转自吾爱IC社区在知乎的专栏https://zhuanlan.zhihu.com/p/62537550
按照惯例今天这篇文章应该是昨天发出的,但是因为小编最近周末忙着往外地跑谈项目参加会议啥的,所以请大家谅解(短期内还是保持周更新)。今天这篇关于数字IC后端设计实现hold violation修复的分享也是昨晚在路上现写的,希望能够对大家有所帮助。
知识星球官方已于04.11号早晨完成技术升级,小编的星球也可以正常使用了。考虑到个别星友可能还不知道,小编在此统一发个通知。目前星球进入快速发展期,人数已经有170+,欢迎各位加入交流讨论(人数超过200人后,门票将调整为228元)。
Hold 检查
Hold 检查用一句话来概括就是它是用来验证时钟边沿到达之后,数据仍然有效的时间量。Hold 检查原理见下图所示。

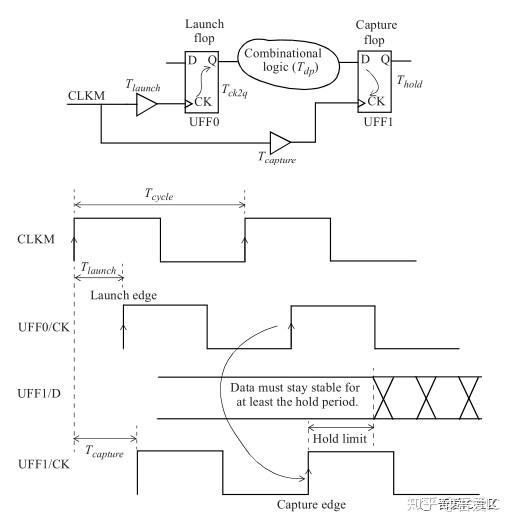
Hold检查公式:
Tlaunch +T ck2q + Tdp > Tcapture + Thold
其中Tlaunch和Tcapture的差值即为这两个寄存器的clock skew。在时钟树综合之前,这两个值均为0,CTS之后由于clock skew的存在,这两个值有一定的差值。在组合逻辑一定的情况下,为了能够使得hold violation最小,一方面我们希望将clock tree尽量作平,使得clock skew最小。另外一方面,对于图中这样的path,如果能够将Tcapture做的比Tlaunch小,Hold violation也会更少甚至没有。
常见修hold的方法
- 增大Tdp
从hold检查公式可以得知,增加Tdp可以使得公式左边更大,hold violation会更小。主要有三种方法来实现。第一种是插buffer,第二种是插delay cell,第三种是将data path上LVT的cell换成RVT或者HVT的cell。
- 增大Tlaunch
增大Tlaunch就是将launch FF的clock tree做长,主要可以通过设置floatin pin来让工具自己将clock tree做长特定数值。也可以通过人工Clock ECO的方式进行clock tree latency的调整。当然将本级的Tlaunch做长,可能会导致本级setup和前一级hold变得更差。因此再做时钟树clock tree latency调整时需要综合考虑前后级的timing margin。
- 减小Tcapture
同理,将capture的clock tree做短可以使得公式右边的值更小,从而hold violation更小。但是仍然需要考虑前后级的timing margin。
- 插lockup latch
听说Latch可以高效修hold违例(Timing borrowing及其应用)
如下图所示,DOMAIN1和DOMAIN2分别为两个clock domain,在func mode下两个domain不存在相互交互的path。因此,在做时钟树综合(CTS)时,会各自独立长clock tree,即他们之间的clock latency可能存在较大的差异。在func模式下不会有任何问题。但是,在做DFT的时候,我们将DOMAIN1和DOMAIN2的寄存器串在一条链上了。在scan shift时是有问题的。他们之间是需要做hold check(比如DOMAIN2的clock latency比较长)。
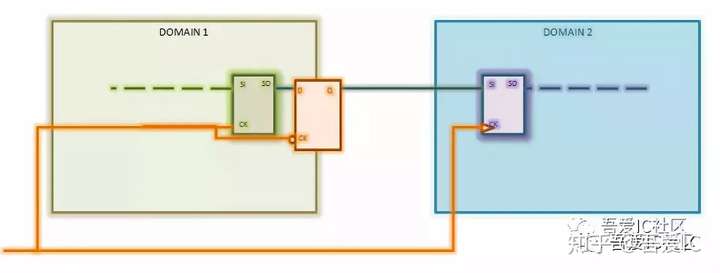
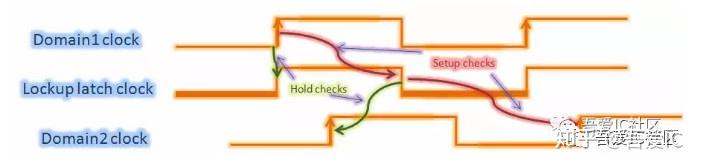
遇到这种情况,我们可以加负沿的latch来解决hold violation。加lockup latch后的波形图如下,从图中可以知道Domain1中的DFF到Lockup latch的hold明显得到了改善。同样Lockup latch到Domain2中的DFF的hold也没有问题。
- 局部Useful skew
很多时候在做hold time fixing时发现某一个module下的寄存器hold violation偏大,需要插入比较多的hold buffer(可能每个endpoint点需要插两三颗buffer)。PR插入buffer 做eco route后发现存在局部区域的short,且数量较多。此时往往是由于该module下的clock skew偏大导致的,可以将hold violation的数量往前一级进行转移处理。
Hold fixing流程
