

import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
print('导入模块')
- 输出导入模块。则代表导入这些模块成功。
#批量获取页面,因为有好几页,所以可以把所有的网页放在一个列表里面
urllst=[]
ui='https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-'
for i in [1,2,3,4]:
u=ui+str(i)
print(u)
urllst.append(u)#append就是把每个u都添加到urlst列表中去
- 输出所有页面的网址:
https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-1
https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-2
https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-3
https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-4
#访问页面
u1=urllst[0]
u1
- 输出结果为第一个页面的网址:
‘https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-1’
r=requests.get(u1)
r
- 输出结果为:
<Response [200]>
代表向网页发送请求成功。
#解析网页,会显示网页所有代码
soup=BeautifulSoup(r.text,'lxml')
soup
- 输出结果为:
网页中的所有代码
li=ul.find_all('li')
li
- 输出结果为:
第一个网页中的所有li标签,li中是每一条数据
li[0].text#识别了第一个li里面的数据
- 输出结果为:
‘115318017上海迪士尼度假区SHDR:Shanghai Disney Resort3%去过上海迪士尼度假区的驴友来过这里上海迪士尼度假区景点排名第1中国大陆首座迪士尼度假区,身临其境地感受神奇王国’
#用字典去存储我们的数据
dic={}#先放一个空字典
li1=li[0]#获取第一个li标签
#获取经度
dic['lat']=li1['data-lat']
#获取纬度
dic['lng']=li1['data-lng']
#获取第一个li的景点名称
dic['景点名称']=li1.find('span',class_='cn_tit').text
#获取第一个li景点的攻略提到数量
dic['攻略提到数量']=li1.find('div',class_='strategy_sum').text
#获取第一个li景点的评论数量
dic['评论数量']=li1.find('div',class_='comment_sum').text
#获取第一个li景点的排名
dic['景点排名']=li1.find('span',class_='ranking_sum').text
#获取第一个li景点的星级
dic['星级']=li1.find('span',class_='total_star').find('span')['style'].split(':')[1:]
print(dic)
- 输出结果为:
{‘lat’: ‘31.146751’, ‘lng’: ‘121.669396’, ‘景点名称’: ‘上海迪士尼度假区SHDR:Shanghai Disney Resort’, ‘攻略提到数量’: ‘153’, ‘评论数量’: ‘18017’, ‘景点排名’: ‘上海迪士尼度假区景点排名第1’, ‘星级’: [‘96%’]}
#批量获取第一个网页页面的所有数据
#建立一个空的列表
datai=[]
#对每一条数据进行循环
for i in li:
dic={}#先放一个空字典
#获取经度
dic['lat']=i['data-lat']
#获取纬度
dic['lng']=i['data-lng']
#获取第一个li的景点名称
dic['景点名称']=i.find('span',class_='cn_tit').text
#获取第一个li景点的攻略提到数量
dic['攻略提到数量']=i.find('div',class_='strategy_sum').text
#获取第一个li景点的评论数量
dic['评论数量']=i.find('div',class_='comment_sum').text
#获取第一个li景点的排名
dic['景点排名']=i.find('span',class_='ranking_sum').text
#获取第一个li景点的星级
dic['星级']=i.find('span',class_='total_star').find('span')['style'].split(':')[1:]
#将所有获取的数据添加到datai中
datai.append(dic)
datai
- 输出结果为:会把第一个网页中的所有信息都输出来

#由以上可知,总共由4个网页页面,把每个网页存成一个列表
#创建一个空数据
datai=[]
n=0
#利用循环访问4个网页的数据
for ui in urllst:
print(ui)
#访问url
r=requests.get(ui)
#解析网页
soup=BeautifulSoup(r.text,'lxml')
#print(soup.h1)
ul=soup.find('ul',class_="list_item clrfix")
#获取所有的li,做一个标签的解析
li=ul.find_all('li')
#再把循环单个页面的li加入这个大循环中
for i in li:
n=n+1
dic={}#先放一个空字典
#获取经度
dic['lat']=i['data-lat']
#获取纬度
dic['lng']=i['data-lng']
#获取第一个li的景点名称
dic['景点名称']=i.find('span',class_='cn_tit').text
#获取第一个li景点的攻略提到数量
dic['攻略提到数量']=i.find('div',class_='strategy_sum').text
#获取第一个li景点的评论数量
dic['评论数量']=i.find('div',class_='comment_sum').text
#获取第一个li景点的排名
dic['景点排名']=i.find('span',class_='ranking_sum').text
#获取第一个li景点的星级
dic['星级']=i.find('span',class_='total_star').find('span')['style'].split(':')[1:]
#将所有获取的数据添加到datai中
datai.append(dic)
print('成功采集%i条数据'%n)
- 输出结果:

