MPEG是运动图像专家组(Moving Picture Experts Group)的简称,其实质上的名称为国际标准化组织(ISO)和国际电工委员会(IEC)联合技术委员会(JTC)1的第29 分委员会的第11工作组,即ISO/IEC JTC1/SC29/WG11,成立于1988年。其任务是制定世界通用的视音频编码标准。因为,广播电视数字化所产生的海量数据对存储容量、传输带宽、 处理能力及频谱资源利用率提出了不切合实际的要求,使数字化难以实现。为此,该专家组基于帧内图像相邻像素间及相邻行间的空间相关性和相邻帧间运动图像的 时间相关性,采用压缩编码技术,将那些对人眼视觉图像和人耳听觉声音不太重要的东西及冗余成分抛弃,从而缩减了存储、传输和处理的数据量,提高了频谱资源 利用率,制定了如表1所示的一系列MPEG标准,使数字化正在变为现实。其中,MPEG-2是一组用于视音频压缩编码及其数据流格式的国际标准。它定义了 编解码技术及数据流的传输协议;制定了MPEG-2解码器之间的共同标准(MPEG-2编码器之间尚无共同标准)。本文以MPEG-2的系统、MPEG- 2的编码、及MPEG-2的应用为题,讨论MPEG-2压缩编码技术。

一、MPEG-2的系统
1.系统的定义
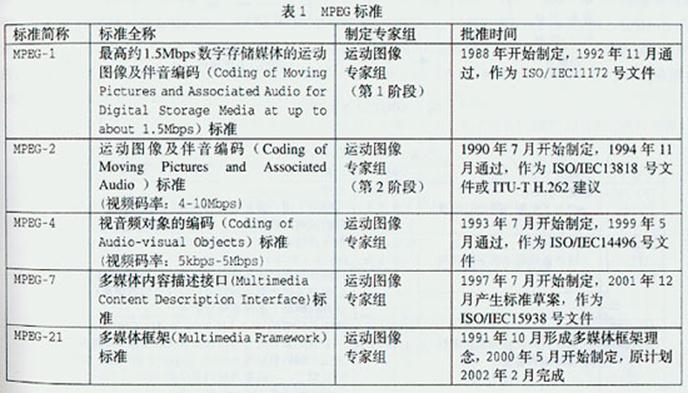
MPEG-2系统是将视频、音频及其它数据基本流组合成一个或多个适宜于存储或传输的数据流的规范,如图1所示。由图1可见,符合ITU-R. 601标准的、帧次序为I1B2B3P4B5B6P7B8B9I10数字视频数据和符合AES/EBU标准的数字音频数据分别通过图像编码和声音编码之 后,生成次序为I1P4B2B3 P7B5B6I10 B8B9视频基本流(ES)和音频ES。在视频ES中还要加入一个时间基准,即加入从视频信号中取出的27MHz时钟。然后,再分别通过各自的数据包形成 器,将相应的ES打包成打包基本流(PES)包,并由PES包构成PES。最后,节目复用器和传输复用器分别将视频PES和音频PES组合成相应的节目流 (PS)包和传输流(TS)包,并由PS包构成PS和由TS包构成TS。显然,不允许直接传输PES,只允许传输PS和TS;PES只是PS转换为TS或 TS转换为PS的中间步骤或桥梁,是MPEG数据流互换的逻辑结构,本身不能参与交换和互操作。由系统的定义,可知MPEG-2系统的任务。
2.系统的任务
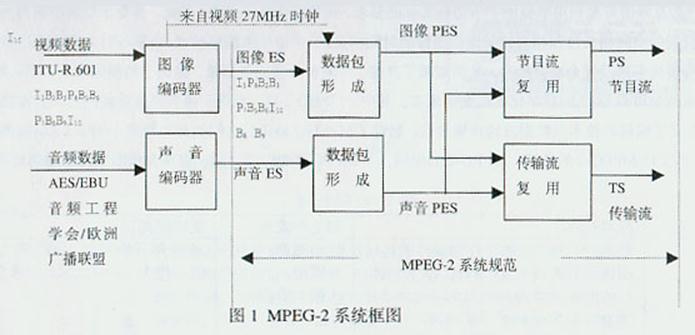
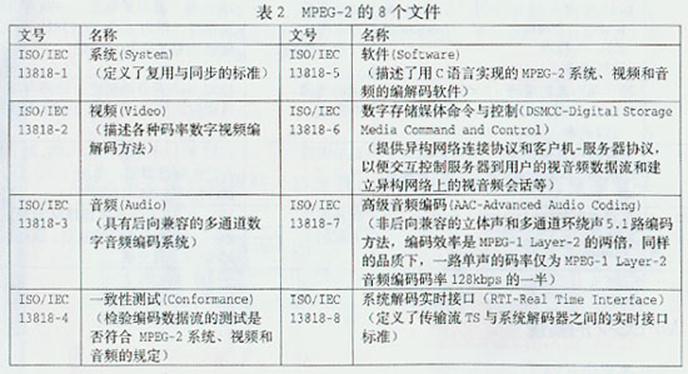
MPEG-2的标准由表2所示的8个文件组成,MPEG-2系统是其关键部分。MPEG以开放系统互联(OSI-Open System Interconnection)为目标,争取全球标准化。在详细规定视音频编码算法的基础上,为传输和交换编码数据流(比特流,码流,流)创造统一条 件。以利于接收端重建为指导,按照既定的参数给数据流以一定程度的"包装"。因此,MPEG-2系统应完成的任务有:
● 规定以包方式传输数据的协议;
● 为收发两端数据流同步创造条件;
● 确定将多个数据流合并和分离(即复用和解复用)的原则;
● 提供一种进行加密数据传输的可能性。
由系统的任务,可知完成任务,系统应具备的基础。
3.系统的要点
根据数字通信信息量可以逐段传输的机理,将已编码数据流在时间上以一定重复周期结构分割成不能再细分的最小信息单元,这个最小信息单元就定义为数据包,几 个小数据包(Data Packet)又可以打包成大数据包(Data Pack)。用数据包传输的优点是:网络中信息可占用不同的连接线路和简单暂存;通过数据包交织将多个数据流组合(复用)成一个新的数据流;便于解码器按 照相应顺序对数据包进行灵活地整理。从而,数据包为数据流同步和复用奠定了基础。因此,MPEG-2系统规范不仅采用了PS、TS和PES三种数据包,而 且也涉及PS和TS两种可以互相转换的数据流。显然,以数据包形式存储和传送数据流是MPEG-2系统的要点。为此,MPEG-2系统规范定义了三种数据 包及两种数据流:
1) 打包基本流(PES)
将MPEG-2压缩编码的视频基本流(ES-Elementary Stream)数据分组为包长度可变的数据包,称为打包基本流(PES- Packetized Elementary Stream)。广而言之,PES为打包了的专用视频、音频、数据、同步、识别信息数据通道。所谓ES,是指只包含1个信源编码器的数据流。即ES是编码 的视频数据流,或编码的音频数据流,或其它编码数据流的统称。每个ES都由若干个存取单元(AU-Access Unit)组成,每个视频AU或音频AU都是由头部和编码数据两部分组成的。将帧顺序为I1P4B2B3P7B5B6 的编码ES,通过打包,就将ES变成仅含有1种性质ES的PES包,如仅含视频ES的PES包,仅含音频ES的PES包,仅含其它ES的PES包。PES 包的组成见图2。

由图2可见,1个PES包是由包头、ES特有信息和包数据3个部分组成。由于包头和ES特有信息二者可合成1个数据头,所以可认为1个PES包是由数据头和包数据(有效载荷)两个部分组成的。
包头由起始码前缀、数据流识别及PES包长信息3部分构成。包起始码前缀是用23个连续"0"和1个"1"构成的,用于表示有用信息种类的数据流识别,是 1个8 bit的整数。由二者合成1个专用的包起始码,可用于识别数据包所属数据流(视频,音频,或其它)的性质及序号。例如:
比特序1 1 0 ×××××是号码为××××的MPEG-2音频数据流;
比特序1 1 1 0 ××××是号码为××××的MPEG-2视频数据流。
PES包长用于包长识别,表明在此字段后的字节数。如,PES包长识别为2 B ,即2×8 = 16 bit字宽,包总长为216-1=65535 B,分给数据头9 B(包头6 B + ES特有信息3 B ),可变长度的包数据最大容量为65526 B。尽管PES包最大长度可达(216 -1)=65535 B(Byte),但在通常的情况下是组成ES的若干个AU中的由头部和编码数据两部分组成的1个AU长度。1个AU相当于编码的1幅视频图像或1个音频 帧,参见图2右上角从ES到PES的示意图。也可以说,每个AU实际上是编码数据流的显示单元,即相当于解码的1幅视频图像或1个音频帧的取样。
