EAST:高效而准确的场景文本检测
1. 摘要
以前的场景文本检测方法已经在各种基准测试中取得了良好的效果。但是,这些方法即使使用深度神经网络模型,在处理具有挑战性的场景时也通常具有不足之处。这是因为文本检测的整体性能取决于pipelines中多个阶段和各部分的相互作用,而简单的pipeline能够集中精力去设计损失函数和神经网络结构。因此,本文提出了一个简单而强大的pipeline,可以在自然场景中进行快速准确的文本检测。该Pipeline直接预测图像中任意方向和矩形形状的文本或文本行,通过单个神经网络消除不必要的中间步骤(例如候选聚合和单词分割)。
通过ICDAR 2015,COCO-Text和MSRA-TD500的标准数据集实验表明,所提出的算法在准确性和效率方面都明显优于当前最先进的方法。在ICDAR 2015数据集中,所提出的算法在720p分辨率下以13.2fps获得0.7820的F-score。
2. 算法介绍
近年来,提取和理解在自然场景中的文本信息变得越来越重要和普遍,ICDAR系列竞赛的参与者的数量以及NIST发起的TRAIT 2016评估都证明了这一点。文本检测作为文本识别、机器翻译等后续过程的前提条件,其核心是区分文本和背景。传统方法使用手动设计特征以获得文本属性,而现在基于深度学习直接从训练数据中学习有效特征,可获得更加鲁棒的高级特征。
现有的无论是传统的还是基于深度神经网络的方法,大多由多个阶段组成,在准确性和效率还远远不能令人满意。因此,本文提出了一个快速而准确的轻量级场景文本检测pipeline,它只有两个阶段。该pipeline第一个阶段是基于全卷积网络(FCN)模型,直接产生文本框预测;第二个阶段是对生成的文本预测框(可以是旋转矩形或矩形)经过非极大值抑制以产生最终结果。该模型放弃了不必要的中间步骤,进行端到端的训练和优化。

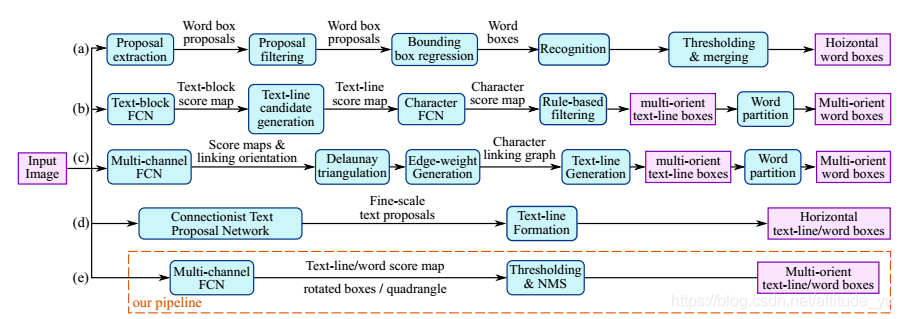
本文的贡献有三个方面:
1.提出了一个由两阶段组成的场景文本检测方法:全卷积网络阶段和NMS阶段。
2.该pipeline可灵活生成word level或line level上文本框的预测,预测的几何形状可为旋转框或水平框。
3.算法在准确性和速度上优于最先进的方法。
3. 算法框架
算法被命名为EAST(Efficient and Accuracy Scene Text),因为它是一个高效和准确的场景文本检测pipeline。
首先,将图像送到FCN网络结构中并且生成单通道像素级的文本分数特征图和多通道几何图形特征图。文本区域采用了两种几何形状:旋转框(RBOX)和水平(QUAD),并为每个几何形状设计了不同的损失函数;然后,将阈值应用于每个预测区域,其中评分超过预定阈值的几何形状被认为是有效的,并且保存以用于随后的非极大抑制。NMS之后的结果被认为是pipeline的最终结果。
3.1 网络结构
因为文本区域的大小差别很大,所以定位大文本将需要更深层的特征(大感受野),而定位小文本则需要浅层特征(小感受野)。 因此,网络必须使用不同级别的特征来满足这些要求,但是在大型特征图上合并大量通道会显着增加后期计算开销。为了弥补这一点,本文采用U-shape的思想逐步合并特征图,同时保持上采样分支较小。共同建立一个网络,既可以利用不同级别的特征,又可以节省很少的计算成本。
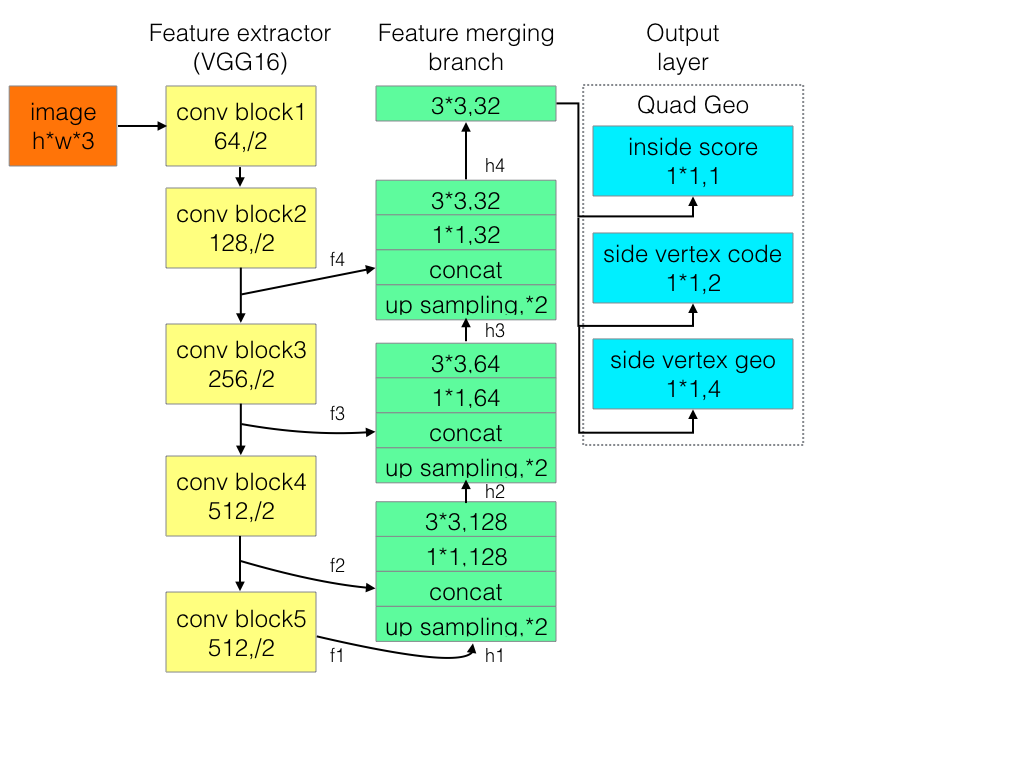
该网络结构可以分解为三个部分:特征提取,特征合并和输出层.

特征提取:首先,利用在ImageNet数据集上预训练的卷积网络参数初始化;然后,基于VGG16模型从特征提取阶段中提取四个级别的特征图(记为fi),其大小分别为输入图像的1/32 1/16 1/8和1/4。另外,提取了pooling-2到pooling-5后的特征图用于特征合并。
特征合并:逐层合并:
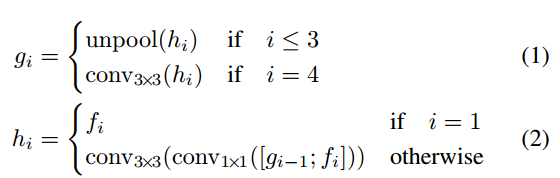