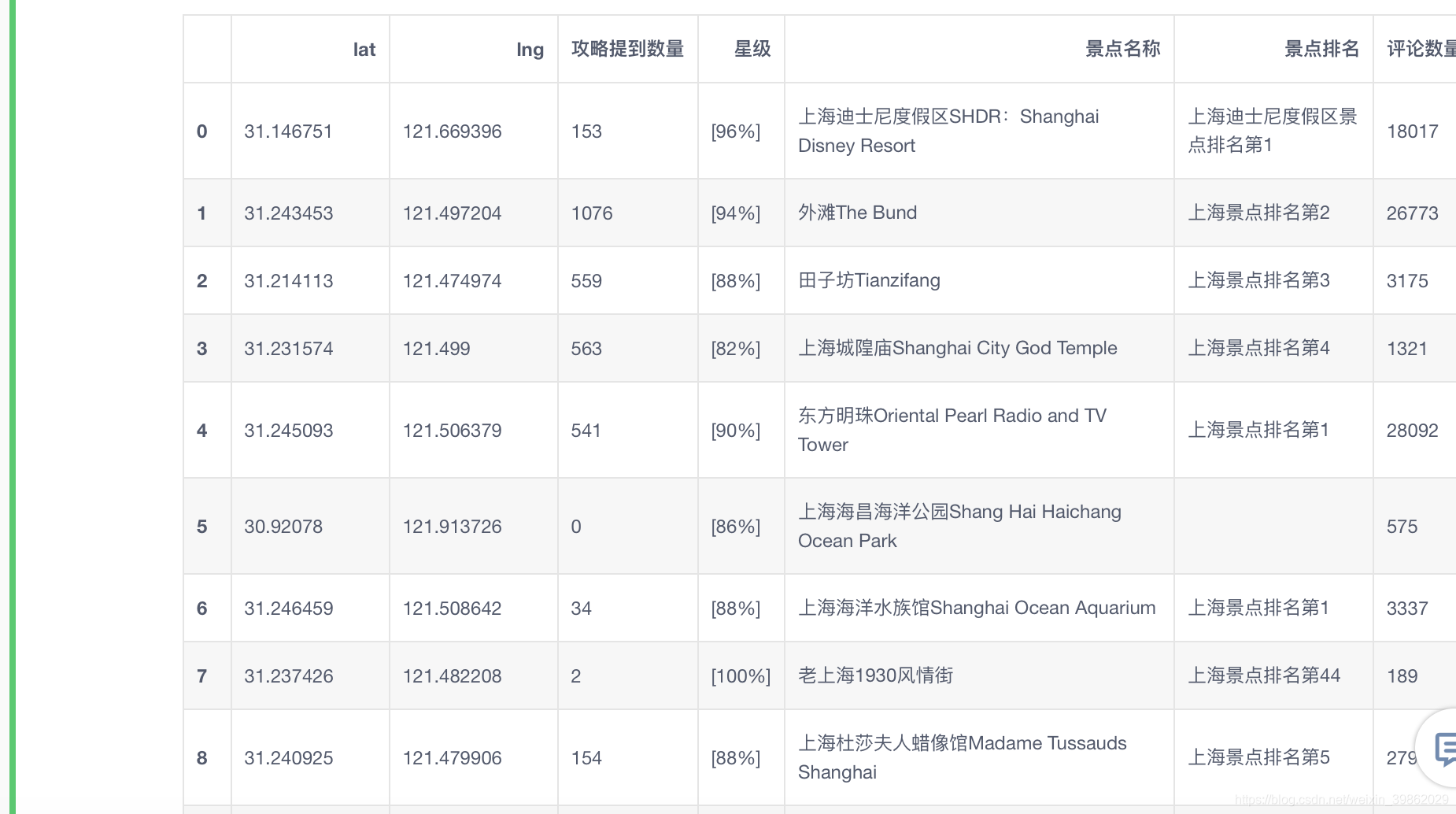
#上面做的所有都是数据的采集,下面做的则是数据的采集和清洗,用pandas来处理数据
import pandas as pd
df=pd.DataFrame(datai)
df
输出结果:
这样就完成了整个爬虫过程。
归纳爬虫步骤:
1.访问数据
2.解析数据
3.获取数据
4.存储数据
转载自原文链接, 如需删除请联系管理员。
原文链接:爬虫数据分析:上海旅游景点排名分析,转载请注明来源!