1.我的目的
- 爬取阿里小说网所有小说的内容,每本小说保存进不同的txt文件,txt文件以小说名命名
2.分析过程
- 1.书库的请求是一个普通get请求,我们解析页面可以得到每本书的id,而页码通过url的page=?来控制(https://www.aliwx.com.cn/store?spm=aliwx.list_store.0.0.345d34d4zMOmk9&page=)

- 2.有了小说的id ,我们拼接一下就能得到小说的第一页url
-
"https://www.aliwx.com.cn/reader?bid=" + str(bookID)但是这个页面并没有返回小说的内容,不过可以发现这个网页会返回所有章节的名字以及很多字符
- 3.获取每章小说的内容
-
【1】找到返回章节内容的请求

返回的章节内容是被加密的
是一个get请求,请求中有很多参数(chapterID、ver、aut、sign、num、isFree、bookid、ut),这里的参数看起来很多而且传的都是一堆奇怪的字符,但是可以发现这些参数都在第一页返回的页面中包含了;需要的就是从第一页的返回中获取每一章的所需参数然后构造成请求url。
-
【2】参数的提取:
-
[{"volumeId":"1","volumeName":"正文","volumeOrder":1,"volumeList":[{"chapterId":"1148895","chapterName":"第一章 少年唐天","payStatus":"0","chapterPrice":0,"wordCount":4446,"chapterUpdateTime":1561297065,"shortContUrlSuffix":"?bookId=7918072&chapterId=1148895&ut=1561297065&ver=1&aut=1567141687&sign=9d3ff9e33106fa1cac92a8f970218887","oriPrice":0,"contUrlSuffix":"?bookId=7918072&chapterId=1148895&ut=1561297065&num=1&ver=1&aut=1567141687&sign=ef047de9948de28d12433400793477e8","authorWordsUrlSuffix":"?bookId=7918072&chapterId=1148895&ut=1561297065&ver=1&aut=1567141687&sign=9d3ff9e33106fa1cac92a8f970218887","chapterOrdid":1,"isBuy":false,"isFreeRead":true}- 虽然看起来很复杂,单仔细看参数的结构,能够明白其格式是:
[ { 卷 [{章节}…{}]} {卷 [ {章}…{}]} {卷 [ {章}…{}] } ] (每章的参数都包含在每章{}中) - 参数:
chapterID 章节id
ver、num、ut 在一个章节{}中有多个,不过比较可以知道都是一个值
aut 作者id,获取一次即可
ifFree 是否付费
bookid 小说id,已经获取
sign 在一个章节{}中有多个,大多数情况都是最后一个,因为不知道取这个值的规律,所以默认取最后一个,如果sign校验失败,我们将对应小说章节获取失败的信息存入一个文件
- 虽然看起来很复杂,单仔细看参数的结构,能够明白其格式是:
-
【3】小说内容解密
- 这里因为给中文文本加密一般都得用到"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdef“类似这么一大段字符串,根据这个搜索可以找到这个js文件
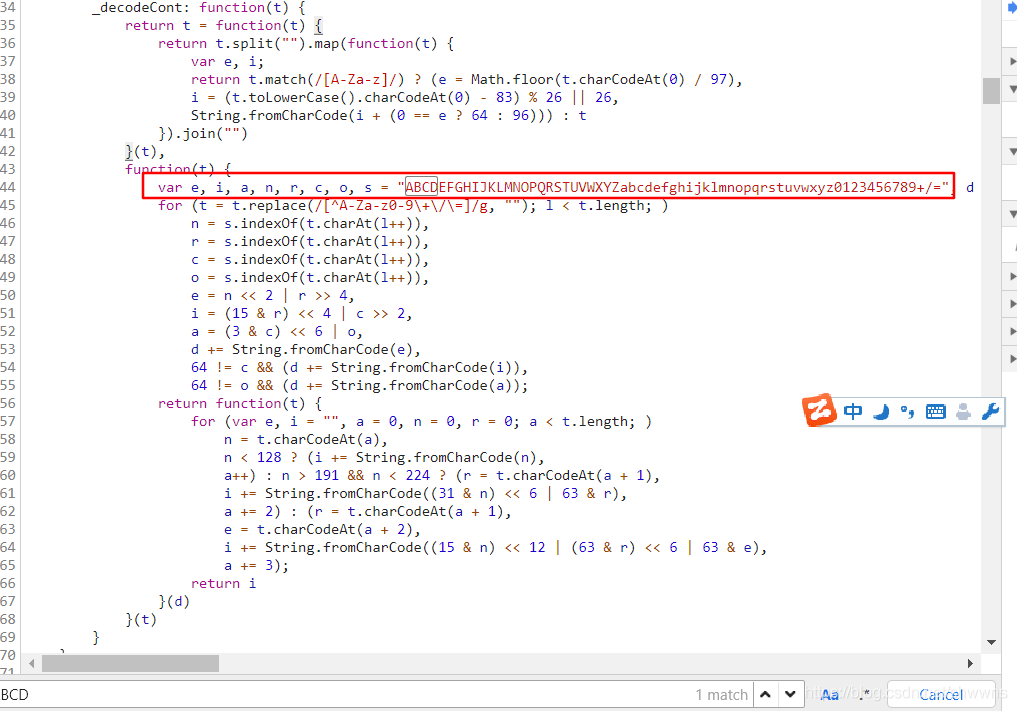
- 这里因为给中文文本加密一般都得用到"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdef“类似这么一大段字符串,根据这个搜索可以找到这个js文件
- 因为这里全是普通的js代码,我们先在webstorm中尝试下能不能得到我们想要的结果:将_decodeCont放在某个对象下,随便使用一段加密数据传入,然后调用输出结果,发现能成功解析
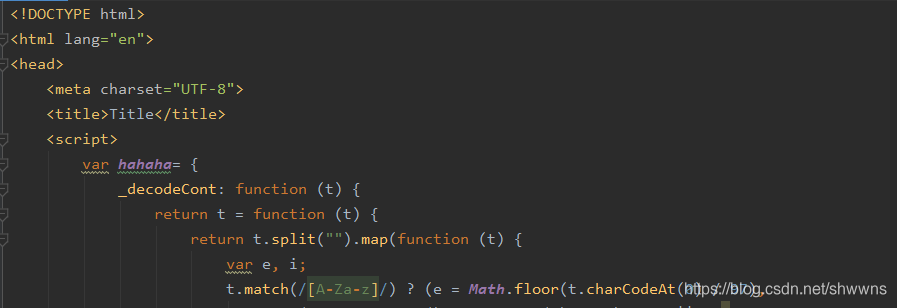
··········(复制粘贴JS文件中源代码即可)
-
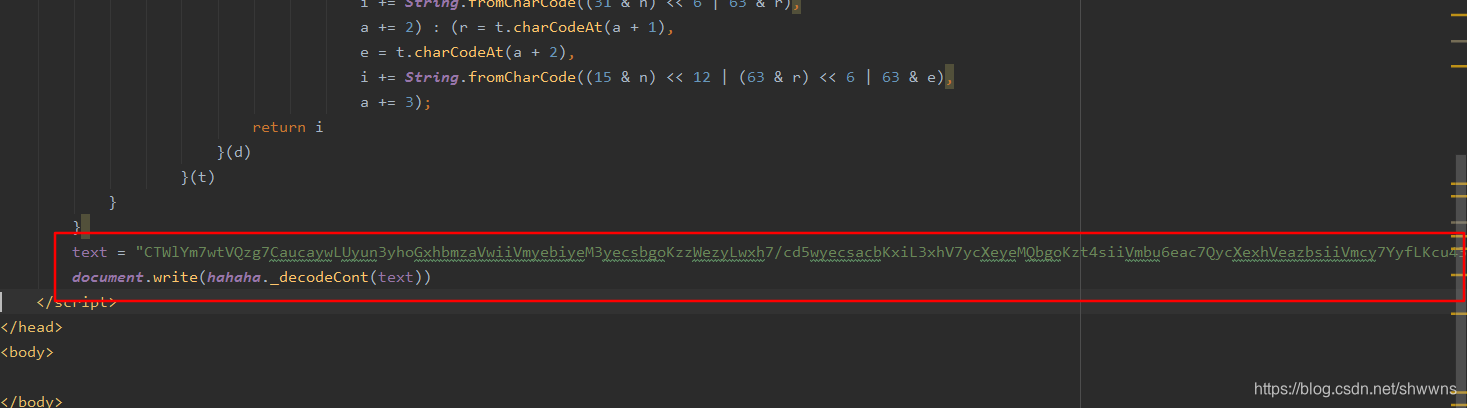
- 那我们直接在python中调用这一段JS代码就行了(import execjs)
-
js = execjs.compile(lock_content); res = js.call('hahaha._decodeCont',content)

【4】保存进txt文件
- 同一本小说保存进同一个txt文件,txt文件以小说名命名,所以前面在解析请求参数的时候,我们也要获取到小说名
【5】整个流程
- 整个流程就是:书库页面获取每一本小说的bookid----->通过bookid发送请求得到每一章节的请求参数---->请求每一章节的内容----->解密内容----->保存进对应的txt文件
3.代码
地址 : https://github.com/zkyws/spider
转载自原文链接, 如需删除请联系管理员。
原文链接:爬虫:阿里小说网所有小说的内容爬取并保存到本地文件,转载请注明来源!