正式开始抓取一下网易新闻的内容
- 抓取网易的国内、国际、军事、政务网站信息
- 由于新闻信息有一定的时效性,因此在一定的程度上内容并不会改变很多,因此需要定时的抓取
- 且防止程序退出后,重新抓取同样的网页信息,因此我们在抓取的过程中将我们抓取的网站信息存储到pkl文件中
- 并且我们要尽可能的对网页新闻内容进行关键词提取
下面我们一步步来完善我们的程序
重新修改一下spyder文件
#!/usr/bin/env python
# coding=utf-8
from scrapy.selector import Selector
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from News_Scrapy.items import NewsScrapyItem
from scrapy.conf import settings
import os,pickle,signal
import sys
## MySelf define the Global Variable
SAVED_URL = set()
if os.path.isfile(settings["SAVED_URL_PATH"]):
with open(settings["SAVED_URL_PATH"],"rb") as handle:
SAVED_URL = pickle.load(handle)
def save_url_pkl(sig,frame):
with open(settings["SAVED_URL_PATH"],"wb") as handle:
pickle.dump(SAVED_URL,handle)
sys.exit(0)
signal.signal(signal.SIGINT,save_url_pkl)
class NetEaseSpider(CrawlSpider):
name = "News_Scrapy"
allowed_domains = ["news.163.com"]
start_urls = ["http://news.163.com/domestic/","http://news.163.com/world/","http://news.163.com/shehui/","http://war.163.com/","http://gov.163.com/"]
rules = [
Rule(SgmlLinkExtractor(allow=(r'http://news.163.com/[0-9]{2}/[0-9]{3,4}/[0-9]{1,2}/[a-zA-Z0-9]+.html')),callback="parse_item"),
Rule(SgmlLinkExtractor(allow=(r'http://war.163.com/[0-9]{2}/[0-9]{3,4}/[0-9]{1,2}/[a-zA-Z0-9]+.html')),callback="parse_item"),
Rule(SgmlLinkExtractor(allow=(r'http://gov.163.com/[0-9]{2}/[0-9]{3,4}/[0-9]{1,2}/[a-zA-Z0-9]+.html')),callback="parse_item"),
]
def parse_item(self,response):
if response.url not in SAVED_URL:
SAVED_URL.add(response.url)
sel_resp = Selector(response)
news_item = NewsScrapyItem()
news_item["news_title"] = sel_resp.xpath('//*[@id="h1title"]/text()').extract()
news_item["news_date"] = sel_resp.xpath('//*[@id="epContentLeft"]/div[1]/div[1]/text()').re(r'[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}')
news_item["news_source"] = sel_resp.xpath('//*[@id="ne_article_source"]/text()').extract()
news_item["news_content"] = sel_resp.xpath('//*[@id="endText"]').extract()
return news_item
进行新闻内容中关键字提取出来
- 我们使用中文分析的一个开源库结巴分词
-
如果直接使用pip或者easy_install不能直接安装,我们手动安装
- 先找到我们本地的python的外部库的位置
fighter@pc:~$ ipython #使用ipython
In [1]: import site; site.getsitepackages()
Out[1]: ['/usr/local/lib/python2.7/dist-packages', '/usr/lib/python2.7/dist-packages']- 我们进入local路径下面的dist-package目录
fighter@pc:/usr/local/lib/python2.7/dist-packages$ sudo git clone https://github.com/fxsjy/jieba.git- 或者你可以在任意的路径下下载jieba进行安装
fighter@pc:~/Downloads$ git clone https://github.com/fxsjy/jieba.git
Cloning into 'jieba'...
remote: Counting objects: 2287, done.
remote: Total 2287 (delta 0), reused 0 (delta 0), pack-reused 2287
Receiving objects: 100% (2287/2287), 39.72 MiB | 3.12 MiB/s, done.
Resolving deltas: 100% (1293/1293), done.
Checking connectivity... done.
fighter@pc:~/Downloads$ ls
jieba
fighter@pc:~/Downloads$ cd jieba/
fighter@pc:~/Downloads/jieba$ ls
Changelog extra_dict jieba LICENSE MANIFEST.in README.md setup.py test
fighter@pc:~/Downloads/jieba$ sudo python setup.py install
......
fighter@pc:~/Downloads/jieba$ ls /usr/local/lib/python2.7/dist-packages/
jieba jieba-0.38.egg-info shadowsocks shadowsocks-2.8.2.egg-info- 将我们提取的content内容过滤一下


碰到这种蛋疼的问题,真的是只有使用正则表达式了!但是,还有有个神器是BeautifulSoup,这个可确实帮了我的大忙,不然真的会写晕的!
