学爬虫的初衷便是为了爬机票信息,因为从小到大没坐过飞机,所以有着深深的怨念。掌握了一定的爬虫技巧后,尝试过爬去哪儿网和携程网的机票,均以失败告终,所幸在最后的一根稻草艺龙网上取得了想要的结果。
用Scrapy框架来完成这次任务。
首先,创建一个新的project:
scrapy startproject Airplane可爬的信息有很多,如果你愿意,可以得到是否有餐食的信息,在items.py里列了出来。
import scrapy
class AirplaneItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
corpn = scrapy.Field() #航空公司
fltno = scrapy.Field() #航空公司编号
plane = scrapy.Field() #飞机型号
pk = scrapy.Field() #飞机大小
dportn = scrapy.Field() #出发机场
aportn = scrapy.Field() #到达机场
dtime = scrapy.Field() #出发时间
atime = scrapy.Field() #到达时间
meat = scrapy.Field() #是否有餐食
on = scrapy.Field() #历史准点率
minp = scrapy.Field() #该航班最低票价
tax = scrapy.Field() #民航基金
remainnum = scrapy.Field()#剩余票数将得到的信息保存为json格式的文件,便于使用,且观赏性亦良好。这需要修改pipelines.py的代码,这里对编码进行了处理,使得打开json格式后看到的是中文,而不是unicode的编码。
# -*- coding: utf-8 -*-
import codecs
import json
class AirplanePipeline(object):
def __init__(self):
self.file = codecs.open('mywillingtickets.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\n'
self.file.write(line.decode("unicode_escape"))接下来修改settings.py文件:
BOT_NAME = 'Airplane'
SPIDER_MODULES = ['Airplane.spiders']
NEWSPIDER_MODULE = 'Airplane.spiders'
ITEM_PIPELINES = {'Airplane.pipelines.AirplanePipeline': 1}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'Airplane (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36'在spiders文件夹下创建dict.py,在搜索北京到上海的机票时,出现的是这样的一个网址:
http://flight.elong.com/bjs-sha/day1.html其中的bjs和sha分别是北京和上海的缩写,在数据交换时使用的代号,这里需要一个这样的dict.py,做出这样的一个一一对应的字典,达到输入汉字能生成相应网址的功能。这里,做测试之用,只写了几个。
# -*- coding:utf-8 -*-
abbr = {}
abbr[u'郑州'] = 'cgo'
abbr[u'大连'] = 'dlc'
abbr[u'北京'] = 'bjs'
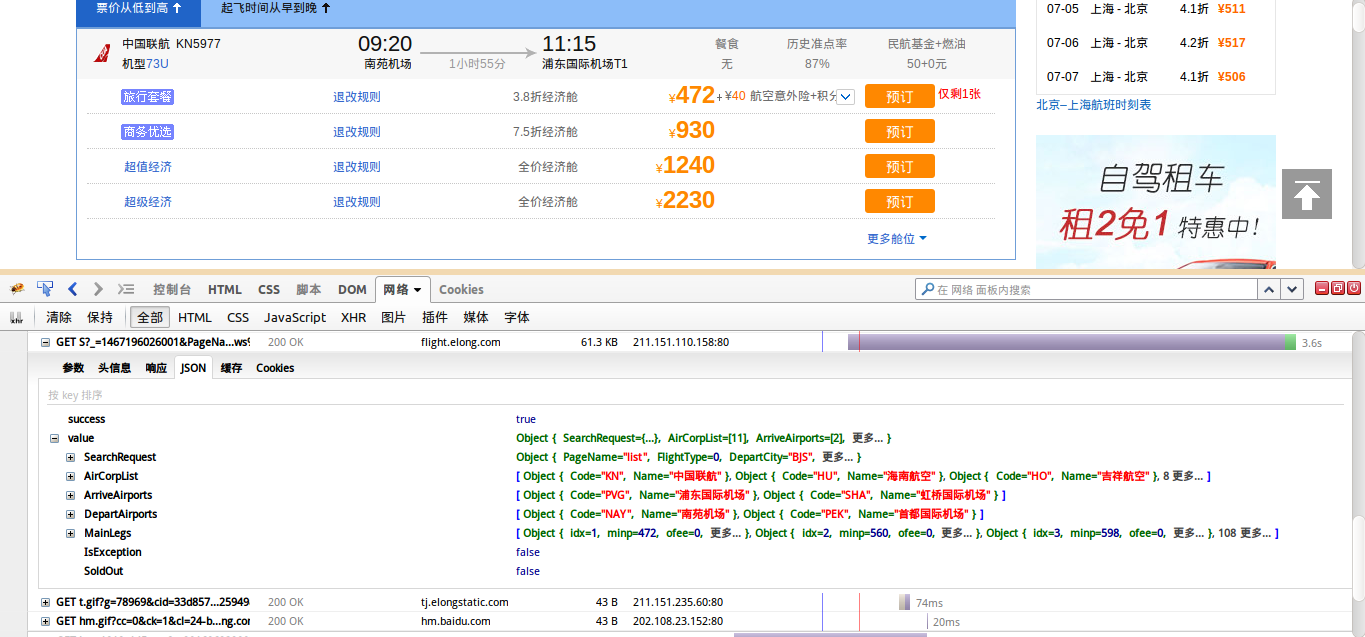
abbr[u'上海'] = 'sha' 最后便是写最关键的爬虫文件ticket.py了。思路是这样的,通过使用firebug对艺龙网进行搜索机票时的抓包分析,得到了其加载信息时的数据来源json文件url,通过修改url中的起点终点以及日期,可以得到所需要的信息的json文件。