ES特有信息是由PES包头识别标志、PES包头长信息、信息区和用于调整信息区可变包长的填充字节4部分组成的PES包控制信息。其中,PES包头识别 标志由12个部分组成:PES加扰控制信息、PES优先级别指示、数据适配定位指示符、有否版权指示、原版或拷贝指示、有否显示时间标记(PTS- Presentation Time Stamp)/解码时间标记(DTS-Decode Time Stamp)标志、PES包头有否基本流时钟基准(ESCR-Elementary Stream Clock Reference)信息标志、PES包头有否基本流速率信息标志、有否数字存储媒体(DSM)特技方式信息标志、有否附加的拷贝信息标志、PES包头有 否循环冗余校验(CRC-Cyclic Redundancy Check)信息标志、有否PES扩展标志。有扩展标志,表明还存在其它信息。如,在有传输误码时,通过数据包计数器,使接收端能以准确的数据恢复数据 流,或借助计数器状态,识别出传输时是否有数据包丢失。
其中,有否PTS/DTS标志,是解决视音频同步显示、防止解码器输入缓存器上溢或下溢的关键所在。因为,PTS表明显示单元出现在系统目标解码器 (STD-System Target Decoder)的时间, DTS表明将存取单元全部字节从STD的ES解码缓存器移走的时刻。视频编码图像帧次序为I1P4B2B3P7B5B6I10B8B9的ES,加入 PTS/DTS后,打包成一个个视频PES包。每个PES包都有一个包头,用于定义PES内的数据内容,提供定时资料。每个I、P、B帧的包头都有一个 PTS和DTS,但PTS与DTS对B帧都是一样的,无须标出B帧的DTS。对I帧和P帧,显示前一定要存储于视频解码器的重新排序缓存器中,经过延迟 (重新排序)后再显示,一定要分别标明PTS和DTS。例如,解码器输入的图像帧次序为I1P4B2B3P7B5B6I10B8B9,依解码器输出的帧次 序,应该P4比B2、B3在先,但显示时P4一定要比B2、B3在后,即P4要在提前插入数据流中的时间标志指引下,经过缓存器重新排序,以重建编码前视 频帧次序I1B2B3P4B5B6P7B8B9I10。显然,PTS/DTS标志表明对确定事件或确定信息解码的专用时标的存在,依靠专用时标解码器,可 知道该确定事件或确定信息开始解码或显示的时刻。例如,PTS/DTS标志可用于确定编码、多路复用、解码、重建的时间。
2)节目流(PS)
将具有共同时间基准的一个或多个PES组合(复合)而成的单一的数据流称为节目流(Program Stream)。PS包的结构如图3所示。
由图3可见,PS包由包头、系统头、PES包3部分构成。包头由PS包起始码、系统时钟基准(SCR-System Clock Reference)的基本部分、SCR的扩展部分和PS复用速率4部分组成。
PS包起始码用于识别数据包所属数据流的性质及序号。
SCR的基本部分是1个33 bit的数,由MPEG-1与MPEG-2兼容共用。SCR扩展部分是1个9 bit的数,由MPEG-2单独使用。SCR是为了解决压缩编码图像同步问题产生的。因为,I、B、P帧经过压缩编码后,各帧有不同的字节数;输入解码器 的压缩编码图像的帧顺序I1P4B2B3P7B5B6I10B8B9 中的P4、I10帧,需要经过重新排序缓存器延迟后,才能重建编码输入图像的帧顺序I1B2B3P4B5B6P7B8B9I10;视频ES与音频ES是以 前后不同的视频与音频的比例交错传送的。以上3条均不利于视音频同步。所以,为解决同步问题,提出在统一系统时钟(SSTC-Single System Time Clock)条件下,在PS包头插入时间标志SCR的方法。整个42 bit字宽的SCR,按照MPEG规定分布在宽为33 bit的1个基础字及宽为9 bit的1个扩展区中。由于MPEG-1采用了相当于33 bit字宽的90kHz的时间基准,考虑到兼容,对节目流中的SCR也只用33 bit。为了提高PAL或NTSC已编码节目再编码的精确性,MPEG-2将时间分解力由90kHz提高到27MHz光栅结构,使通过TS时标中的9 bit 扩展区后,精确性会更高。具体方法是将9 bit用作循环计数器,计数到300时,迅速向33 bit基本区转移,同时将扩展区计数器复原,以便由基本区向扩展区转移时重新计数。将42 bit作为时间标志插入PS包头的第5到第10个字节,表明SCR字段最后1个字节离开编码器的时间。在系统目标解码(STD-System Target Decoder)输入端,通过对27MHz的统一系统时钟(SSTC)取样后提取。显然,在编码端,STC不仅产生了表明视音频正确的显示时间PTS和解 码时间DTS,而且也产生了表明STC本身瞬时值的时间标记SCR。在解码端,应相应地使SSTC再生,并正确应用时间标志,即通过锁相环路(PLL- Phase Lock Loop),用解码时本地用SCR相位与输入的瞬时SCR相位锁相比较,确定解码过程是否同步,若不同步,则用这个瞬时SCR调整27MHz时钟频率。每 个SCR字段的大小各不相同,其值是由复用数据流的数据率和SSTC的27MHz时钟频率确定的。可见,采用时间标志PTS、DTS 和SCR,是解决视音频同步、帧的正确显示次序、STD缓存器上溢或下溢的好方法。
PS复用速率用于指示其速率大小。

系统头由系统头起始码、系统头长度、速率界限范围、音频界限范围、各种标志指示、视频界限范围、数据流识别、STD缓存器界限标度、STD缓存器尺寸标 度、(视频,音频,或数据)流识别等10个部分组成。各种标志部分由固定标志指示、约束系统参数数据流(CSPS-Constrained System Parameter Stream)指示、系统音频锁定标志指示、系统视频锁定标志指示4个部分组成。其中,CSPS是对图像尺寸、速率、运动矢量范围、数据率等系统参数的限 定指示。
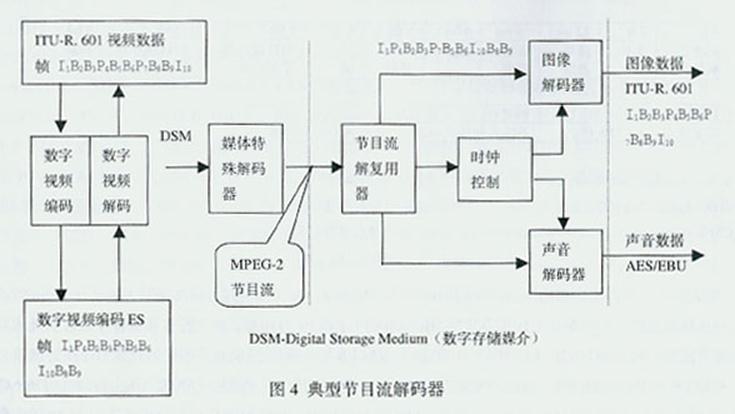
