hive框架结构及特点
现如今,大数据是互联网的趋势,hadoop作为大数据时代中较为核心的技术使用的人也越来越多。但是Hadoop的MapReduce操作的专业性较强,于是为了降低MapReduce的操作难度,更好的管理海量数据,就在此基础上开发了hive。
Hive是一个数据仓库应用程序,对存储在HDFS中的数据进行分析和管理;将结构化的数据文件映射成一张数据库表,并提供完整的SQL查询功能,通过SQL语句转化为MapReduce任务进行运行。
HIVE 框架结构
Hive的主要“模块”以及hive与Hadoop的交互。

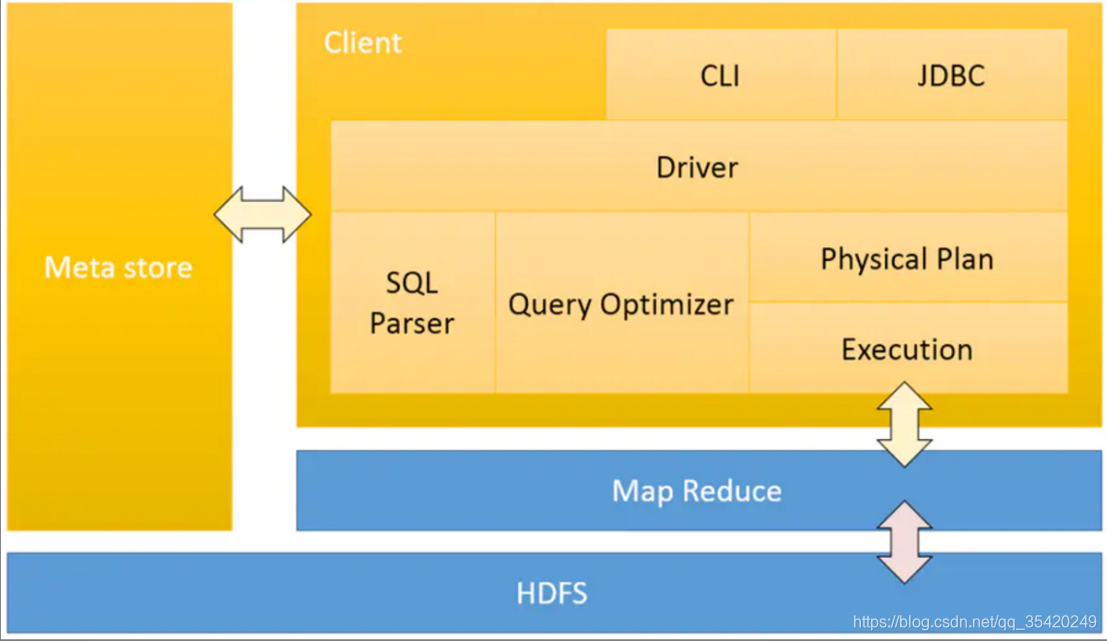
- Hive连接方式:CLI(命令行页面)、hive网页界面、可通过JDBC\ODBC\Thrift服务器进行编程访问。
- Driver(驱动模块):对输入的命令和查询进行解析编译,对需求的计算进行优化,然后按照步骤执行(通常启动多个MapReduce(job)任务)。通过一个表示“job执行计划”的XML文件驱动执行内置的、原生的mapper和reducer模块。包括解析器、编译器、优化器、执行器;
1、解析器:将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工 具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误(比如select中被判定为聚合的字段在group by中是 否有出现);
2、编译器:将AST编译生成逻辑执行计划;优化器:对逻辑执行计划进行优化;
3、执行器:把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/TEZ/Spark; - Metastore(元数据存储):包括表名、表所属的数据库、表的拥有者、列、分区字段、表的类型、表的数据所在目录等。
元数据需要不断的修改、更新,所以hive元数据不适合存储在HDFS中,一般存在关系型数据库中。有三种模式可以连接到数据库:单用户模式;多用户模式;远程服务模式
单用户模式使用自带的Derby数据库中,可以启动多个hive,但是每个hive只能连接一个客户端;
多用户模式推荐使用mysql进行存储,mysql和hive在同一台机器上,hive服务和metastore服务运行在同一个进程中,适合公司内部使用,需要用户对mysql有访问权限,客户端需要知道mysql的用户名和密码;
远程服务模式指的是从通过其他机器的MySQL等数据库连接,hive服务和metastore在不同进程内,客户端通过beeline连接,无需知道数据库的密码,一般线上采用远程服务模式。 - MapReduce:是一种计算模型,将大型数据处理任务(job)分解为许多单个、可以在服务器集群中并行执行的任务(task),任务的计算结果可以合并计算形成最终结果。
分为map过程和reduce过程。
Map过程:将输入的key-value转换成0至多个key-value。key的输入输出值完全不同,value的输入输出值可能完全不同。
