网页地址:http://www.chinamoney.com.cn/chinese/zxpjbgh/?bondSrno=&tabtabNum=1&tabid=0&bnc=&ro=&sdt=&edt=
本次爬虫为的是获取该页上的评级报告。分析网页结构发现,下载链接地址是/dqs/cm-s-notice-query/fileDownLoad.do?contentId=1314388&priority=0&mode=open,我们访问需要加上http://www.chinamoney.com.cn/dqs/cm-s-notice-query/fileDownLoad.do?contentId=1314388&priority=0&mode=open,下载链接所有的结构都是一致的,关键是contentId的值是个变量。我们其实可以直接获取该页上的所有下载地址,关键是下一页的按钮,他并不是对应的一个链接,没法获取下一页的下载地址。
全代码如下:
import requests
from bs4 import BeautifulSoup
import json
import urllib.request
url='http://www.chinamoney.com.cn/ags/ms/cm-u-notice-issue/ratingAnNotice'
#获取待解析页面
headers = { 'User - Agent': 'Mozilla / 5.0(Linux;Android6.0;Nexus5Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 67.0.3396.62MobileSafari / 537.36',
'Cookie': '_ulta_id.CM-Prod.e9dc=32f79d0ff92f4484; _ulta_ses.CM-Prod.e9dc=532f9d0ef5303d0e; A9qF0lbkGa=MDAwM2IyNTRjZDAwMDAwMDAwNGYwTm0fYBExNTU5MzExMjg0',
'Referer': 'http://www.chinamoney.com.cn/chinese/zxpjbgh/?bondSrno=&tabtabNum=1&tabid=0&bnc=&ro=&sdt=&edt='}
data = { 'channelId':'2564',
'bondSrno':'',
'drftClAngl':'11',
'scnd':'1104',
'ratingOrg':'',
'bondNameCode':'',
'pageNo':'3',
'pageSize':'40',
'startDate':'2018-5-31',
'endDate':'2019-5-31',
'limit':'1',
'timeln':'1'}
start_html = requests.post(url,headers=headers,data=data)
#指定待解析页面编码
start_html.encoding='utf8'
#指定解析方式并解析
soup = BeautifulSoup(start_html.text, 'lxml')
json_text=json.loads(soup.find('p').get_text())
for record in json_text.get('records'):
print(record.get('title'))
print(record.get('releaseDate'))
print(record.get('contentId'))
file_name=record.get('title')+".pdf"
url="http://www.chinamoney.com.cn/dqs/cm-s-notice-query/fileDownLoad.do?contentId="+record.get('contentId')+"&priority=0&mode=open"
u = urllib.request.urlopen(url)
with open (file_name,"wb") as f:
f.write(u.read())
该网页是动态加载的,因此要确定数据来源,用的是火狐浏览器,显示会有一定时间的延迟,等的时间长了,可以刷新下。
截图如下:
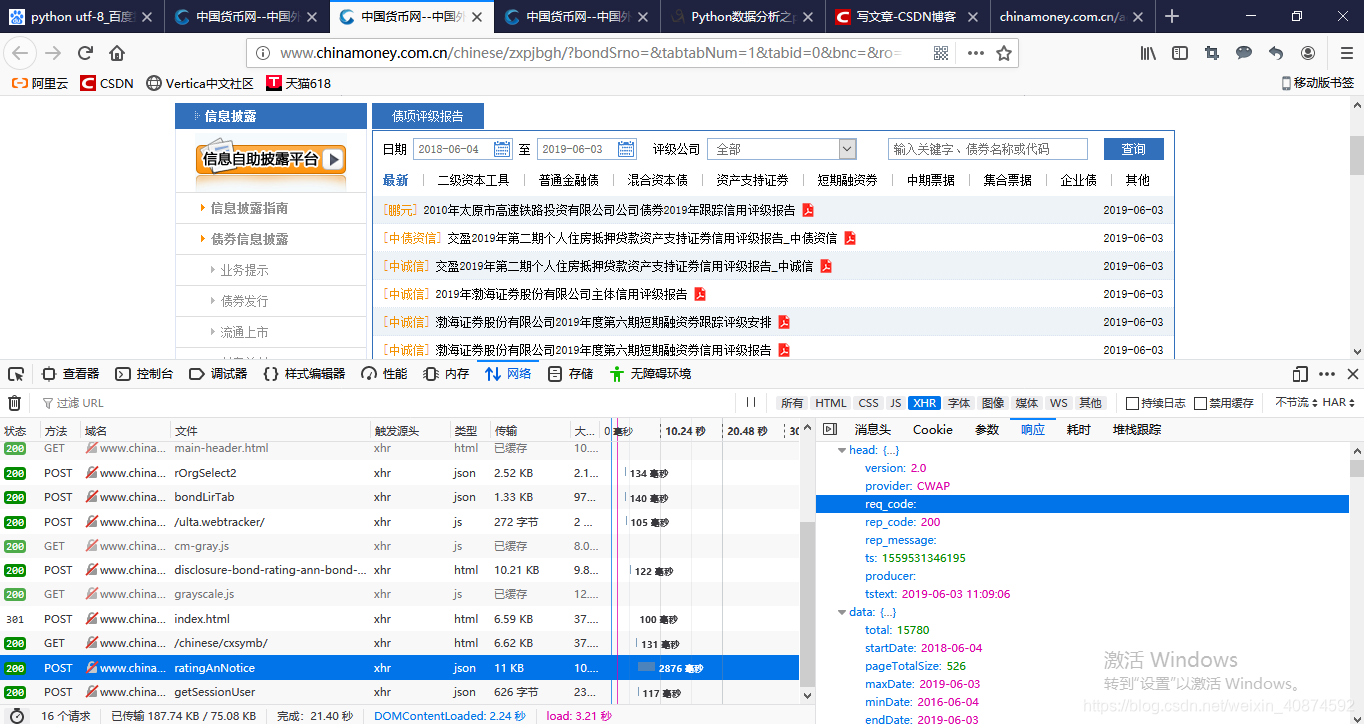 我们可以发现数据均来源于http://www.chinamoney.com.cn/ags/ms/cm-u-notice-issue/ratingAnNotice这个网址。我们直接打开这个网址,是看不到记录的,原始有些参数我们没有传进去,再看代码,将浏览器访问的请求头header与data全加进去了,结构如下:
我们可以发现数据均来源于http://www.chinamoney.com.cn/ags/ms/cm-u-notice-issue/ratingAnNotice这个网址。我们直接打开这个网址,是看不到记录的,原始有些参数我们没有传进去,再看代码,将浏览器访问的请求头header与data全加进去了,结构如下: 我们主要是获取title及contentid;整体结构是一个json字符串。json_text=json.loads(soup.find(‘p’).get_text())意为将json字符串转化为字典,获取title与contentid。data里的 ‘pageNo’:'3’与 ‘pageSize’:'40’意为将所有的文件按40条一页,下载第三页的内容,意思是下载第80条到120条的数据,
我们主要是获取title及contentid;整体结构是一个json字符串。json_text=json.loads(soup.find(‘p’).get_text())意为将json字符串转化为字典,获取title与contentid。data里的 ‘pageNo’:'3’与 ‘pageSize’:'40’意为将所有的文件按40条一页,下载第三页的内容,意思是下载第80条到120条的数据,

转载自原文链接, 如需删除请联系管理员。
原文链接:爬虫中国货币网-中国外汇交易中心,转载请注明来源!