显然,PS的形成分两步完成:其一是将视频ES、音频ES、其他ES分别打包成视频PES包、音频PES包、其他PES包:使每个PES包内只能存在1种 性质的ES;每个PES包的第一个AU的包头可包含PTS和DTS;每个PES包的包头都有用于区别不同性质ES的数据流识别码。这一切,使解复用和不同 ES之间同步重放成为可能。其二是通过PS复用器将PES包复用成PS包,即将每个PES包再细分为更小的PS包。PS包头含有从数字存储媒介(DSM- Digital storage Medium)进入系统解码器各个字节的解码专用时标,即预定到达时间表,它是时钟调整和缓存器管理的参数。典型PS解码器如图4所示,图中示意了数字视 频解码器输出的、符合ITU-R. 601标准的视频数据帧顺序I1B2B3P4B5B6P7B8B9I10,与数字视频编码器输出的数字视频编码ES帧顺序 I1P4B2B3P7B5B6I10B8B9二者之间的关系。图中PS解复用器实际上是系统解复用器和拆包器的组合,即解复用器将MPEG-2 的PS分解成一个个PES包,拆包器将PES包拆成视频ES和音频ES,最后输入各自的解码器。系统头提供数据流的系统特定信息,包头与系统头共同构成一 帧,用于将PES包数据流分割成时间上连续的PS包。可见,一个经过MPEG-2编码的节目源是由一个或多个视频ES和音频ES构成的,由于各个ES共用 1个27MHz的时钟,可保证解码端视音频的同步播出。例如,一套电影经过MPEG-2编码,转换成1个视频ES和4个音频ES。显然,PS包长度比较长 且可变,用于无误码环境,适合于节目信息的软件处理及交互多媒体应用。但是,PS包越长,同步越困难;在丢包时数据的重新组成,也越困难。显然,PS用于 存储(磁盘、磁带等)、演播室CD-I、MPEG-1数据流。
3) 传输流(TS)
将具有共同时间基准或具有独立时间基准的一个或多个PES组合而成的单一的数据流称为传输流(Transport Stream)。TS实际是面向数字化分配媒介(有线、卫星、地面网)的传输层接口。对具有共同时间基准的两个以上的PES先进行节目复用,然后再对相互 可有独立时间基准的各个PS进行传输复用,即将每个PES再细分为更小的TS包,TS包结构如图5所示。
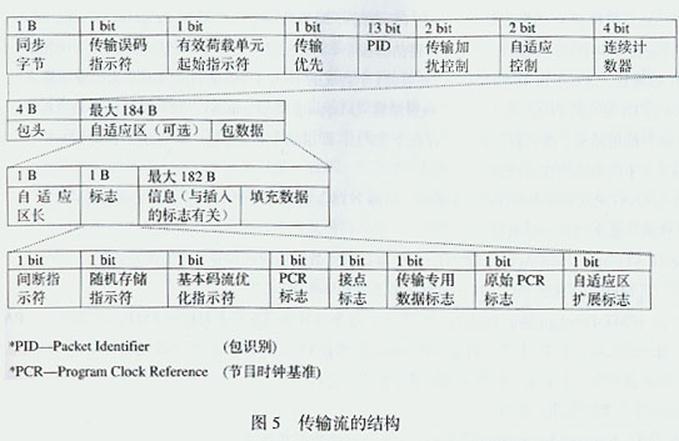
由图5可见,TS包由包头、自适应区和包数据3部分组成。每个包长度为固定的188 B,包头长度占4 B,自适应区和包数据长度占184 B。184 B为有用信息空间,用于传送已编码的视音频数据流。当节目时钟基准(PCR-Program Clock Reference)存在时,包头还包括可变长度的自适应区,包头的长度就会大于4 B。考虑到与通信的关系,整个传输包固定长度应相当于4个ATM包。考虑到加密是按照8 B顺序加扰的,代表有用信息的自适应区和包数据的长度应该是8 B的整数倍,即自适应区和包数据为23×8 B =184 B。
TS包的包头由如图所示的同步字节、传输误码指示符、有效载荷单元起始指示符、传输优先、包识别(PID-Packet Identification)、传输加扰控制、自适应区控制和连续计数器8个部分组成。其中,可用同步字节位串的自动相关特性,检测数据流中的包限制, 建立包同步;传输误码指示符,是指有不能消除误码时,采用误码校正解码器可表示1bit 的误码,但无法校正;有效载荷单元起始指示符,表示该数据包是否存在确定的起始信息;传输优先,是给TS包分配优先权;PID值是由用户确定的,解码器根 据PID将TS上从不同ES来的TS包区别出来,以重建原来的ES;传输加扰控制,可指示数据包内容是否加扰,但包头和自适应区永远不加扰;自适应区控 制,用2 bit表示有否自适应区,即(01)表示有有用信息无自适应区,(10)表示无有用信息有自适应区,(11)表示有有用信息有自适应区,(00)无定义; 连续计数器可对PID包传送顺序计数,据计数器读数,接收端可判断是否有包丢失及包传送顺序错误。显然,包头对TS包具有同步、识别、检错及加密功能。
TS包自适应区由自适应区长、各种标志指示符、与插入标志有关的信息和填充数据4部分组成。其中标志部分由间断指示符、随机存取指示符、ES优化指示符、 PCR标志、接点标志、传输专用数据标志、原始PCR标志、自适应区扩展标志8个部分组成。重要的是标志部分的PCR字段,可给编解码器的27MHz时钟 提供同步资料,进行同步。其过程是,通过PLL,用解码时本地用PCR相位与输入的瞬时PCR相位锁相比较,确定解码过程是否同步,若不同步,则用这个瞬 时PCR调整时钟频率。因为,数字图像采用了复杂而不同的压缩编码算法,造成每幅图像的数据各不相同,使直接从压缩编码图像数据的开始部分获取时钟信息成 为不可能。为此,选择了某些(而非全部)TS包的自适应区来传送定时信息。于是,被选中的TS包的自适应区,可用于测定包信息的控制bit和重要的控制信 息。自适应区无须伴随每个包都发送,发送多少主要由选中的TS包的传输专用时标参数决定。标志中的随机存取指示符和接点标志,在节目变动时,为随机进入I 帧压缩的数据流提供随机进入点,也为插入当地节目提供方便。自适应区中的填充数据是由于PES包长不可能正好转为TS包的整数倍,最后的TS包保留一小部 分有用容量,通过填充字节加以填补,这样可以防止缓存器下溢,保持总码率恒定不变。
4) 节目特定信息(PSI)
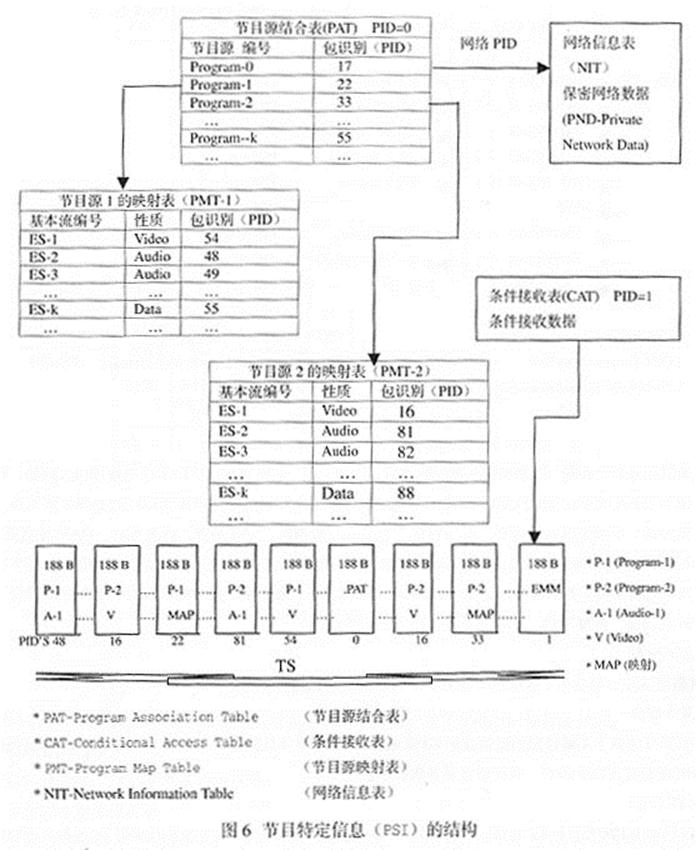
由上述可知,1个TS包由固定的188B组成,用于传送已编码视音频数据流的有用信息占用184B空间。但是,还需要传输节目随带信息及解释有关TS特定 结构的信息(元数据),即节目特定信息(PSI-Program Specific Information)。用于说明:1个节目是由多少个ES组成的;1个节目是由哪些个ES组成的;在哪些个PID情况下,1个相应的解码器能找到TS 中的各个数据包。这对于由不同的数据流复用成1个合成的TS是1个决定性的条件。为了重建原来的ES,就要追踪从不同ES来的TS包及其PID。因此,一 些映射结构(Mapping Mechanism),如节目源结合表(PAT)和节目源映射表(PMT)两种映射结构,会以打包的形式存在于TS上,即借助于PSI传输一串描述了各种 ES的表格来实现。MPEG认为,可用4个不同的表格作出区别:
● 节目源结合表(PAT-Program Association Table):在每个TS上都有一个PAT,用于定义节目源映射表。用MPEG指定的PID(00)标明,通常用PID=0表示 。
● 条件接收表(CAT-Conditional Access Table):用于准备解密数据组用的信息,如加密系统标识、存取权的分配、各个码序的发送等。用MPEG指定的PID(01)标明,通常用PID=1表示。
