完整笔记:http://www.gwylab.com/note-gans.html
———————————————————————
3. 如何解决BIG TRANSFORMATION
我们前面提到的风格转换都是比较小幅度的风格转换,有的时候我们会需要做非常大的风格转换,譬如把真人照片转成动漫照片。大风格的转换我们容易想到的一个思路是auto-encoder:

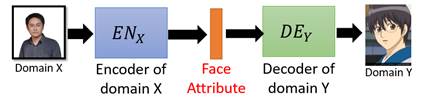
也就是说,输入一个真人的照片,通过一个encoder提取出它的人脸特征,再放入到一个decoder中输出一张动漫人物的照片,这两张照片的差异是可以非常大的。
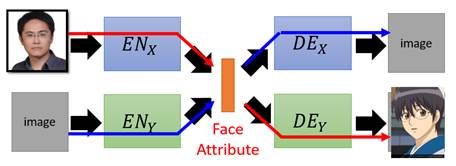
现在我们进一步希望,x domain和y domain的照片能够相互转换,于是我们再增添一个auto-encoder:

这意味着,输入x domain的图片就放入x encoder中,输入y domain的图片就放入y encoder中,它们都能提取出对应的人脸特征,然后如果需要输出x domain的图片就把特征放入x decoder中, 如果需要输出y domain的图片就把特征放入y decoder中,这样就能实现在两个domain间的相互转换。
当然上述我们希望这个模型具有的功能是在x domain和y domain之间互换,也就是图片的训练路径是![]() ->
->![]() ->
->![]() ->
->![]() 和
和![]() ->
->![]() ->
->![]() ->
->![]() 。
。
那如果仅仅是按照这样的路径训练的话,![]() 与
与![]() 完全没有关系,
完全没有关系,![]() 与
与![]() 也完全没有关系,事实上它就等价于两个单独训练的auto-encoder。为了改善这一模型,我们可以增添两条训练路径,如下图所示:
也完全没有关系,事实上它就等价于两个单独训练的auto-encoder。为了改善这一模型,我们可以增添两条训练路径,如下图所示:
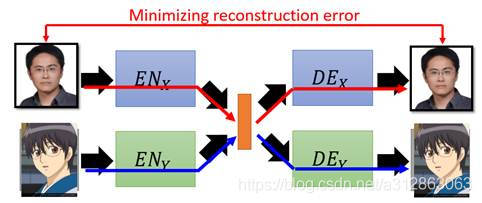
在这两种路径下,一张图片会进入同一个domain的encoder和decoder,我们希望最终输出的图片能和原始图片越相似越好。但是仅仅只有minimize reconstruction是不够的,我们还希望输出的图片尽可能清晰,于是分别加入一个discriminator。
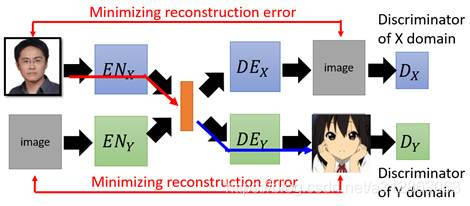
这样在这种训练路径下,模型产生的图片就既和原图比较相似也有着尽可能高的清晰度。但是现在还需要考虑一个新的问题,就是模型目前只能保证一张图片![]() 走
走![]() 和
和![]() 这条路,或者一张图片
这条路,或者一张图片![]() 走
走![]() 和
和![]() 这条路,能够产生和原图高度相似(这儿的相似是要求像素无差)的图片,但是模型不能保证,一张图片
这条路,能够产生和原图高度相似(这儿的相似是要求像素无差)的图片,但是模型不能保证,一张图片![]() 走
走![]() 和
和![]() 这条路产生的图片和原图
这条路产生的图片和原图![]() 是相似的(这儿的相似是要求看着像同一个人,通常输出会很清楚但明显不是同一个人)。这是因为,domain x和domain y的差异很大,
是相似的(这儿的相似是要求看着像同一个人,通常输出会很清楚但明显不是同一个人)。这是因为,domain x和domain y的差异很大,![]() 与
与![]() 学到的特征提取方法也会不一样,譬如
学到的特征提取方法也会不一样,譬如![]() 用第1,2维提取头发和眼睛信息,但是
用第1,2维提取头发和眼睛信息,但是![]() 用3,4维提取头发和眼镜信息,这样
用3,4维提取头发和眼镜信息,这样![]() 在解
在解![]() 提取的特征信息时就会提取出错误的特征信息。那在文献上为了解决这个问题,出现了各式各样的解法,下面会一一介绍。
提取的特征信息时就会提取出错误的特征信息。那在文献上为了解决这个问题,出现了各式各样的解法,下面会一一介绍。
3.1 CoGAN
CoGAN(又称CoupledGAN)采用了一个最直接的解决思路,既然错误的出现是![]() 和
和![]() 的差异导致的,那我何不让
的差异导致的,那我何不让![]() 和
和![]() 尽可能地相似?具体来说,就是让
尽可能地相似?具体来说,就是让![]() 和
和![]() 的输出尽可能地相似。那为了让二者输出尽可能相似,CoupleGAN便让
的输出尽可能地相似。那为了让二者输出尽可能相似,CoupleGAN便让![]() 和
和![]() 的最后几层的参数是共享的,也就是
的最后几层的参数是共享的,也就是![]() 和
和![]() 的最后几层hidden layer是完全一样的,这样它们提取出的脸部特征(下称face attribution)在结构上就非常相似。同理,既然face attribution差不多了,
的最后几层hidden layer是完全一样的,这样它们提取出的脸部特征(下称face attribution)在结构上就非常相似。同理,既然face attribution差不多了,![]() 和
和![]() 的前面几层参数也是共享的。
的前面几层参数也是共享的。
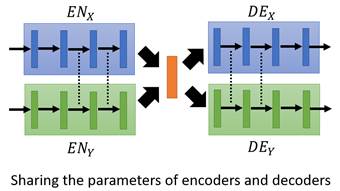
CoGAN有一种极端的情况,就是![]() 和
和![]() 的所有参数都共享,只是额外的增加一个输入变量0或1,1表示输入来自x domain,0表示输入来自y domain。在这种情况下,
的所有参数都共享,只是额外的增加一个输入变量0或1,1表示输入来自x domain,0表示输入来自y domain。在这种情况下,![]() 和
和![]() 可以合并为一个encoder。
可以合并为一个encoder。
3.2 Guillaume Lample
我们的目的,实质上是希望![]() 和
和![]() 产生的face attribution尽可能一致,那Guillaume Lample方法就是给face attribution增添一个discriminator,去判断这个face attribution是来自于x domain还是y domain,那
产生的face attribution尽可能一致,那Guillaume Lample方法就是给face attribution增添一个discriminator,去判断这个face attribution是来自于x domain还是y domain,那![]() 和
和![]() 为了骗过这个discriminator,就会产生尽可能一致的face attribution,这样discriminator就无法判断出
为了骗过这个discriminator,就会产生尽可能一致的face attribution,这样discriminator就无法判断出![]() 和
和![]() 输出结果的差异。
输出结果的差异。