在每个合并阶段,首先,将来自上一个阶段的特征图首先被输入到一个unpooling层来扩大其大小;然后,与当前层特征图进行合并(通道);最后,通过conv1×1 减少通道数量和计算量;conv3×3,将局部信息融合以最终产生该合并阶段的输出。在最后一个合并阶段之后,conv3×3层会生成合并分支的最终特征图并将其送到输出层。
输出层:包含若干个conv1×1操作,以将32个通道的特征图投影到1个通道的分数特征图Fs和一个多通道几何图形特征图Fg。几何形状输出可以是RBOX或QUAD中的任意一种,如表所示:

其中,RBOX的几何形状由4个通道的水平边界框(AABB)R和1个通道的旋转角度θ表示;AABB 4个通道分别表示从像素位置到矩形的顶部,右侧,底部,左侧边界的4个距离;QUAD使用8个数字来表示从矩形的四个顶点到像素位置的坐标偏移,由于每个距离偏移量都包含两个数字(Δxi;Δyi),因此几何形状输出包含8个通道。
3.2 训练标签
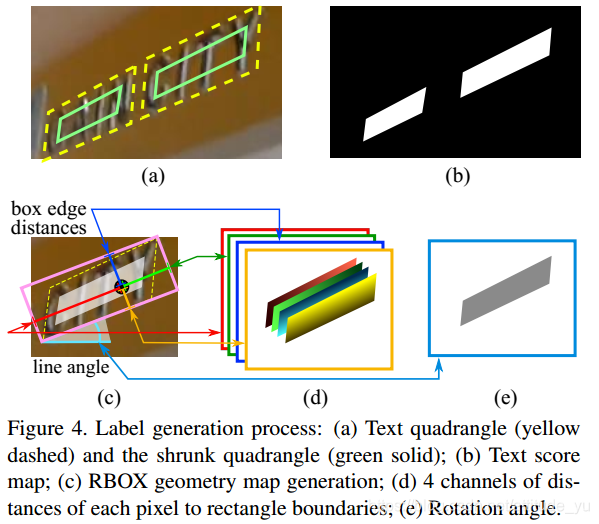
(a)文本矩形(黄色虚线)和缩小的矩形(绿色实线); (b)文本score 特征图; (c)RBOX框几何图; (d)每个像素到矩形边界的4个通道距离; (e)旋转角度。
一般将标注框缩小0.3比例的大小进行训练(减少标注误差),如图(a)所示;对于矩形Q,其中pi是顺时针顺序的矩形顶点。为了缩小Q,需要计算顶点之间的长度:
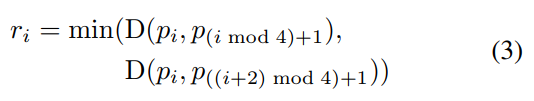
D(pi,pj)是pi和pj的L2距离,首先收缩一个矩形的两个较长边,然后缩小两个较短边。对于每一对边,通过比较长度的平均值来确定“较长”的一对。对于每条边,则通过将它的两个端点分别向内移动0.3ri和0.3r(i mod 4)+1来收缩。
首先,生成一个旋转矩形,以最小面积覆盖该区域;然后,对于RBOX标注框,计算每个有正分数的像素与文本框4个边界的距离;对于QUAD 标注框,计算每个有正分数的像素与文本框4个顶点的坐标偏移。
3.3 损失函数
损失函数公式为:

其中,Ls和Lg分别表示分数图和几何图的损失,λg表示两个损失之间的重要性(本文实验λg=1)。
目前的方法中,多数在训练图像通过均衡采样和hard negative mining,以解决目标的不均衡分布,这样做可能会提高网络性能。然而,使用这种技术不可避免地会引入一个阶段和更多的参数来调整pipeline,这与本文的设计原则相矛盾。为了简化训练过程,本文使用类平衡交叉熵(用于解决类别不平衡训练,β=反例样本数量/总样本数量),公式如下:
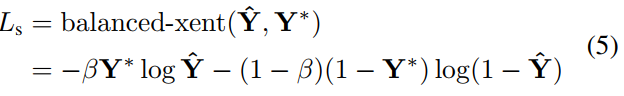
其中,Y^= Fs是分数图的预测,Y*是标注值。参数β是正和负样本之间的平衡因子,公式如下:
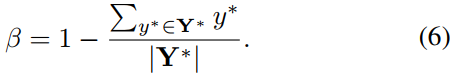
文本检测的一个挑战是自然场景图像中文本的大小差别很大,而直接使用L1或L2损失进行回归会导致损失偏向较大和较长的文本区域。因此,对于RBOX回归,采用AABB部分的IoU损失。对于QUAD回归,采用scale-normalized平滑L1损失。
RBOX损失:
RBOX 对于AABB部分使用IoU损失,因为它对不同尺寸的物体是不变的:
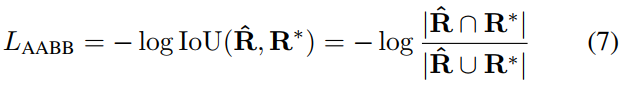
其中R^表示预测的AABB几何形状,R*是其相应的标注框。计算相交矩形的宽度和高度:
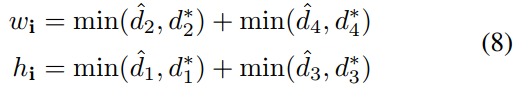
其中,d1,d2,d3和d4分别表示从一个像素到其对应矩形的顶部,右侧,底部和左侧边界的距离。并集区域公式如下:
![]()
因此,可以很容易地计算出IoU区域。接着,计算旋转角度的损失:
![]()
其中,θ^是对旋转角度的预测,并且θ*表示标注值。最后,总体几何损失是AABB损失和角度损失的加权和,公式如下:
![]()
QUAD损失:
文本矩形框的预测偏移量:
![]()
损失可以被写为:
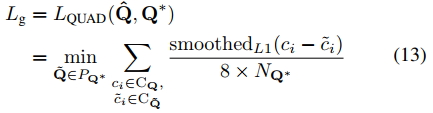
其中,归一化项NQ*是四边形的短边长度,由下式给出:
![]()
3.4 Locality-Aware NMS(局部感知NMS)
1.先对所有的output box集合结合相应的阈值(大于阈值则进行合并,小于阈值则不合并),将置信度得分作为权重加权合并,得到合并后的bbox集合;
2.对合并后的bbox集合进行标准的NMS操作。
因为本文会预测成千上万个几何框,一个简单的NMS算法的时间复杂度是O(n^2),其中n是候选框的数量,这个时间复杂度太高。所以本文提出逐行合并几何图形,假设来自附近像素的几何图形倾向于高度相关,在合并同一行中的几何图形时,将迭代合并当前遇到的几何图形与最后一个合并图形,改进后的时间复杂度为O(n)。


3.5 训练参数设置
基于Adam优化算法进行端对端训练;统一输入图像为512x512;mini-batch为24;Adam的学习速率从1e-3开始;每27300 mini-batch衰减十分之一,并停在1e-5。
4. 局限性
1. 检测器可以处理的文本实例的最大大小与网络的感受野成正比。这限制了网络预测长文本区域的能力,例如跨越图像的文本行。
2. 该算法可能会遗漏或给出不精确的垂直文本实例预测,因为它们ICDAR 2015训练集中仅有一小部分此种类型的图片。
5. 部分代码实现
#获得文本框的预测分数和几何图形
def model(images, weight_decay=1e-5, is_training=True):
'''
define the model, we use slim's implemention of resnet
'''
images = mean_image_subtraction(images)
with slim.arg_scope(resnet_v1.resnet_arg_scope(weight_decay=weight_decay)):
logits, end_points = resnet_v1.resnet_v1_50(images, is_training=is_training, scope='resnet_v1_50')
with tf.variable_scope('feature_fusion', values=[end_points.values]):
batch_norm_params = {
'decay': 0.997,
'epsilon': 1e-5,
'scale': True,
'is_training': is_training
}
with slim.arg_scope([slim.conv2d],
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params,
weights_regularizer=slim.l2_regularizer(weight_decay)):
#提取四个级别的特征图(记为fi)
f = [end_points['pool5'], end_points['pool4'],
end_points['pool3'], end_points['pool2']]
for i in range(4):
print('Shape of f_{} {}'.format(i, f[i].shape))
#基础特征图
g = [None, None, None, None]
#合并后的特征图
h = [None, None, None, None]
#合并阶段每层的卷积核数量
num_outputs = [None, 128, 64, 32]
#自下而上合并特征图
for i in range(4):
if i == 0:
h[i] = f[i]
else:
#先合并特征图,再进行1*1卷积 3*3卷积
c1_1 = slim.conv2d(tf.concat([g[i-1], f[i]], axis=-1), num_outputs[i], 1)
h[i] = slim.conv2d(c1_1, num_outputs[i], 3)
if i <= 2:
#上池化特征图
g[i] = unpool(h[i])
else:
g[i] = slim.conv2d(h[i], num_outputs[i], 3)
print('Shape of h_{} {}, g_{} {}'.format(i, h[i].shape, i, g[i].shape))
#输出层
# here we use a slightly different way for regression part,
# we first use a sigmoid to limit the regression range, and also
# this is do with the angle map
#获得预测分数的特征图,与原图尺寸一致,每一个值代表此处是否有文字的可能性
F_score = slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None)
# 4 channel of axis aligned bbox and 1 channel rotation angle
#获得旋转框像素偏移的特征图,有四个通道,分别代表每个像素点到文本矩形框上,右,底,左边界的距离
geo_map = slim.conv2d(g[3], 4, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) * FLAGS.text_scale
#获得旋转框角度特征图 angle is between [-45, 45]
angle_map = (slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) - 0.5) * np.pi/2
#按深度连接旋转框特征图和角度特征图
F_geometry = tf.concat([geo_map, angle_map], axis=-1)
return F_score, F_geometry
#获得预测得分损失
def dice_coefficient(y_true_cls, y_pred_cls,
training_mask):
'''
dice loss
:param y_true_cls:
:param y_pred_cls:
:param training_mask:
:return:
'''
eps = 1e-5
intersection = tf.reduce_sum(y_true_cls * y_pred_cls * training_mask)
union = tf.reduce_sum(y_true_cls * training_mask) + tf.reduce_sum(y_pred_cls * training_mask) + eps
loss = 1. - (2 * intersection / union)
tf.summary.scalar('classification_dice_loss', loss)
return loss
#获得总损失
def loss(y_true_cls, y_pred_cls,
y_true_geo, y_pred_geo,
training_mask):
'''
define the loss used for training, contraning two part,
the first part we use dice loss instead of weighted logloss,
the second part is the iou loss defined in the paper