具体的BeautifulSoup的使用可以参考我的一个小工程,因此整个parse部分直接使用BeautifulSoup来搞定。具体代码如下所示;
def parse_item(self,response):
if response.url not in SAVED_URL:
SAVED_URL.add(response.url)
soup = BeautifulSoup(response.body)
news_item = NewsScrapyItem()
news_item["news_title"] = soup.find("title").string
new_date_list = soup.findAll("div",{"class":["ep-time-soure cDGray","pub_time"]})
news_date_re = re.findall(r"\d{2}/\d{4}/\d{2}",response.url)[0].split("/")
news_item["news_date"] = "20" + news_date_re[0] + "-" + news_date_re[1][:2] + "-" + news_date_re[1][-2:] + " " + news_date_re[2]
if len(new_date_list) != 0:
news_item["news_date"] = new_date_list[0].string[:19]
tmp_news_source = soup.find("a",{"id":"ne_article_source"})
if tmp_news_source != None:
news_item["news_source"] = tmp_news_source.string
else:
news_item["news_source"] = "NetEase"
data = soup.findAll("div",{"id":"endText"})[0]
data_list = data.findAll("p",{"class":""})
contents = ""
for item in data_list:
if type(item.string) != types.NoneType:
test = item.string.encode("utf-8")
contents = contents + test
news_item["news_content"] = contents
return news_item- 这回终于可以开始搞分词了
先去熟悉一下jieba分词这个库该如何使用,具体请见github上的demo程序,我这里仅仅显示出我需要的部分功能
#encoding=utf-8
from __future__ import unicode_literals
import sys
sys.path.append("../")
import jieba
import jieba.posseg
import jieba.analyse
print('='*40)
print('1. 分词')
print('-'*40)
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):
print('%s %s' % (x, w))
print('-'*40)
print(' TextRank')
print('-'*40)
for x, w in jieba.analyse.textrank(s, withWeight=True):
print('%s %s' % (x, w))
print我们只要将上述的代码中的内容部分替换成我们的新闻内容,稍作修改就可以使用了!
key_map = {}
for x,w in jieba.analyse.extract_tags(contents,withWeight=True):
key_map[x] = w
news_item["news_key"] = json.dumps(key_map)发现一些问题
- 不能连续抓取很多网页,每次大于只能自动抓取大约100多条记录
- 并且在同一个网页上的抓取的深度较浅
- 为了解决这些问题,进行以下修改,这里仅仅显示最重要的部分
class NetEaseSpider(CrawlSpider):
name = "News_Scrapy"
allowed_domains = ["news.163.com"]
start_urls = ["http://news.163.com","http://news.163.com/domestic/","http://news.163.com/world/","http://news.163.com/shehui/","http://war.163.com/","http://gov.163.com/"]
rules = [
Rule(SgmlLinkExtractor(allow=(r'http://[a-z]+.163.com/[a-z]*')),callback="parse_item"),
Rule(SgmlLinkExtractor(allow=(r'http://[a-z]+.163.com/[0-9]{2}/[0-9]{3,4}/[0-9]{1,2}/[a-zA-Z0-9]+.html')),callback="parse_item_yield"),
]
detail_re = re.compile(r'http://[a-z]+.163.com/[0-9]{2}/[0-9]{3,4}/[0-9]{1,2}/[a-zA-Z0-9]+.html')
head_re = re.compile(r'http://[a-z]+.163.com')
def parse_item(self,response):
if response.url not in SAVED_URL:
SAVED_URL.add(response.url)
soup = BeautifulSoup(response.body)