● 节目源映射表(PMT-Program Map Table):在TS上,每个节目源都有一个对应的PMT,是借助装入PAT中节目号推导出来的。用于定义每个在TS上的节目源(Program),即将 TS上每个节目源的ES及其对应的PID信息、数据的性质、数据流之间关系列在一个表里。解码器要知道分配节目的ES的总数,因为MPEG总共允许256 个不同的描述符,其中ISO占用64个,其余由用户使用。
● 网络信息表(NIT- Network Information Table):可传送网络数据和各种参数,如频带、转发信号、通道宽度等。MPEG尚未规定,仅在节目源结合表(PAT)中保留了1个既定节目号"0"(Program-0)。
有了PAT及 PMT这两种表,解码器就可以根据PID将TS上从不同的ES来的TS包分别出来。
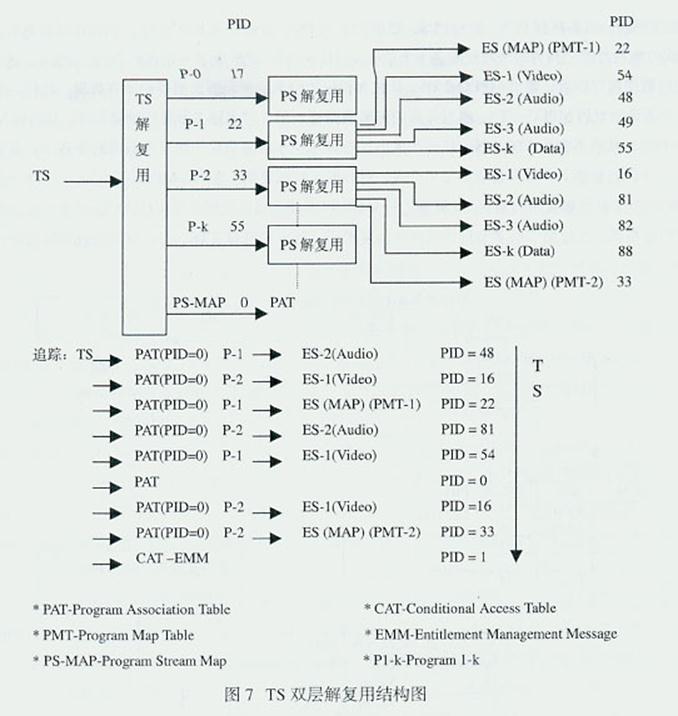
节目特定信息(PSI)的结构,如图6所示。根据PID将TS上从不同的ES来的TS包分别出来可分两步进行:其一是从PID=0的PAT上找出带有 PMT的那个节目源,如Program-1,或Program-2;其二是从所选择的PMT中找到组成该节目源的各个ES的PID,如从Program- 1箭头所指的PMT-1中ES-2所对应的Audio-1的PID为48,或从Program-2箭头所指的PMT-2中ES-1所对应的Video的 PID为16。同样,Program-1的MAP的PID为22,ES-1所对应的Video的PID为54;Program-2的PMT-2中ES-2 所对应的Audio-1的PID为81,ES-1所对应的Video的PID为16,MAP的PID为33;PAT的PID为0;CAT授权管理信息 (EMM-Entitlement Management Message)的PID为1。这样,就追踪到了TS上从不同的ES来的TS包及其PID,如图6所示的TS上不同ES的TS包的PID分别为48、 16、22、21、54、0、16、33、1。显然,解码器根据PID将TS上从不同的ES来的TS包分别出来的过程,也可以从图7的TS双层解复用结构 图中得到解释。要注意,MPEG-2的TS是经过节目复用和传输复用两层完成的:在节目复用时加入了PMT;在传输复用时加入PAT。所以,在节目解复用 时,就可以得到PMT,如图7中的ES (MAP) (PMT-1)和ES (MAP) (PMT-2);在传输解复用时,就可以得到PAT,如图7中的PS-MAP。将图6与图7对照,就可以知道解码器是如何追踪到TS上从不同的ES来的 TS包及其PID的。(未完待续)
4.系统的复用
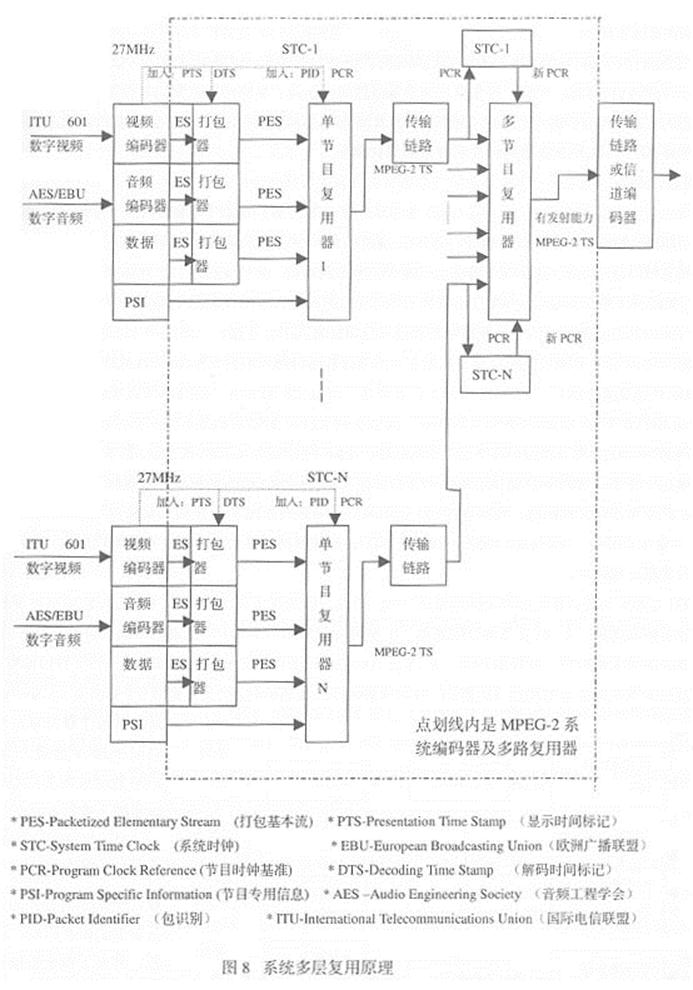
多个信号在同1个信道传输而不相互干扰,称为多路复用。如果将第一层的多个多路复用器先分别进行单节目传输复用,而后再进行第二层的多节目传输复用,就形 成了双层复用。图8是系统双层复用原理图。由图可见,编码器不仅有视频编码器和音频编码器,还有系统编码器。第一层的每个多路单节目传输复用器输入信号 有:ITU -R.601标准数字视频,如视频帧顺序为 I1B2B3 P4B5B6 P7B8B9 I10;AES/EBU数字音频数据;节目专用信息PSI及系统时钟STC 1-N等控制信号。其中视频编码器、音频编码器和数据提供给系统编码器的是基本流ES,视频ES的帧顺序为I1P4B2B3P7B5B6I10B8B9。 经过系统编码器加入PTS及DTS,并分别打包成视频PES、音频PES,数据本身提供的就是PES。PSI插入数据流,数据加密将有关的调用权、编码密 钥通过条件收视表插入MPEG-2 TS ,并将传输复用器从STC导出的PCR插入相应区段。这些视频PES、音频PES、数据PES及PSI,经过加入PID及PCR的传输复用器后,将输入基 本流ES分割成传输包片段,并为每个片段配备1个数据头(Header),就形成了一系列的TS包。然后,通过各个不同性质的数据流的数据包交织后,输出 MPEG-2 TS,其包含相应传输系统解码器所需要的所有数据。这样,从第一层的N个单节目复用器输出N股MPEG-2 TS,通过各自的传输链路输入第二层多路多节目传输复用器。从N路MPEG-2 TS中提取出N个PCR,从而再生出STC 1-N,最后产生出N个第二层多路多节目传输复用器用的新PCR。多节目传输复用器的任务是在分析的基础上,对多套节目复用合成,对数据包时标更新。因 为,MPEG只允许1个TS只能有1张节目源结合表PAT,多节目传输复用器需要对PSI表进行分析,以便建立对新数据流适用的PAT,修正有关数据包中 的时间标志,完成时标更新。经过第二层多节目传输复用器复用后,输出MPEG-2 TS,可以继续通过传输链路传输到解复用器,也可以采用误码保护编码、信道编码、调制技术后,通过卫星、有线电视、地面无线电视传输。例如,将第二层多节 目传输复用的MPEG-2 TS,经过QPSK信道调制上卫星,地面用户通过数字电视接收机的QPSK解调器、解复用器、解码器直接接收;有线电视台前端将卫星下行信号先后经过解调 器、解复用器、再复用器、QAM电缆调制器后,馈送至有线电视网,用户数字电视接收机通过QAM电缆解调器、解复用器、解码器接收;地面无线电视台将接收 的卫星信号先后经过解调器、解复用器、再复用器、COFDM电缆调制器后,馈送至地面发射台发射,用户可通过数字电视接收机的COFDM解调器、解复用 器、解码器接收。由上述可明白:
1)数据流的分割
将1个数据流逐段分割成多个数据包,便利于不同数据流的数据包交织。
2)节目最小组合
1个电视节目是由多个不同性质的数据流的ES组成的,1个电视节目的最小组合为1个视频流,1个音频流, 1个带字母、字符的数据流(Tele text),其它信息业务数据流。
3)PS与TS区别
节目流PS只能由1套节目的ES组成,传输流TS一般由多套节目的ES组成。由于在说明TS的基本流时标时,总是针对某1节目而言,因此TS选择了节目时钟基准PCR的概念,而不是系统时钟基准SCR。
5.系统的解码
由前述,MPEG-2系统要解决的问题是:
1)系统的复用与解复用
MPEG-2采用时分多路复用技术,让多路信号在同一信道上占用不同的时隙进行存储和传输,以提高信道利用率。
