众所周知,深度学习属于计算密集型,模型中参数众多,占用很大的存储空间。这一特点,在嵌入式终端上应用时,因为硬件资源有限,就成了制约实际应用的瓶颈。
因此,减少模型需要的存储空间有着迫切的理论及现实意义。
深鉴科技的创始人韩松,本科毕业于清华大学,斯坦福博士,目前在MIT,一直研究深度压缩技术,并在FPGA上实现了基于深度压缩技术的ESE,成果发表为论文。
本文主要是分析韩松的2篇论文,来一窥深度压缩的玄妙。
2篇论文,一篇关于深度压缩技术,一篇关于深度压缩技术在语音识别上的FPGA方案ESE。
论文如下:
(1)Deep Compression:Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
(2)ESE:Efficient Speech Recognition Engine with Sparse LSTM on FPGA
下文首先分析深度学习技术,然后再看看深度学习技术的FPGA实现。
一、Deep Compression
论文主要介绍采用深度压缩技术存储深度学习神经网络模型的大量权重,将所需的存储空间压缩数十倍之多,并且并不损伤模型的准确性。
总体来说,深度压缩技术比较有现实意义,值得细细品味。
深度压缩技术,采用剪枝+量化+霍夫曼编码,形成三级大流水,如图1所示,实现高度压缩权重占用的存储空间。
在硬件上计算模型时,需要将经过深度压缩存储的权重值重新解压缩。
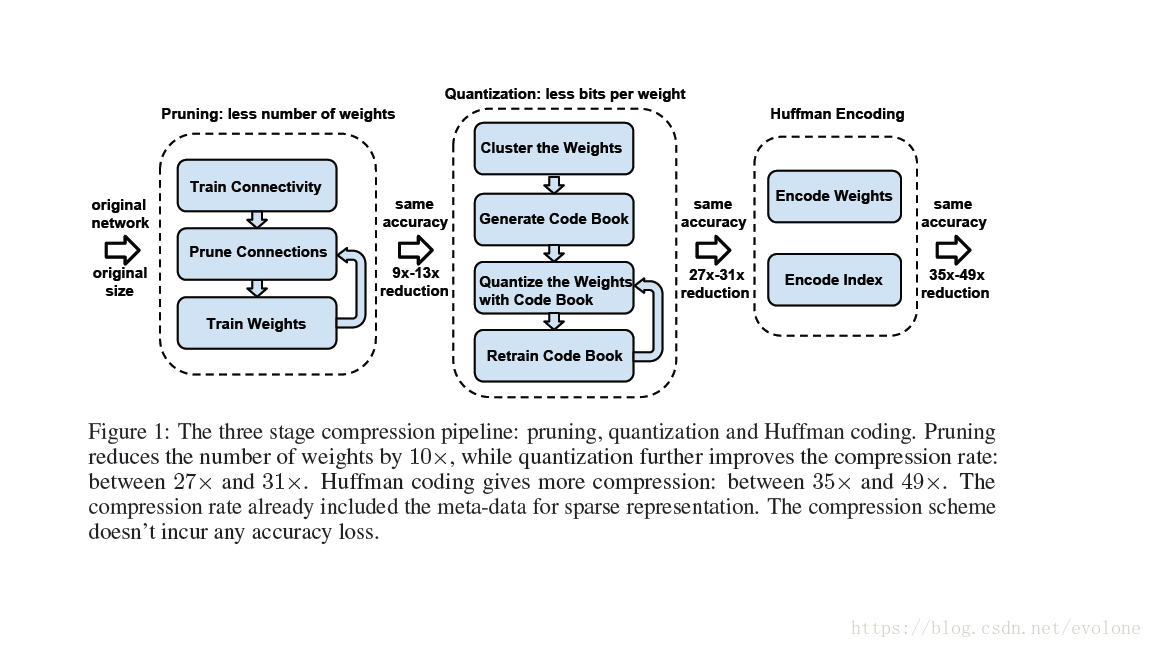
图1 三级压缩流水线
由图1可知,剪枝(pruning)会减少weights的数量,量化(quantization)会减少weights的种类,都对网络模型的准确性造成影响,因此都需要反复训练网络达到原始网络的准确精度。而霍夫曼编码(huffman encoding)并不修改weights的数量,只是改变编码方式,并不影响网络的精度。

图2压缩存储稀疏矩阵
经过剪枝和量化之后的weight矩阵,是稀疏矩阵,如果依然将矩阵的所有存元素(非0元素和0元素)都存储,那么存储空间依然和原来的一样,但是,如果只存储非0元素(可能只占总数的10%,甚至更少),就能大幅度减少存储空间,达到压缩存储的目的。
