uniform model. Neurocomputing, 239, 81-93 %@ 0925-2312.
Zhang, X., Sun, S., Li, C., Zhao, X., & Hu, Y. (2017). DeepGait: A Learning Deep Convolutional Representation for Gait Recognition.
转载自原文链接, 如需删除请联系管理员。
原文链接:深度学习在步态识别中的应用,转载请注明来源!