for item in soup.findAll("a"):
if item.has_attr("href"):
head_url_list = re.findall(self.head_re,item["href"])
detail_url_list = re.findall(self.detail_re,item["href"])
if type(head_url_list) != types.NoneType:
for tmp in head_url_list:
if tmp not in SAVED_URL:
yield Request(tmp,callback=self.parse_item_yield)
if type(detail_url_list) != types.NoneType:
for tmp in detail_url_list:
if tmp not in SAVED_URL:
yield Request(tmp,callback=self.parse_item_yield)
def parse_item_yield(self,response):
if response.url not in SAVED_URL:
SAVED_URL.add(response.url)
soup = BeautifulSoup(response.body)
news_item = NewsScrapyItem()
news_item["news_title"] = u"网易新闻"
if type(soup.find("title")) != types.NoneType:
news_item["news_title"] = soup.find("title").string
new_date_list = soup.findAll("div",{"class":["ep-time-soure cDGray","pub_time"]})
news_date_re = re.findall(r"\d{2}/\d{4}/\d{2}",response.url)[0].split("/")
news_item["news_date"] = "20" + news_date_re[0] + "-" + news_date_re[1][:2] + "-" + news_date_re[1][-2:] + " " + news_date_re[2]
if len(new_date_list) != 0:
news_item["news_date"] = new_date_list[0].string[:19]
tmp_news_source = soup.find("a",{"id":"ne_article_source"})
if tmp_news_source != None:
news_item["news_source"] = tmp_news_source.string
else:
news_item["news_source"] = "NetEase"
data = soup.findAll("div",{"id":"endText"})[0]
data_list = data.findAll("p",{"class":""})
contents = ""
for item in data_list:
if type(item.string) != types.NoneType:
test = item.string.encode("utf-8")
contents = contents + test
news_item["news_content"] = contents
key_map = {}
for x,w in jieba.analyse.extract_tags(contents,withWeight=True):
key_map[x] = w
news_item["news_key"] = json.dumps(key_map)
yield news_item
for item in soup.findAll("a"):
if item.has_attr("href"):
head_url_list = re.findall(self.head_re,item["href"])
detail_url_list = re.findall(self.detail_re,item["href"])
if type(head_url_list) != types.NoneType:
for tmp in head_url_list:
if tmp not in SAVED_URL:
yield Request(tmp,callback=self.parse_item_yield)
if type(detail_url_list) != types.NoneType:
for tmp in detail_url_list:
if tmp not in SAVED_URL:
yield Request(tmp,callback=self.parse_item_yield)经过这样的修改,每次大约可以抓取几个小时,并且一次可以抓取的有效信息大约在4000条记录左右
- 这样又有一个新的问题,要让程序自动的定时抓取,需要我们写一个脚本并且添加定时任务脚本
这样就可以让云服务器自己定时去抓取了!
下一部分
对于抓取的部分如何建立索引
- 这里我建立索引的方式比较简单,没有使用python提供的elasticSearch这个包
- 而是将所有的新闻的关键字存在map中,然后将每个新闻的标题和其对应的评分按照数组的形式插入到指定的关键字之后
- 对于插入的信息,按照评分降序排列
def load_News_DB():
contents = cursor.find({},{"news_title":1,"news_key":1,"_id":0})
index = 0
key_index_map = {}
for item in contents:
index = index + 1
if item.has_key("news_key"):