2)声音图像要同步显示
由于时分多路复用中的位时隙、路时隙、帧之间具有严格的时间关系,这就是同步。区分各路信号以此为据。为了恢复节目,先对ES进行解码。声音、图像信号的 重现需要同步显示,从而要求收发两端数据流要达到同步。为此,MPEG-2系统规范通过在数据中插入时间标志来实现:SCR或PCR为重建系统时间基准的 绝对时标;在有效PS和TS产生前,已插入PES的DTS和PTS为解码和重现时刻的相对时标。
3)解码缓存器无上下溢
MPEG-2系统是由视音频编码器、编码缓存器、系统编码器及复用器、信道网络编解码器及存储环境编解码器、系统解码器及解复用器、解码缓存器和视音频解 码器构成。其中,编码缓存器和解码缓存器延迟是可变的;信道网络编解码器及存储环境编解码器和从视/音频编码器输入到视音频解码器输出,延迟是固定的。这 表明,输入视/音频编码器的数字图像和音频取样,经过固定的、不能变的点到点延迟后,应该精确地同时出现在视音频解码器的输出端。编码及解码缓存器的可变 延迟的范围就应该受到严格限制,使解码缓存器无上、下溢。
为了解决复用、同步、无溢出问题,需要定义1个系统目标解码器(STD-System Target Decoder)模型。用于解释传输流TS解码并恢复基本流ES时的过程;用于在复用器数据包交织时确定某些时间的边界条件。因此,每个相应的MPEG- 2 TS必须借助于专门的解码器模型来解码。图9为TS的系统目标解码器模型。
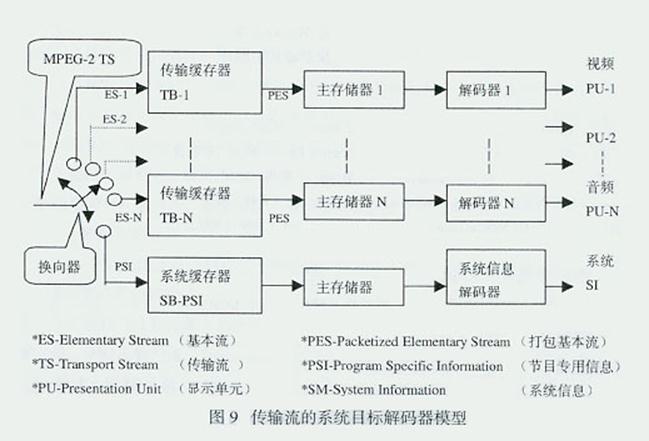
STD与实际解码器的主要差别是:STD对数据流的操作是瞬时完成的,无须时间延迟。而实际解码器是有延迟的。于是,可以利用这个差别,根据STD设计解 码器的缓存器的容量。例如,PAL制视频图像每隔1/25 s解码出1帧,压缩视频以4Mb/s码率到达视频解码器。要完全移走1帧图像,视频解码器比STD的时间要延迟1/25 s ,其缓存器容量要比STD规定容量大4Mb/s×1/25s = 0.16Mb。相对于STD,视频解码及显示有延迟,音频解码及显示也应延迟同样的时间,以便视音频正确同步。
要防止STD上溢或下溢,首先要确定解码延迟时间。为此,就要找出第一个DTS字段值与起始SCR字段值的差值。这个差值指出解码器第一个I帧在复用数据 流第一个SCR字段的最后1个字节之后的解码的时刻。利用I帧和P帧编码时间和显示时间的不同时性,计算出PTS与DTS之时间差,从而确定P帧在重新排 序缓存器中存储的时间,或P帧在重新排序缓存器中停留多长时间后开始解码。只要在解码器开始解码前,完全传送完1个存取单元,就不会产生下溢。若每个存取 单元在解码前瞬时的缓存器最大充满度与STD数据流缓存器容量大小比较适配,就不会产生上溢。
由图9可见,MPEG-2 TS包含N个ES的数据。按照PID值,根据ES的性质是视频的还是音频的或系统的,通过换向器,将每个相关数据包切换到相应路径,并分别传送给各个传输 缓存器(TB-Transport Buffer)。如视频ES输入到传输缓存器TB-1,音频ES输入到传输缓存器TB-N,PSI输入到系统缓存器SB-PSI.从STD输入端传送到 TB或SB是瞬时的。
TB的容量略大于2个传输流包的相应长度,MPEG规定为512 B。有利于较高复用器码率与较低解码存储器存取速度相适应,因缓存器读出采用较低的ES速率就可以实现。之所以要采用ES速率,是因为要降低解码硬件对处 理器支持的PSI信息分析的复杂性,从而规定缓存器读出速度最大不超过传输速率0.2%。视频基本数据流从TB-1输出时,由于包头再也不能识别TS数据 包结构,并已去除了全部相关传输记录信息,同时误差指示器查询可能有的包误差。因此,要抛弃PES包头,并将所有存储在TB-1中的PES包的净负荷数据 全部送到主存储器1,以便为解码器1提供数据。净负荷数据从TB-1传送到主存储器1是瞬时完成的。
DTS标明从STD的ES解码缓存器移走存取单元全部数据的时刻。对输入到主存储器1-N的所有存取单元的数据,都必须在DTS规定的瞬时移走。解码器 1-N及系统信息解码器的解码是瞬时完成的。顺便说明的是:传输数据包的同时,应将误差信息传送给解码器,以便对数据内容解扰,至于对内容的进一步解码, 已不是传输解码器的事情。数据解压缩、显示单元重建及在正确的显示时间显示已同步的序列,是解码系统的任务。
PTS标明STD出现显示单元(PU-Presentation Unit)的时间,显示之前,I帧和P帧需要经过重新排序缓存器的延迟。
节目专用信息PSI包括节目源结合表PAT(PID=0)、条件接收表CAT(PID=1)、节目源映射表PMT。由于PSI的数据量比较小,系统缓存器 SB-PSI的规模限制在1536B。到达系统信息解码器的PSI传输流,在该解码器中检查所期望节目的相关信息。解码器通过PSI表了解来自数据流的哪 些数据包,即数据中哪些PID应继续传送,其余不期望的节目数据包可忽略。显然,存储在节目源映射表PMT中的PID值,是用于检测TS内所需要的数据包 的。
二、MPEG-2的编码
编码是MPEG-2标准的核心内容之一,其涉及到MPEG-2视频流层结构、MPEG-2帧间编码结构、MPEG-2的类与级、MPEG-2运动估值等技术。
1. MPEG-2视频流层结构
为了便利于误码处理、随机搜索及编辑,MPEG-2用句法定义了1个层次性结构,用于表示视频编码数据。MPEG-2具体的视频流层结构如图10所示:将 MPEG-2视频流分为图像序列层(VSL-Video Sequence Layer)、图像组层 (GOPL-Group of Pictures Layer)、图像层(PL-Picture Layer)、宏块条层(SL-Slice Layer)、宏块层(ML-Macroblock Layer)、块层(BL-Block Layer)共6个部分,每层都有确定的功能与其对应。

1) 图像序列层(VSL)
VSL是由数据头及一系列图像组(GOP)组成的视频数据包,具体是指一整个要处理的连续图像。用于定义整个视频序列结构,可采用逐行或隔行两种扫描方 式。其中,数据头给出了有关图像水平大小、垂直大小、宽高比、帧速率、码率、视频缓存校验器的大小、量化矩阵、层号(Layer-id)、分级法 (Scalable mode)等,为解码提供了重要依据。
2) 图像组层(GOPL)
