【背景】
做市场洞察,经常需要分析某个行业的Top客户,通常会通过某种活动或某种机构获取名单。网站上也能收集到,但是手工收集比较麻烦。
下面通过Python网络爬虫 获取2018年重庆智博会参会企业的名单来体验,如何批量获取目标网页的名单。
【操作步骤】
1、分析网页的地址结构
重庆智博会官网-展览-展商名册,第一页如下:


首先分析网址:
总计27页,每页最多20个企业
第1页:https://www.smartchina-expo.cn/exhibition/roster.html
第2页:https://www.smartchina-expo.cn/exhibition/roster-page-2.html
第26页:https://www.smartchina-expo.cn/exhibition/roster-page-26.html
第27页:https://www.smartchina-expo.cn/exhibition/roster-page-27.html
从第2页到第27页,网址最后一个数字控制页数。
尝试一下第一页 也通过该规则是否ok?下面2个网页的内容是一样的,因此可以统一网址规则。
https://www.smartchina-expo.cn/exhibition/roster.html
https://www.smartchina-expo.cn/exhibition/roster-page-1.html
得出网址规则:页面数字在python代码中分别用1-27表示
https://www.smartchina-expo.cn/exhibition/roster-page-页码数字.html
2、分析网页html代码结构
找出哪个字段是提取企业名字的,用什么正则表达式来提取内容。
第一页有一个“华硕电脑”,在网页源代码中,CTRL+F,搜索到“华硕电脑”,共出现了3次。
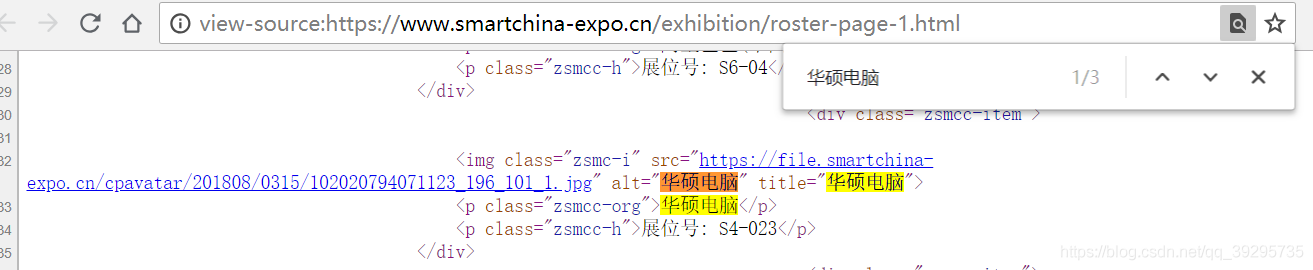
试下搜索“<p class="zsmcc-org">华硕电脑</p> ”刚好匹配出唯一一个结果。
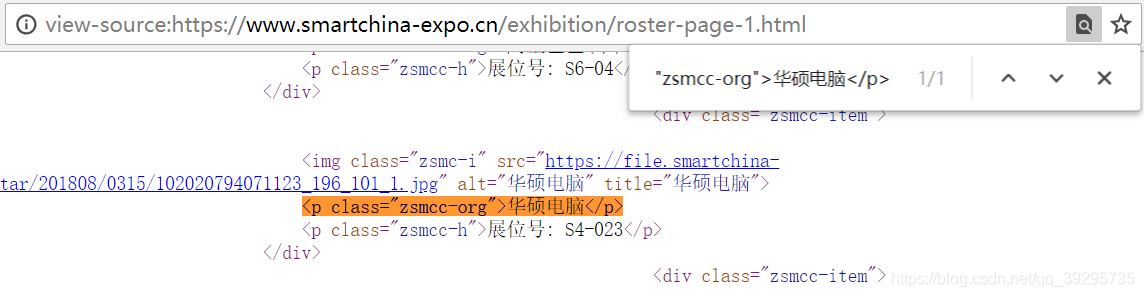
再试下搜索 <p class="zsmcc-org">,匹配出20结果,刚好就是1页中全部20家企业的名字。
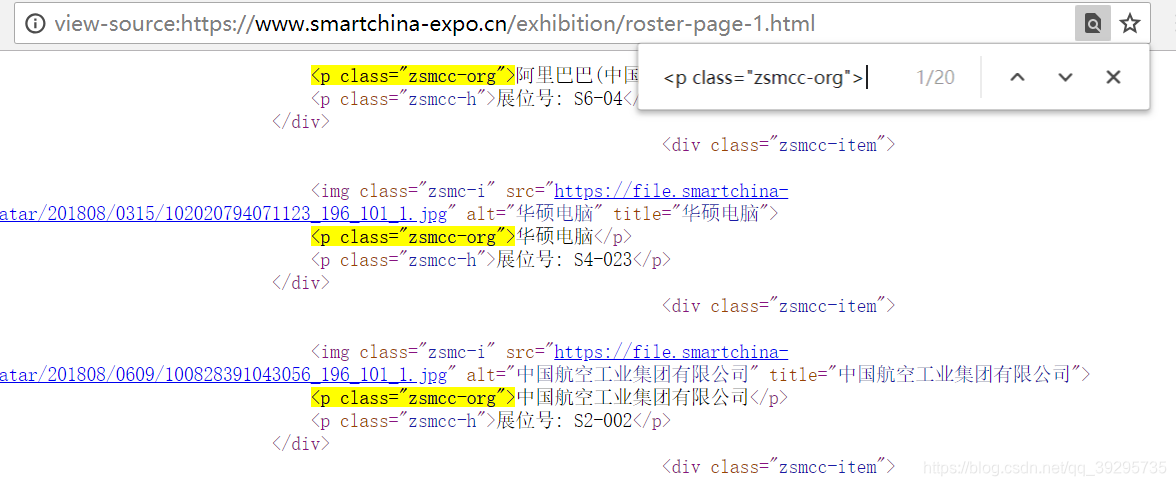
结论:通过网页标签<p class="zsmcc-org">企业名字</p>,可以将本页中所有企业名字找出来。
3、编写爬虫代码
#!/usr/bin/python3
#-*- coding: utf-8 -*-
import urllib.request
import urllib.error
import random
import re
#浏览器伪装池,将爬虫伪装成浏览器,避免被网站屏蔽
uaPools=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
#每爬取一页,就随机选取一种浏览器来伪装
def randomUA():
opener = urllib.request.build_opener()
currUA = random.choice(uaPools)