news_key_str = item["news_key"]
news_key = json.loads(news_key_str)
for word in news_key.keys():
if word.isdigit() == False:
if key_index_map.has_key(word):
key_index_map[word].append((item["news_title"],news_key[word]))
else:
key_index_map[word] = [(item["news_title"],news_key[word])]
if index % 10000 == 0:
with open("index_"+str(index) + ".json",'w') as handle:
for tmp in key_index_map.keys():
tmp_list = sorted(key_index_map[tmp],key = lambda x:x[1],reverse = False)
key_index_map[tmp] = []
for title in tmp_list:
key_index_map[tmp].append(title[0])
handle.write(json.dumps(key_index_map))
key_index_map = {}
with open("index_"+str(index) + ".json",'w') as handle:
for tmp in key_index_map.keys():
tmp_list = sorted(key_index_map[tmp],key = lambda x:x[1],reverse = False)
key_index_map[tmp] = []
for title in tmp_list:
key_index_map[tmp].append(title[0])
handle.write(json.dumps(key_index_map))但是由于数据量太大,则将数据按照索引次序进行排列,按照10000条记录分开存储,之后发现,按照json文本存储确实很费空间,处理也不方便,
便使用pkl形式,将map直接固话到本地。存储的信息
如何与前端配合显示索引结果
后台服务器Webpy
#-*- coding:utf-8 -*-
import web
import json,os
import pickle
urls = (
"/","index"
)
class index:
def GET(self):
web.header('Access-Control-Allow-Origin','*')
web.header('Content-Type','application/json')
befor_data = web.input()
data = None
if befor_data.has_key("CONTENTS"):
if befor_data["CONTENTS"] == "SEARCH":
key_info = befor_data["QUERY"]
if len(key_info) == 0:
return json.dumps({"name":"search","code":"1","status":"No Query Word"})
data = self.search_related(key_info)
return json.dumps(data)
def POST(self):
web.header('Access-Control-Allow-Origin','*')
web.header('Access-Control-Allow-Headers', 'content-type')
web.header('Content-Type','application/json')
print web.input()
data = self.getdata()
return data
def OPTIONS(self):
web.header('Access-Control-Allow-Origin','*')
web.header('Access-Control-Allow-Headers', 'content-type')
web.header('Content-Type','application/json')
return
def search_related(self,key_word):
result = {'name':'search',"data":[]}
result["data"] = self.read_news_index(key_word)
return result
def read_news_index(self,key_word):
base_dir = "../../News_Index/"
title_list = []
for filename in os.listdir(base_dir):
if filename.endswith("pkl"):
with open(base_dir + filename,"rb") as handle:
index_map = pickle.load(handle)
if index_map.has_key(key_word):
title_list.extend(index_map[key_word])
if len(title_list) >= 10:
break
return title_list
if __name__ == "__main__":
web.config.debug = False
app = web.application(urls,globals())
app.run()前端html和Ajax
前端的具体信息通信请看JS脚本
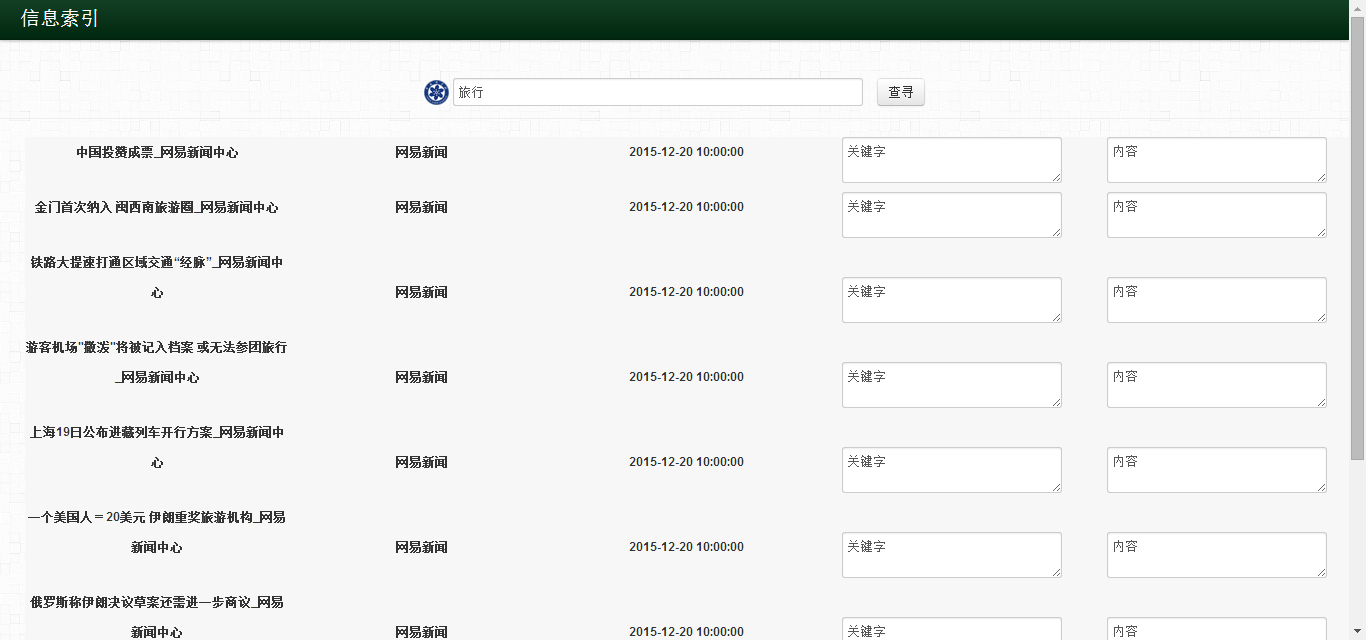
具体的界面结果如下
转载自原文链接, 如需删除请联系管理员。
原文链接:新闻信息检索(二),转载请注明来源!