之后进行json文件解析操作,便可以随意获取想要的信息。代码如下:
# -*- coding:utf-8 -*-
__author__ = 'fybhp'
import scrapy
from Airplane.items import AirplaneItem
import json,random
from dict import abbr
import datetime
class TicketSpider(scrapy.Spider):
name = "ticket"
allowed_domains = ["flight.elong.com"]
start_urls = []
def __init__(self):
DepartCity = raw_input('DepartCity:').decode('utf-8')
ArriveCity = raw_input('ArriveCity:').decode('utf-8')
your_price = raw_input('Please give your willing price:')
self.your_price = your_price
for i in range(31):
DepartDate = str(datetime.date.today() +datetime.timedelta(days = i))
self.start_urls.append('http://flight.elong.com/isajax/OneWay/S?_='+str(random.randint(1000000000000,
1999999999999))+'&PageName=list&FlightType=OneWay&DepartCity='+\
abbr[DepartCity]+'&ArriveCity='+\
abbr[ArriveCity]+'&DepartDate='+DepartDate)
def parse(self,response):
sel = json.loads(response.body,encoding='utf-8')
item = AirplaneItem()
for yige in sel['value']['MainLegs']:
item['minp'] = yige['minp']
if item['minp'] <= int(self.your_price):
item['corpn'] = yige['segs'][0]['corpn']
item['dtime'] = yige['segs'][0]['dtime']
item['atime'] = yige['segs'][0]['atime']
item['remainnum'] = yige['cabs'][0]['tc']
#item['fltno'] = yige['segs'][0]['fltno']
#item['plane'] = yige['segs'][0]['plane']
#item['pk'] = yige['segs'][0]['pk']
#item['dportn'] = yige['segs'][0]['dportn']
#item['aportn'] = yige['segs'][0]['aportn']
#item['meat'] = yige['segs'][0]['meat']
#item['on'] = str(yige['segs'][0]['on']) + '%'
#item['tax'] = yige['tax']
yield item
else:
continue 由于并不是需要所有item中列出的信息,这里将它们注释掉了。在运行爬虫的时候会提示输入起始站,终点站,以及你所接受的最高票价,这样,高于所给票价的航班均会被过滤掉,不会出现在json文件中。文件中时间设定的是31天内,在init 中,该值可以任意更改。运行时交互情况如下图:

爬取结束后,得到了mywillingtickets.json文件,如图:

看起来还不错,是吧。总之,希望这个小爬虫能给您带来帮助或者惊喜。
转载自原文链接, 如需删除请联系管理员。
原文链接:使用Scrapy框架爬取艺龙网机票信息,转载请注明来源!