GOPL是图像序列层中若干图像组的1组图像,由数据头和若干幅图像组成,用于支持解码过程中的随机存取功能。图像分组是从有利于随机存取及编辑出发的, 不是MPEG-2结构组成的必要条件,可在分组与否之间灵活选择。其中,数据头给出了图像编码类型、码表选择、图像组头部开始码、视频磁带记录时间及控制 码、涉及B帧处理的closed GOP、broken link。为了给编辑数据流提供接入点,第1个总是I帧。
3)图像层(PL)
PL由数据头和1帧图像数据组成,是图像组层若干幅图像中的1幅,包含了1幅图像的全部编码信息。MPEG-2图像扫描可有逐行或隔行两种方式:当为逐行 时,图像为逐帧压缩;当为隔行时,图像为逐场或逐帧压缩,即在运动多的场景采用逐场压缩,在运动少的场景采用逐帧压缩。
因为,从整个帧中去除的空间冗余度比从个别场中去除得多。其中,数据头提供的基本部分有头起始码、图像编号的时间基准、图像(I,B,P)帧类型、视频缓 存检验器延迟时间等,扩展部分有图像编码扩展、图像显示扩展、图像空间分级扩展、图像时间分级扩展等。其中,基本部分由MPEG-1及MPEG-2共用, 扩展部分由MPEG-2专用。
一幅视频图像是由亮度取样值和色度取样值组成的,而亮度与色度样值比例的大小是由取样频率之比决定的。在MPEG-2中,亮度与色度之间的比例格式有4:2:0(或4:0:2)、4:2:2、4:4:4三种。
4) 宏块条层(SL)
SL由附加数据和一系列宏块组成,其最小长度 = 1个宏块,当长度 = 图像宽度时,就成了MPEG-2层面中最大宏块条长度。为了隐匿误差,提高图像质量,将图像数据分成由若干个宏块或宏块条组成的一条条位串。一旦某宏块条 发生误差,解码器可跳过此宏块条至下一宏块条的位置,使下一宏块条不受有误差而无法纠正的宏块条的影响,一个位串中的宏块条越多,隐匿误差性能就越好。为 此,附加数据部分定义了宏块条在整个图像中的位置、默认的全局量化参数、变量优先切换点(PBP-Priority Break Point)。其中,PBP用于指明数据流在何处分开,解码器要在两个数据流的恰当点处切换,以保证读取完整、正确的解码信息,确保解码完整无误。注意, 在离散余弦反变换(IDCT-Inverse Discrete Cosine Transform)时,SL可提供重新同步功能。
5) 宏块层(ML)
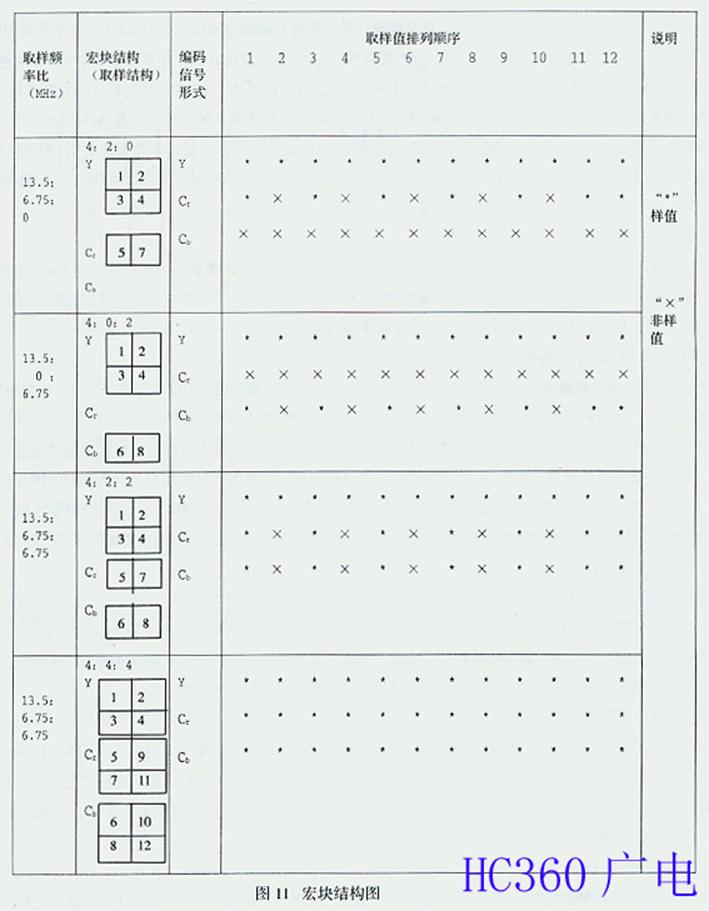
ML是宏块条层中一系列宏块中的1块,由附加数据、亮度块和色度块共同组成。其中,亮度为16×16像素块,称为宏块。宏块是码率压缩中运动补偿的基本单 元,由4个8×8像素块构成,用于消除P图像与B图像之间的时间冗余度。色度块由多少个8×8像素块构成,取决于亮度与色度之间取样频率的比例格式。如 MPEG-2有4:2:0、4:2:2、4:4:4三种宏块结构,取样结构如图11所示。图中4:2:0是由4个8×8亮度(Y)像素块、2个8×8红色 (Cr)像素块及0个8×8兰色(Cb)像素块构成的,或4:0::2是由4个8×8亮度(Y)像素块、0个8×8红色(Cr)像素块及2个8×8兰色 (Cb)像素块构成的,4:2:0与4:0:2是交替进行的,使垂直分解力降低(类似4:1:1使水平分解力降低),只含有1/4的色度信息。4:2:2 是由4个8×8亮度(Y)像素块、2个8×8红色(Cr)像素块及2个8×8兰色(Cb)像素块构成的,只含有1/2的色度信息。4:4:4是由4个 8×8亮度(Y)像素块、4个8×8红色(Cr)像素块及4个8×8兰色(Cb)像素块构成的,是全频宽YCrCb视频。宏块层ML包含P帧及B帧的运动 矢量(MV-Motion Vectors)。附加数据包含的信息有:表明宏块在宏块条层中位置的宏块地址、说明宏块编码方法及内容的宏块类型、宏块量化参数、区别运动矢量类型及大 小、表明以场离散余弦变换(DCT- Discrete Cosine Transform)还是以帧DCT进行编码的DCT类型。
6) 块层(BL)
BL是只包含1种类型像素的8×8像素块,即是单一的8×8亮度(Y)像素块,或是单一的8×8红色(Cr)像素块,或是单一的8×8兰色(Cb)像素 块。它是提供DCT系数的最小单元,即其功能是传送直流分量系数和交流分量系数。若需要对宏块进行DCT,也要先将宏块分成像素块后再进行。
2. MPEG-2帧间编码结构
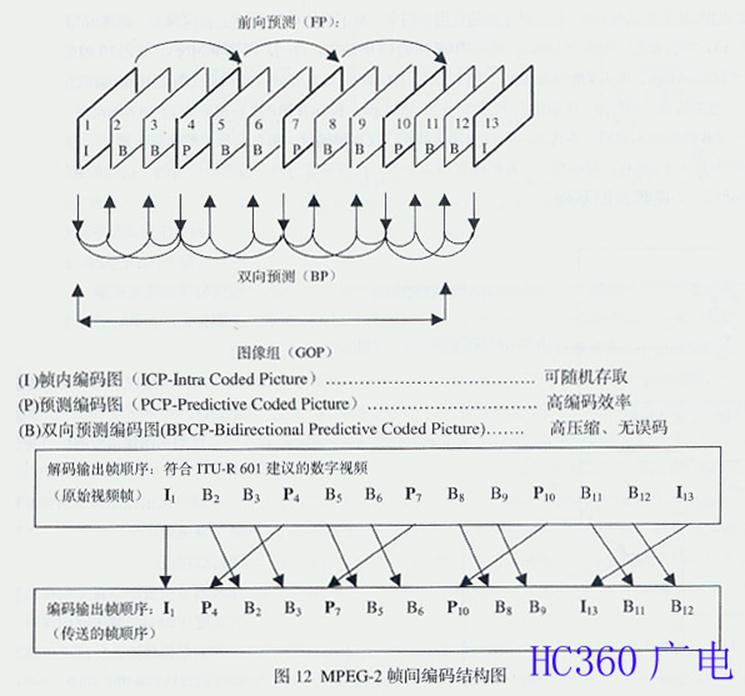
为了在高效压缩编码的条件下、获得可随机存取的高压缩比、高质量图像,MPEG定义了I、P、B三种图像格式,分别简称为帧内图(Intra Picture)、预测图(Predicted Picture)及双向图(Bidirec tional Picture),即I图、P图及B图,用于表示1/30s时间间隔的帧序列画面。因为,要满足随机存取的要求,仅利用I图本身信息进行帧内编码就可以 了;要满足高压缩比和高质量图像的要求,单靠I图帧内编码还不行,还要加上由P图和B图参与的帧间编码,以及块匹配运动补偿预测,即用前一帧图像预测当前 图像的因果预测和用后一帧图像预测当前图像的内插预测。这就要求帧内编码与帧间编码平衡,因果预测与内插预测间的平衡。平衡的结果是随机存取的高压缩比、 高质量图像的统一。图12是MPEG-2帧间编码结构图,其中:
1) 帧内编码图(ICP)
I图为不要基准图像编码作为基准所产生的图像,称为帧内编码图(ICP-Intra Coded Pictures)。特点是:数据量最大;帧内中等程度压缩;无运动预测,可采用自相关性,即帧内相邻像素、相邻行的亮度、色度信号都具有渐变的空间相关 性,可作静止图像处理,无条件传送;图像可随机进入压缩图像数据序列,进行编码。
2) 预测编码图(PCP)
P图是以最近的上一个I图或P图为基准进行运动补偿预测所产生的图像,称为预测编码图(PCP-Predictive Coded Pictures)。P图的特点是:本身是前I图或P图的前向预测(FP-Forward Prediction)结果,也是产生下一个P图的基准图像;高编码效率,与I图相较,可提供更大的压缩比;前一个P图是下一个P图补偿预测的基准,如果 前者存在误码,则后者会将编码误差积累起来、传播下去。
3) 双向预测编码图(BPCP)