- 根据后端写出的spef和netlist,跑全corner的pt session。
- 做leakage optimization
为了降低功耗,每个模块都需要做1-3轮的leakage优化。而且在修hold violation之前做leakage优化有助于大规模减少hold violation的数量。
- DMSA Flow
PrimeTime目前支持physical aware的hold fixing方法,大部分设计都建议采用这种修法。PT中主要用以下几个命令来修setup,hold和max transition。其中physical_mode可以设置为open_site或occupied_site,前者不允许插入的buffer存在overlap,后着则可以存在overlap。一般建议先使用open_site来进行大规模的hold violation fixing。两种模式间的利弊留给各位思考。
由于修hold时插入buffer可能会把setup 变差,因此在进行hold fixing前需要设置setup margin,使得工具在修hold violation时能够确保setup不出现较大问题。
fix_eco_timing -type setup -cell_type combinational -physical_mode occupied_site -to $setup_endpoints
fix_eco_timing -type hold -setup_margin 0.09 -buffer_list $buffer_list -method insert_buffer -physical_mode occupied_site -to $hold_endpoints
fix_eco_drc -type max_transition -physical_mode occupied_site $tran_vio -buffer_list
- 手修hold violation
一般利用DMSA修几轮hold后,hold基本上都能clean。但是有时候也会出现某些path的hold violation工具并没有fix。这种情况一般分两种情况,第一种是有timing maring,由于工具的bug导致漏修。第二种情况是没有setup margin。不管如何,这两种情况都需要人工介入,要么自己人工插buffer,要么就是创造timing margin后再让工具来fixing。
- 其他情况
如果PrimeTime中check hold时发现hold violation的量超级大,且数值较大,很有可能是clock tree相当不balance导致的。这种情况往下修hold并没有多大意义,需要重新做时钟树综合。
2019年数字IC后端校招笔试题目(附数字后端培训视频教程)
setup和hold 互卡情况。有时候修几轮hold之后会发现setup和hold冲突或者互卡的现象。这个问题很有星友之前也提问过,还算是蛮经常遇到的问题,特别容易出现在高速模块中。碰到这种问题主要分两种情况,一种可能是设计问题,另外一个种是clock tree有问题。
小编知识星球简介(如果你渴望进步,期望高薪,喜欢交流,欢迎加入):
在这里,目前已经规划并正着手做的事情:
- ICC/ICC2 lab的编写
- 基于ARM CPU的后端实现流程
- 利用ICC中CCD(Concurrent Clock Data)实现高性能模块的设计实现
- 基于ARM 四核CPU 数字后端Hierarchical Flow 实现教程
- 时钟树结构分析
- 低功耗设计实现
定期将项目中碰到的问题以案例的形式做技术分享
在这里,各位可以就公众号推文的内容或者实际项目中遇到的难题提问,小编会在24小时内给予解答(也可以发表你对数字后端设计实现中某个知识点的看法,项目中遇到的难点,困惑或者职业发展规划等)。
反正它是一个缩减版的论坛,增强了大家的互动性。更为重要的是,微信有知识星球的小程序入口。星球二维码如下,可以扫描或者长按识别二维码进入。目前已经有172位星球成员,感谢这172位童鞋的支持!欢迎各位渴望进步,期望高薪的铁杆粉丝加入!终极目标是打造实现本知识星球全员年薪百万的宏伟目标。(星友人数超过200人后星球的门票即将调整到228元/年,有需求的朋友趁早上车,目前价格是208元/年,折算每天需要六毛钱 )
转载自原文链接, 如需删除请联系管理员。
原文链接:数字IC设计实现之hold violation修复大全,转载请注明来源!