1. 摘要&介绍
训练一个end-to-end, pixels-to-pixels的全卷积网络,使得任意大小的输入会产生对应大小的输出。
Improving:whole-image classification, bounding box object detection, part and key-point prediction, local correspondence(局部匹配).
训练end-to-end FCN: (1) pixelwise prediction; (2)supervised pre-training.
New FCN: does not use of pre- and post-processing complications;
重新分类全卷积网络并且微调已有模型进行dense prediction;
定义一个新的结构”skip”联系(深度,粗糙,语义信息)和(浅显,精细,表层信息)。
semantic segmentation所面临的固有矛盾:全局信息解决什么;局部信息解决哪里。
2. FCN
数据每一层都是一个三维阵列(h*w*d),h和w是空间维度,d为特征维或者信道维。
感受野:输出feature map某个节点的响应对应的输入图像的区域就是感受野

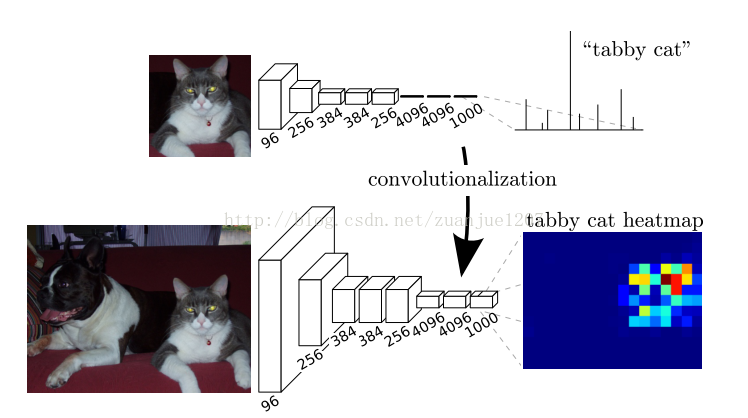
把已有CNN模型的全连接层转化卷积层,三层卷积层中卷积核的大小为(宽,高,通道数)(1,1,4096),(1,1,4096),(1,1,1000)模板大小即输入特征图像的大小。
经过多次pooling以后,像素分辨率越来越低,采用upsample(反卷积deconvolution),以得到与原图像相同大小的输出。
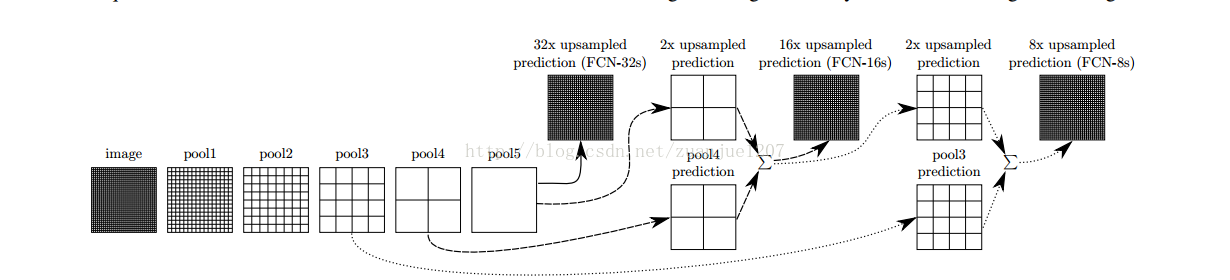
Dense prediction methods:
(1). shift-and-stitch:从coarse层不进行插值直接预测像素值,产生预测的像素结果就和感受野中间的像素相关。
(2)Patchwise training:修正类别失衡,能够缓和dense patch间的空间相关性.
(3)(本文采用的方法)skip:将coarse、semantic和local、appearance结合并refine prediction。将传统的深度网络层(CNN)做以下的改进:去掉最后的pooling 层,转变为对所有的全联接做卷积,也就是利用双线性插值的方法做下采样,并且利用BP算法根据Ground truth的先验标签进行Fine-tuning。这种方式对于密度预测学习有着快速有效的优势。
转载自原文链接, 如需删除请联系管理员。
原文链接:FCN(Fully convolutional networks)阅读,转载请注明来源!