初试爬虫,学习python也有一段时间了,想自己做个小项目实战锻炼一下,并在实战中总结。
之前在豆瓣小组找房子,由于标题信息很乱,而且要经常翻页,十分不方便,所以想做个豆瓣小组关键信息提取的程序
方便以后找房子。
所以第一步自然是先爬取信息啦。
爬取一个网页需要几步,拢共分三步:
第一步,import 一些需要的库
第二步,复制爬取的连接
第三步,稍微补充一下细节,完成!
from bs4 import BeautifulSoup #网页解析库,用于解析网页
import requests #网页请求库,联网发送网页请求
import time #定时库,用于延时
import pandas #数据分析库,用于储存爬取数据
#url = 'https://www.douban.com/group/106955/discussion?start=' #市小组
#url = 'https://www.douban.com/group/nanshanzufang/discussion?start=' #南山小组
#url = 'https://www.douban.com/group/futianzufang/discussion?start=' #福田小组
url = 'https://www.douban.com/group/baoanzufang/discussion?start=' #宝安小组
def get_page(url,data=None): #定义单页爬取函数
wb_data = requests.get(url) #发送网页请求
soup = BeautifulSoup(wb_data.text,'lxml') #使用beautifulsoup解析网页数据
titles = soup.select('td.title > a') #选取要爬取的数据,字符串内为指向内容地址的“唯一部分”
links = soup.select('td.title > a')
if data==None:
for title, link in zip(titles, links): #把上面爬取的titles和links用zip绑定到一起
data = { #单独提取titles中的title,和links中的link进行循环
'title': title.get('title'), #使用get获取网页解析数据中的文本信息
'link': link.get('href'),
}
print(data) #打印出这个字典
save_data.append(data) #将这个字典添加到save_data列表里
def get_more_pages(start,end,step=1): #定义多页爬取函数
for one in range(start,end,step): #做一个数字循环参数为,起始,结尾,和间隔
get_page(url+str(one)) #把连接和结尾的数字添加到一起作为单页链接,如果页码数据不是再结尾,需重编写这一行
time.sleep(4) #获取间隔为4s,避免频繁读取网页资料被屏蔽
save_data=[] #储存的数据,之前没有储存的数据就为空,若有则添加进去即可
get_more_pages(0,1000,25) #观察发现页码变化为每页递增25,刚好为单页内容条数
df = pandas.DataFrame(save_data,columns=['title', 'link']) #把数据修改成DateFrame的格式,并按title,和link的规律排列
df.to_excel('douban_baoan.xlsx') #输出为该名称的豆瓣xlsx文件
print(df) #顺便输出数据预览一下
哈哈哈哈,其实还可以详细一点
1、创建一个单页爬取函数
1.1、发送请求
1.2、解析网页
1.3、定位目标内容
1.4、整理数据
2、创建一个多页爬取函数
2.1、创建动态页码
2.2、调用单页爬取函数
2.3、添加延时时间
3、主函数
3.1、输入参数
3.2、把爬取的内容转成DataFrame格式并输出储存
啦啦啦啦,这是结果图。

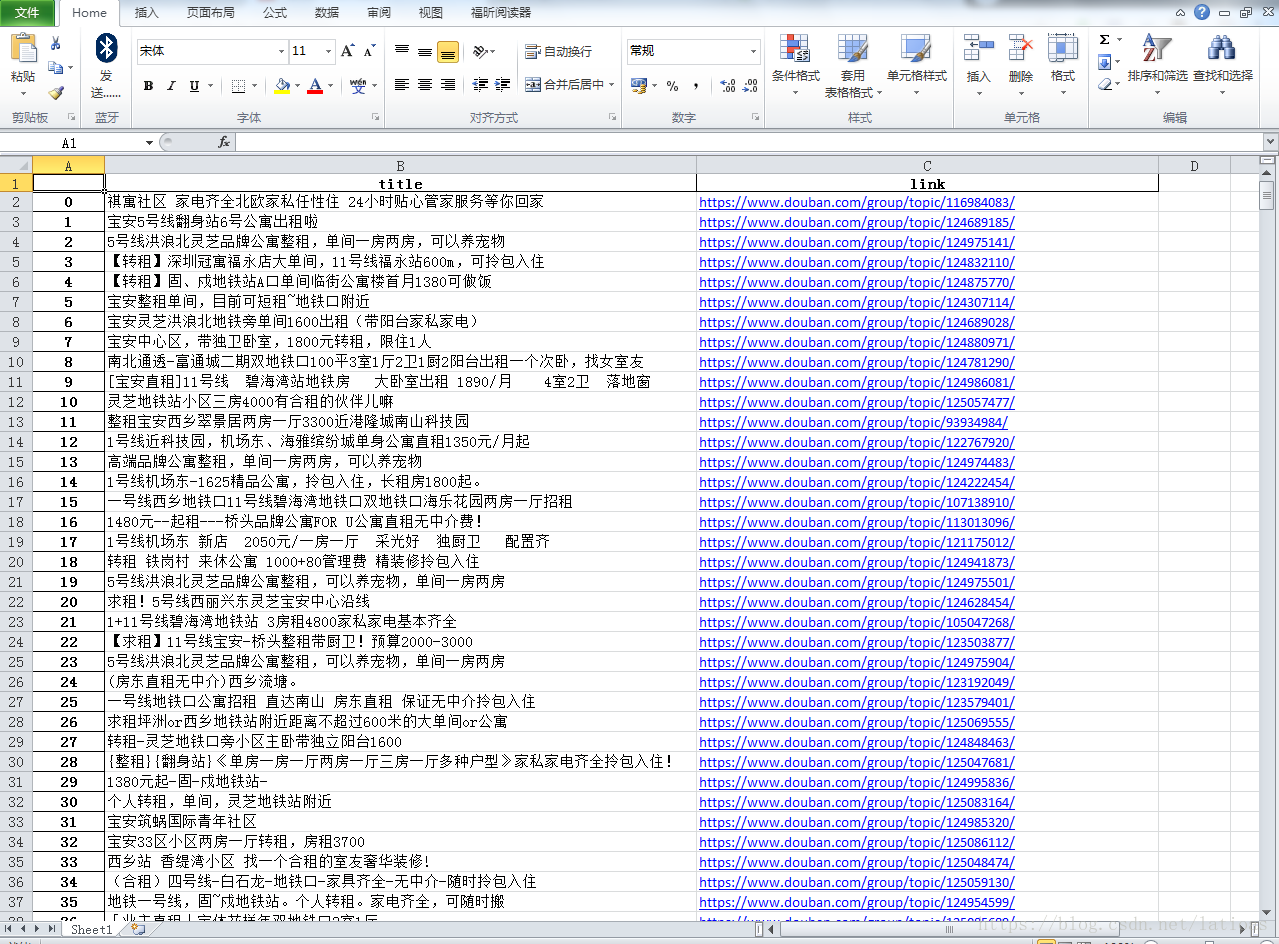
总结一下:整个过程还算比较简单,因为没有爬取图片,也没有遇到被反爬的内容,爬取的网页也是不登录,所以比较顺利。
程序虽然比较简单,但还是有优化的空间,因为在尝试爬取其他小组的时候需要修改的参数也比较多,调用起来也不是很方便,如果优化成一个总的函数那就真的是太方便了。
转载自原文链接, 如需删除请联系管理员。
原文链接:豆瓣租房爬虫,转载请注明来源!