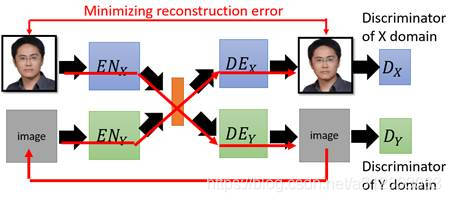
3.3 ComboGAN
实际上,从![]() 和
和![]() 产生的图片或者从
产生的图片或者从![]() 和
和![]() 产生的图片无法和原图相似的本质原因,是特征信息的丢失。那我们现在把两条路拼在一起,形成一个
产生的图片无法和原图相似的本质原因,是特征信息的丢失。那我们现在把两条路拼在一起,形成一个![]() ->
->![]() ->
->![]() ->
->![]() ->
->![]() ->
->![]() ->
->![]() ’的大回路,如果我们增添一个reconstruction loss,要求
’的大回路,如果我们增添一个reconstruction loss,要求![]() ’和
’和![]() 尽可能地相似,这样就会逼迫着
尽可能地相似,这样就会逼迫着![]() ->
->![]() 和
和![]() ->
->![]() 这两段路尽可能的不丢失原图的特征信息,最终就能解决图片不相似的问题。这个方法就是利用了Cycle consistency的ComboGAN。
这两段路尽可能的不丢失原图的特征信息,最终就能解决图片不相似的问题。这个方法就是利用了Cycle consistency的ComboGAN。
3.4 XGAN
不同于ComboGAN利用的是Cycle consistency,XGAN利用的是Semantic consistency(语义保持),也就是说不同于ComboGAN希望图像到图像能保持一致,XGAN希望的是特征到特征能保持一致。这样在计算相似性的时候不再是用pixel-wise的计算,而是latent相似性的计算。
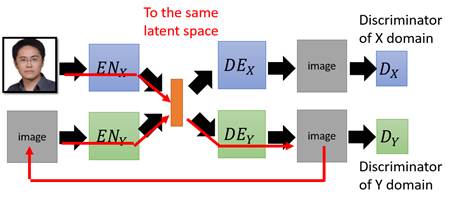
如上图所示,在![]() ->
->![]() 之后会得到一个
之后会得到一个![]() ,然后继续走半个循环得到
,然后继续走半个循环得到![]() ,即
,即![]() ->
->![]() ->
->![]() ->
->![]() ->
->![]() ,XGAN便是希望
,XGAN便是希望![]() 与
与![]() 能够越接近越好。
能够越接近越好。
转载自原文链接, 如需删除请联系管理员。
原文链接:【GANs学习笔记】(二十)CoGAN、ComboGAN、XGAN,转载请注明来源!