uaParm= ("User-Agent", currUA)
opener.addheaders = [uaParm]
urllib.request.install_opener(opener)
print("===模拟浏览器:"+str(currUA)+"===")
#页面数从1到27
urlPrefix = "https://www.smartchina-expo.cn/exhibition/roster-page-"
urlPostfix = ".html"
pageStartIdx = 1
pageEndIdx = 27+1 #语法原因,由于从1开始爬取,数组下标从1开始,因此最后一页码数要+1
#爬取网页上的企业名字
for pageIdx in range(pageStartIdx, pageEndIdx):
randomUA()
visitURL = urlPrefix + str(pageIdx) + urlPostfix
webData = urllib.request.urlopen(visitURL).read().decode("utf-8", "ignore")
matchPat ='<p class="zsmcc-org">(.*?)</p>'
cusName = re.compile(matchPat, re.S).findall(webData)
print("===爬取第 " +str(pageIdx)+ " 页(" + visitURL + ")的企业名单如下=====")
for nameIdx in range(0, len(cusName)):
print(cusName[nameIdx])
测试结果如下:
===模拟浏览器:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393===
===爬取第 1 页(https://www.smartchina-expo.cn/exhibition/roster-page-1.html)的企业名单如下=====
宏碁
阿里巴巴(中国)网络技术有限公司
华硕电脑
中国航空工业集团有限公司
中国宝武钢铁集团有限公司
深圳华大基因科技有限公司
京东方科技集团股份有限公司
重庆长安汽车股份有限公司
中国通信服务股份有限公司
中国建设银行
国家开发银行
中国电信集团公司
中国移动通信集团公司
保利集团
中国铁塔股份有限公司
中国联通网络通信集团有限公司
思科公司
中冶赛迪集团有限公司
重庆机电控股(集团)公司
中国石油天然气集团有限公司
===模拟浏览器:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393===
===爬取第 2 页(https://www.smartchina-expo.cn/exhibition/roster-page-2.html)的企业名单如下=====
中国中车集团有限公司
中国船舶重工集团有限公司
中软国际有限公司
浙江大华技术股份有限公司
......
转载自原文链接, 如需删除请联系管理员。
原文链接:【Python爬虫实战】获取2018年重庆智博会参会企业名单,用于市场洞察,转载请注明来源!