Reduce过程:将同个key的所有key-value进行处理,转换成一个key-value。输入和输出的key-value可能不同。
简单来说,hive将SQL中的执行计划写成MR模板,封装在hive中。当客户端发送请求时---->先到metastore查询表的相关信息---->通过解析器将SQL转换成抽象语法树---->通过编译器形成逻辑执行计划---->优化器对逻辑执行计划进行查询优化---->执行器将逻辑执行计划转换为物理计划---->提交给MR执行MR中的模板---->得出结果返回给客户端。
Hive的特点
Hive适合进行相关的静态数据分析,用于那些不需要快速响应给出结果且数据本身不会频繁变化。可维护海量数据,一般用于海量结构化数据的离线分析。
- 优点:
1、简单易上手:提供了类SQL查询语言HQL
2、减少开发人员的学习成本;
3、可扩展:hive是建立在Hadoop之上的,因此hive的可扩展性和Hadoop的可扩展性是一致的。
4、延展性:hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
5、容错:良好的容错性,节点出现问题SQL仍然可以完成执行
6、提供统一的元数据管理 - 缺点:
1、表达能力有限:迭代式算法无法表达、数据挖掘方面不擅长;
2、效率较低:hive自动生成的MapReduce通常情况下不够智能化、调优较困难;
3、查询延迟性比较严重;不支持update。
总结
Hive 是一个海量数据的分析引擎。相当于Hadoop的一个客户端,不算是传统意义上的数据库,hive自己不负责运算,计算由MapReduce/Tez/Spark进行;不负责存储,数据是存储在HDFS上的;也不存储元数据信息,元数据信息存储在关系型数据库中。提供类SQL的查询语句,在功能方面与数据库基本相同,部分功能不支持。
它不适合联机(online)事务处理,也不提供实时查询功能。Hive更适用于在大量静态数据上的批处理。Hive的特点是可扩展、有较高的容错率、可处理海量数据、可定制。
除了底层HDFS,上面跑MapReduce/Tez/Spark,再上面跑hive、pig之外。也可以直接在HDFS上跑impala、drill、presto。这些架构基本上都能解决中低速的数据处理的要求
拓展
Hive2.0之后的版本中,底层的运算引擎已经不是MR,了,而是spark变成了sparkSQL,由于spark基于内存的特点,所以查询速度提升了数倍,但是spark本身是不提供存储的,所以还是需要hive作为数据仓库进行配合。当然也有其他模式如hive on tez和hive on spark。但是由于tez部署比spark繁琐,确实用的人不是很多,本质上还是基于mr,算是对mr做了dag方向的优化,提升了mr的速度,但由于其仍然采用mr的执行方式,所以说速度不会超过spark,加上部署繁琐,基本上都是用spark。
其他实时响应的项目使用的工具:spark(基于scala API的分布式数据集的分布式计算框架,shark:将hive指向spark)、storm(实时事件流处理系统)、kafka(分布式发布-订阅消息传递系统)。
转载自原文链接, 如需删除请联系管理员。
原文链接:hive框架结构及特点,转载请注明来源!