:param y_true_cls: ground truth of text
:param y_pred_cls: prediction os text
:param y_true_geo: ground truth of geometry
:param y_pred_geo: prediction of geometry
:param training_mask: mask used in training, to ignore some text annotated by ###
:return:
'''
classification_loss = dice_coefficient(y_true_cls, y_pred_cls, training_mask)
# scale classification loss to match the iou loss part
classification_loss *= 0.01
# d1 -> top, d2->right, d3->bottom, d4->left
d1_gt, d2_gt, d3_gt, d4_gt, theta_gt = tf.split(value=y_true_geo, num_or_size_splits=5, axis=3)
d1_pred, d2_pred, d3_pred, d4_pred, theta_pred = tf.split(value=y_pred_geo, num_or_size_splits=5, axis=3)
#计算真实旋转框、预测旋转框面积
area_gt = (d1_gt + d3_gt) * (d2_gt + d4_gt)
area_pred = (d1_pred + d3_pred) * (d2_pred + d4_pred)
#计算相交部分的高度和宽度 面积
w_union = tf.minimum(d2_gt, d2_pred) + tf.minimum(d4_gt, d4_pred)
h_union = tf.minimum(d1_gt, d1_pred) + tf.minimum(d3_gt, d3_pred)
area_intersect = w_union * h_union
#获得并集面积
area_union = area_gt + area_pred - area_intersect
#计算旋转框IOU损失、角度 加1为了防止交集为0
L_AABB = -tf.log((area_intersect + 1.0)/(area_union + 1.0))
L_theta = 1 - tf.cos(theta_pred - theta_gt)
tf.summary.scalar('geometry_AABB', tf.reduce_mean(L_AABB * y_true_cls * training_mask))
tf.summary.scalar('geometry_theta', tf.reduce_mean(L_theta * y_true_cls * training_mask))
L_g = L_AABB + 20 * L_theta
return tf.reduce_mean(L_g * y_true_cls * training_mask) + classification_loss6. Advanced EAST
该算法所解决的问题是对长文本预测效果不好的问题。因此,对EAST的输出层结构进行修改,一个通道预测该像素是否在文本框内;两个通道预测该像素是文本框的头像素还是尾像素;四个通道预测头像素或尾像素对应的距离两个顶点坐标的偏移量。
损失函数仍使用的是EAST算法的类平衡交叉熵损失和SmoothL1损失。
参考资料:
1. https://github.com/argman/EAST
转载自原文链接, 如需删除请联系管理员。
原文链接:EAST算法详解,转载请注明来源!