Abstract
- YOLO:You Only Look Once
- YOLO通过回归的方式来解决目标检测问题,可以在简单neural network上直接从图像预测bounding box coordinate和class probability;
- base model性能在Titan X 上45 frames/s,fast model 155 frames/s,和其他检测系统相比有更多的localization错误,但是在背景上的false positive更少;
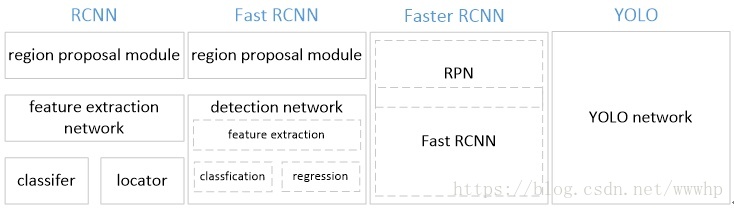
- 各框架模块对比:

Introduction

- YOLO使用简单的网络结构同时预测bounding box和class probability,通过直接处理整张图像优化检测性能,由于不需要复杂的pipeline整个检测流程速度很快,MAP也比其他检测系统高两倍;
- YOLO和sliding windows和region proposal-based方法区别在于训练和测试阶段始终能看到整张图像,能更好地理解上下文信息,background error比Fast R-CNN少一半;
- YOLO在accuracy上相比于最先进的方法有所落后,虽然可以快速识别图像中的物体,但是很难精确定位一些目标尤其是小目标;
Unified Detection
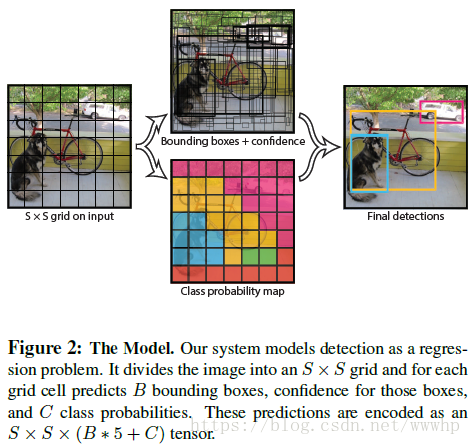
- 将输入图像分为S × S 个grid,每个grid cell预测B个bounding box坐标和confidence score,每个bounding box由5个prediction组成:x,y,w,h,confidence score,每一个grid同时预测C个class probability(是针对grid预测不是针对每一个bounding box);
- confidence score是针对每一个bounding box计算的:,如果不存在object写score为0;
- test阶段计算每一个box的class-specific confidence score:
- 坐标信息参数化:x,y根据grid offset到0-1,w,h根据image w和h归一化到0-1
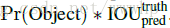
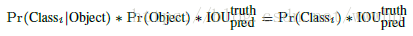

- network包含24个conv和两个fc使用1×1卷积降低特征维度,输入为448×448×3的图像,输出为7×7×30的tensor(7对应的是grid维度,30由两个bounding box的x,y,w,h,confidence的prediction以及20 class probability组成);
- Training之前用前20个conv接上average pooling和fc在ImageNet数据集上达到88%top-5的accuracy,为了满足更加细粒的视觉信息,提高input的分辨率448×448
Loss Funtion

- 为了让损失函数各方面平衡,更加重视坐标预测赋予更大的loss weight 5,没有object的box的confidence loss weight 0.5;
- 为了解决不同大小box对应的预测偏移loss相同所带来的问题,将平方差的元素求平方根;
- 设定当前预测box和ground truth box中IOU最大的为box predictor;
grid cell中object的界定
- 将图像448×448不断downsample,将输入图像划分成7×7个grid cell相当于一个grid cell对应64×64个像素点;
- 有每个object的标注信息,也就知道每个object的中心点坐标在输入图像的哪个位置,那么不就相当于知道了每个object的中心点坐标属于哪个grid cell了吗,而只要object的中心点坐标落在哪个grid cell中,这个object就由哪个grid cell负责预测,也就是该grid cell包含这个object。另外由于一个grid cell会预测两个bounding box,实际上只有一个bounding box是用来预测属于该grid cell的object的,因为这两个bounding box到底哪个来预测呢?答案是:和该object的ground truth的IOU值最大的bounding box;
Related Source
- arxiv: http://arxiv.org/abs/1506.02640
- code: http://pjreddie.com/darknet/yolo/
- github: https://github.com/pjreddie/darknet
- blog: https://pjreddie.com/publications/yolo/
- slides: https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.p
- reddit: https://www.reddit.com/r/MachineLearning/comments/3a3m0o/realtime_object_detection_with_yolo/
- github: https://github.com/gliese581gg/YOLO_tensorflow
- github: https://github.com/xingwangsfu/caffe-yolo
- github: https://github.com/frankzhangrui/Darknet-Yolo
- github: https://github.com/BriSkyHekun/py-darknet-yolo
- github: https://github.com/tommy-qichang/yolo.torch
- github: https://github.com/frischzenger/yolo-windows
- github: https://github.com/AlexeyAB/yolo-windows
- github: https://github.com/nilboy/tensorflow-yolo
转载自原文链接, 如需删除请联系管理员。
原文链接:YOLO v1论文理解,转载请注明来源!