本文采用相邻非0元素之间的相对距离来存储非0元素,如图2所示。其中表格第二行diff,代表相邻非0元素之间的相对位置。这样有个缺点,就是从压缩存储的weight恢复成矩阵模样需要按顺序解码,这样解码就是串行的。另外,本文只采用3bits编码间隔,最大间隔为7,意思是说,假设相邻两个非0元素的间隔不超过是7。如果超过了7,就插入0作为中转,并记录下来。

图3 权重的量化共享
如图3所示,为training过程中计算并更新weight的过程。
首先看左侧的两个图,左上图为权重weight,左下图为梯度,都是4X4的矩阵。
观察weight矩阵的元素值,发现16个元素的取值大小其实可以划分成4个类,由四种颜色区分,相同颜色的weight用一个统一的值代表,这就是权值共享。这样可以形成一个共享weight查找表,这里因为只分成4种,故可以只用2bits去编码并替代原来的32bits的浮点数,如图3中间的cluster index所示,实际计算时,根据2bits的编码去查找正确的32bits权值。
根据左上图的四种颜色分类将左下图的梯度值按照同样的分组,将相同颜色的梯度值累加起来,然后与learning rate (lr)相乘,再与查找表中对应的weight相减,得到更新后的权值。
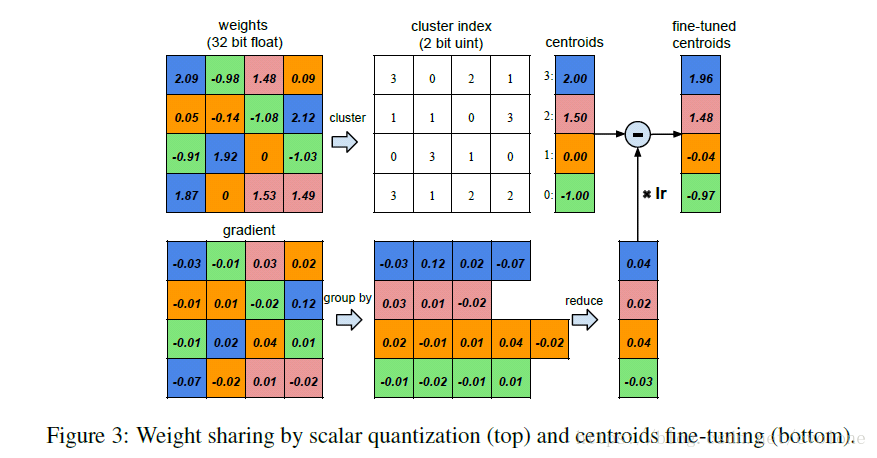
真正在计算权值的分类时,采用的是k-means聚类方法。
另外,权值的聚类分类,只在同一层layer中有效,不能跨layer共享权值。
好吧,说了这么多,那到底效果怎么样呢?
直接上图。
图4 深度压缩实验结果
可以看出,在不损失模型准确度的前提下,模型参数参数由最原始的240M压缩到6.9M,压缩率达到惊人的35倍。
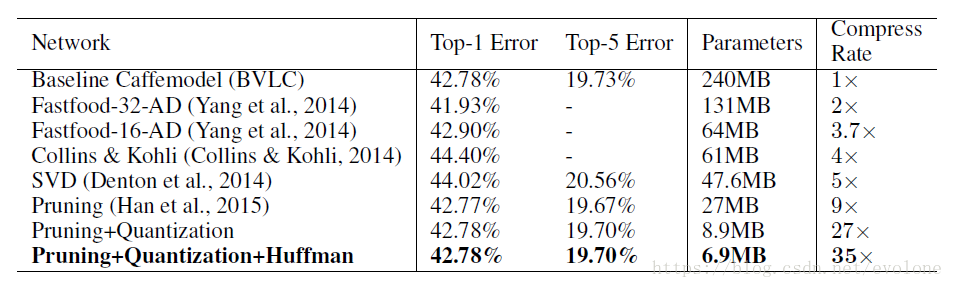
可以看出,深鉴科技的深度压缩效果还是很惊人的。
转载自原文链接, 如需删除请联系管理员。
原文链接:AI芯片:深鉴科技基于深度压缩的FPGA设计,转载请注明来源!