目前对B图有两种趋同的理解:其一,B图是同时以前面的I图或P图和后面的P图或I图为基准进行运动补偿预测所产生的图像,称为双向预测编码图 (BPCP-Bidirectional Predictive Coded Picture)。前面的I图或P图代表"过去信息",后面的P图或I图代表"未来信息",由于同时使用了"过去"和"未来"两种信息,所以称为双向预 测。其二,由于帧序列相邻帧画面间的运动部分具有连续到时间相关性,可将当前画面看成是前一画面某一时刻图像的位移,当然位移方向及幅值在帧内各处未必相 同,只要用前面最近时刻的I图或P图及代表运动的位移信息,便可预测出当前图像,称为前向预测(FP)。根据某时刻的图像及反映位移信息的运动矢量,预测 出某时刻以前的图像,以便预测出前一帧中没有显露而现在出现的信息,称为后向预测(BP-Backword Prediction)。B图是将前向预测(FP)与后向预测(BP)同时使用并取其平均值后所产生的图像,称为双向预测图或平均值预测图。
由图12可见,一个GOP由I为起始的一串IBP帧组成,GOP的长度是前一个I帧到下一个I帧之前的B帧之间的间隔,如 I1B2B3P4B5B6P7B8B9I10中从I1到B9就是GOP的长度。GOP越长,MPEG-2编码越有效,而数据流的编辑及组接越困难。一般, 最多由12帧组成。基准帧重复频率的不同,可提供不同的输出码率。GOP的结构随码率变化而不同,如码率大于40Mbps时,帧重复方式为只有I 帧,GOP最短,具有高效率的优点;码率为15-40Mbps时,帧重复方式为IB,GOP较短;码率小于15 Mbps时,帧重复方式为IBP或IBBP,GOP较长,有延迟,影响存取速度。总之,图像质量随着码率10-50 Mbps的升高而提高,随着帧重复方式I-IB-IBBP使GOP变长而增长。尽管帧重复方式可以是IP,IB,IBP,IBBP,甚至是只有I帧,但针 对不同的应用及码率,有不同的GOP结构:新闻编采,码率18Mbps,采用IB帧的GOP结构;节目分配,码率20Mbps,采用IBBP帧的GOP结 构;存档,码率30Mbps,采用IB帧的GOP结构:后期制作,码率50Mbps,采用I帧GOP结构。图13表示了GOP与图像质量的关系及应用,图 中编码规则是:I帧4:2:2 @ ML MPEG速率为40-50Mbps;IBIBIB序列速率为25-30Mbps;长GOPIBP序列速率为12-18 Mbps。

系统对B帧像素不编码、不传送、不作为预测基准。仅在解码时,用双向预测的插值法建立,如I1与P4之间的B2、B3帧由I1和P4加权内插而建立。B帧像素块数据中,仅携带着为每个像素块设置的"运动矢量"。
3.MPEG-2视频压缩基础
码率压缩要从视觉对象、视觉生理、视觉心理3个方面入手,研究符合于人类视觉规律的视觉模型。由于视觉心理是1个很复杂的问题,难以得到其规律。因此,码率压缩只能在利用图像信号的统计特性和人类眼睛的视觉特性的基础上来进行。
1) 利用图像信号的统计特性进行压缩
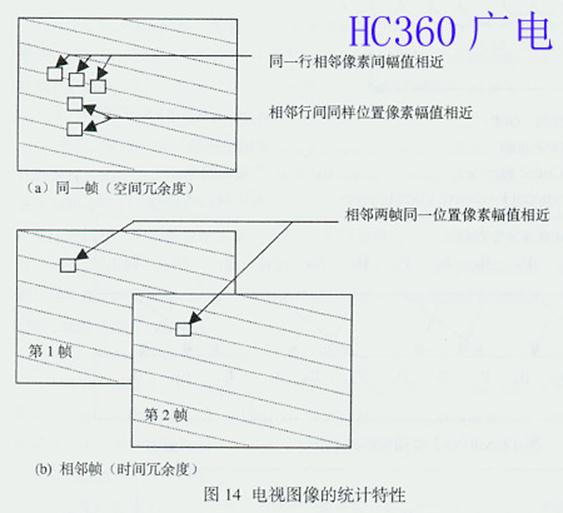
同一帧电视图像中相邻像素之间的幅度值相近,即同一行上的相邻像素之间幅值相近,相邻行之间同样位置上的像素幅值相近,体现了电视图像的空间冗余度;相邻 两帧电视图像同一位置上像素幅度值相近,体现了电视图像的时间(动态)冗余度,如图14所示。另外,每个像素所用bits数的多少表示了比特结构,多用的 比特数为冗余量,体现了静态(比特结构)冗余度。
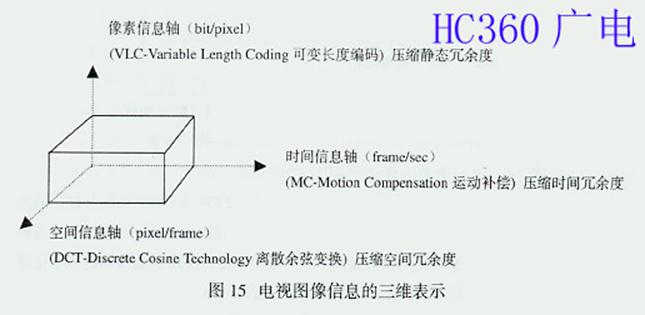
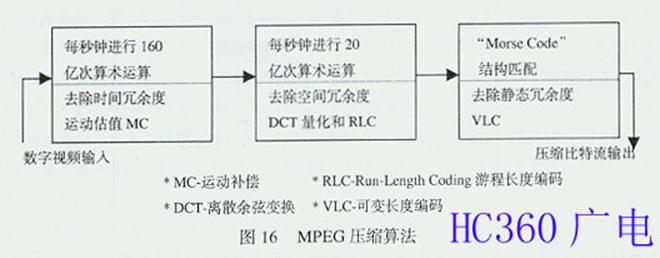
因此,为了清楚地了解空间冗余度、时间冗余度和静态冗余度三者之间的关系,可以通过图15所示的电视图像信息的三维表示来说明。需要指出的是采用运动补偿 (MC)去除时间冗余度要进行160亿次的算术运算;采用离散余弦变换(DCT)和游程长度编码(RLC)去除空间冗余度要进行20亿次的算术运算;采用 可变长度编码(VLC)去除静态(比特结构)冗余度要象"Morse Code"那样进行比特匹配。MPEG压缩算法如图16所示。为了减少计算量,最佳算法的探讨及其标准化是很重要的。
2) 利用人眼的视觉特性进行压缩
人眼对构成图像的不同频率成分、物体的不同运动程度等具有不同的敏感度,这是由人眼的视觉特性所决定的,如人的眼睛含有对亮度敏感的柱状细胞1.8亿个, 含有对色彩敏感的椎状细胞0.08亿个,由于柱状细胞的数量远大于椎状细胞,所以眼睛对亮度的敏感程度要大于对色彩的敏感程度。据此,可控制图像适合于人 眼的视觉特性,从而达到压缩图像数据量的目的。例如,人眼对低频信号的敏感程度大于对高频信号的敏感程度,可用较少的bit数来表示高频信号;人眼对静态 物体的敏感程度大于对动态物体的敏感程度,可减少表示动态物体的bit数;人眼对亮度信号的敏感程度大于对色度信号的敏感程度,可在行、帧方向缩减表示色 度信号的bit数;人眼对图像中心信息的敏感程度大于对图像边缘信息的敏感程度,可对边缘信息少分配bit数;人眼对图像水平向及垂直向信息敏感于倾斜向 信息,可减少表示倾斜向信息高频成分的bit数等。在实际工作中,由于眼睛对亮度、色度敏感程度不一样,故可将其分开处理。
为此,将单元分量RGB改变为YUV(或YCrCb)全分量。在编码时强调亮度信息,可去掉一些色度信息,如4:4:4变为4:2:2,码率由270Mbps降低到180Mbps。
由上述可见,电视系统存在着冗余信息,在传输图像信息之前,只要将这些冗余信息去除,就可以实现适度的压缩。由于去除这些冗余信息对图像质量无影响,故称 其为"无损压缩"。如,从视频信号中去除同步信息。无损压缩的压缩比不高,压缩能力有限。为了提高压缩比,MPEG标准采用了对图像质量有损伤的"有损压 缩"技术。
4. MPEG-2视频编码方式
为了提高压缩比及图像质量,MPEG-2视频编码采用运动补偿预测(时间预测+内插)消除时间冗余和不随时间变化的图像细节;采用二维DCT(图像像素+ 量化传输系数)分解相邻像素,消除观众不可见、不重要的图像细节;采用熵值编码(已量化参数+编码参数的熵),使bit数减少到理论上的最小值。对以上3 种压缩技术,作如下说明:
1)运动补偿预测

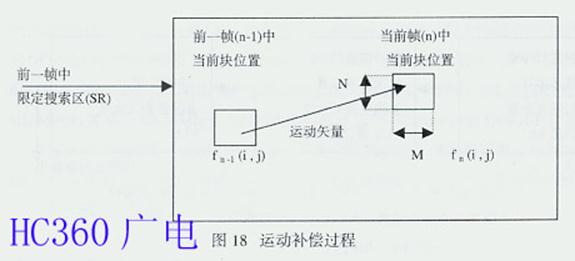
将存储器中前一图像帧的重建图像中相应的块按编码器端求得的运动矢量进行位移,这就是运动补偿过程。为了压缩视频信号的时间冗余度(Temporal Redundancy),MPEG采用了运动补偿预测(Motion Compensated Prediction),图17是其运动处理过程示意图。运动补偿预测假定:通过画面以一定的提前时间平移,可以局部地预测当前画面。这里的局部意味着在 画面内的每个地方位移的幅度和方向可以是不相同的。采用运动估值的结果进行运动补偿,以便尽可能地减小预测误差。运动估值包括了从视频序列中提取运动信息 的一套技术,该技术与所处理图像序列的特点决定着运动补偿性能的优劣。与画面16×16像素宏块相关的运动矢量支持接收机解码器中的运动补偿预测。所谓预 测,实际上是由前一(n-1)图像帧导出当前(n)图像帧所考虑像素的预测值,而后由运动矢量编码传输n帧的实际像素值与其预测值之间的差值。例如,设宏 块为M×N的矩形块,将图17中的n-1帧的宏块与n帧的宏块进行比较。这实际上是一个如图18所示的进行宏块匹配的运动补偿过程,即将n帧中16×16 像素的宏块与n-1帧中限定搜索区(SR)内全部16×16像素的宏块进行比较。若n-1帧图像亮度信号为f n -1 (i , j),n帧图像亮度信号为f n (i , j),其中(i , j)为n帧的M×N宏块的任意位置,并将n帧中的一个M×N的宏块看作是从n-1帧中平移而来的,而且规定同一个宏块内的所有像素都具有同样的位移值 (k,l) 。这样,通过在n-1帧限定搜索区(SR)内进行搜索,总可以搜索到某一宏块,使得该宏块与n帧中要匹配的宏块的差值的绝对值达到最小,并得到运动矢量的 运动数据,在n-1帧和运动数据的控制下,获得n帧的一个相应的预测值。照此办理,直到n帧的M×N宏块的任意位置(i , j)的像素全部通过n-1帧的像素预测出来。即n帧与n-1帧的相关函数F(k , l)的绝对值表示为 :
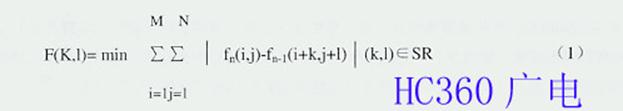
式(1)表明要匹配的宏块已经匹配,并得到水平及垂直位移为(k , l)的运动矢量的运动数据。通过匹配不仅将传输的差值减到最小,而且补偿了匹配对象在图像中的位移,这就是运动补偿。为了改善预测效果,可以采用场预测。 由于在电视图像连续帧之间有较大程度的共同性,即时间冗余度,多数图像之间差值极小,尤其是在大多数时间传输小范围内的值时,采用运动补偿预测可使码率明 显降低。在接收端的解码器中以同样的运动补偿预测重现预测值,重现预测值加上差值就得到像素的原幅值。图 19是基本MPEG视频编码器框图,图中虚线左边为运动补偿预测编码所需要的基本功能器件。其中固定存储器存储n-1帧的复原数据,将其与n帧数据一同送 入运动补偿参数估值器,估值后就可以得到运动矢量的数据。用运动矢量数据和n-1帧的复原数据去控制用于块匹配的可变存储器,将n帧的当前像素值预测出 来。这里,预测是按帧差仅有1帧进行的,实际上MPEG-1和MPEG-2可以当前帧之前若干帧的某一帧为基准进行预测。值就得到像素的原幅值。图 19是基本MPEG视频编码器框图,图中虚线左边为运动补偿预测编码所需要的基本功能器件。其中固定存储器存储n-1帧的复原数据,将其与n帧数据一同送 入运动补偿参数估值器,估值后就可以得到运动矢量的数据。用运动矢量数据和n-1帧的复原数据去控制用于块匹配的可变存储器,将n帧的当前像素值预测出 来。这里,预测是按帧差仅有1帧进行的,实际上MPEG-1和MPEG-2可以当前帧之前若干帧的某一帧为基准进行预测。
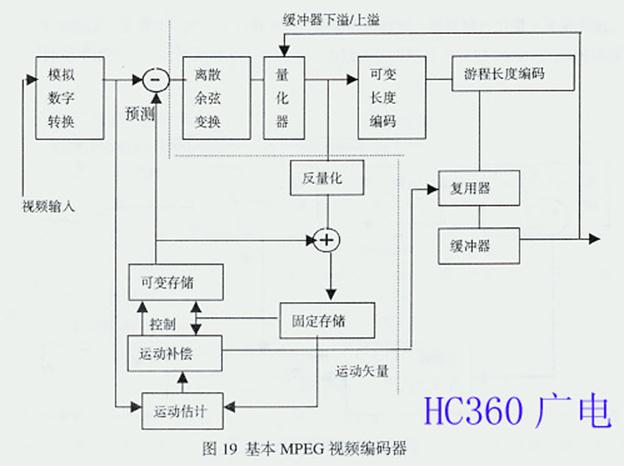
需要说明的是:MPEG定义了基于帧、基于场及双场的图像预测,也定义了16×8的运动补偿。
MPEG-2:有逐行扫描方式,可以采用基于帧的图像预测;有隔行扫描方式,也可以采用基于场的图像预测。因此,MPEG-2编码器要对每个图像先判断是 帧模式压缩还是场模式压缩。在隔行扫描方式下:运动少的场景时,采用基于帧的图像预测,因为基于帧的图像两相邻行间几乎没有位移,帧内相邻行间相关性强于 场内相关性,从整个帧中去除的空间冗余度比从个别场中去除得多;剧烈运动的场景时,采用基于场的图像预测,因为基于帧的相邻两行间存在1场延迟时间,相邻 行像素间位移较大,帧内相邻行间相关性会有较大下降,基于场的图像两相邻行间相关性强于帧内相邻行间相关性,在1帧内,场间运动有很多高频分量,从场间去 除的高频分量比从整个帧中去除的多。由上述可见,选择基于帧的图像预测还是基于场的图像预测的关键是行间相关性。所以,在进行DCT之前,要作帧DCT编 码或场DCT编码的选择,对16×16 的原图像或亮度进行运动补偿后所获得的差值作帧内相邻行间和场内相邻行间相关系数的计算。若帧内相邻行间相关系数大于场内相邻行间相关系数,就选择帧 DCT编码,反之选场DCT编码。帧DCT编码与场DCT编码如图20所示。(未完待续)

2)二维DCT
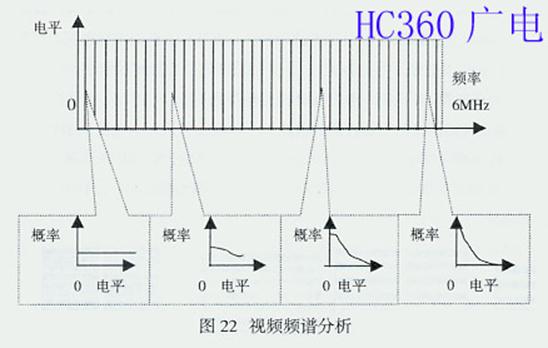
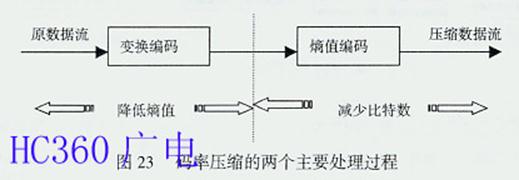
MPEG采用了Ahmed N.等人于1974年提出的离散余弦变换(DCT-Discrete Cosine Transform)压缩算法,降低视频信号的空间冗余度(Spatial Redundancy)。因为静态图像和预测误差信号两者具有非常高的空间冗余度,为降低空间冗余度最广泛地采用的频率域分解技术就是DCT。DCT将运 动补偿误差或原画面信息块转换成代表不同频率分量的系数集。这有两个优点:其一,信号常将其能量的大部分集中于频率域的1个小范围内,这样一来,描述不重 要的分量只需要很少的比特数;其二,频率域分解映射了人类视觉系统的处理过程,并允许后继的量化过程满足其灵敏度的要求。视频信号的频谱线在0-6MHz 范围内,而且1幅视频图像内包含的大多数为低频频谱线,只在占图像区域比例很低的图像边缘的视频信号中才含有高频的谱线。因此,在视频信号数字处理时,可 根据频谱因素分配比特数:对包含信息量大的低频谱区域分配较多的比特数,对包含信息量低的高频谱区域分配较少的比特数,而图像质量并没有可察觉的损伤,达 到码率压缩的目的。然而,这一切要在低熵(Entropy)值的情况下,才能达到有效的编码。能否对一串数据进行有效的编码,取决于每个数据出现的概率。 每个数据出现的概率差别大,就表明熵值低,可以对该串数据进行高效编码。反之,出现的概率差别小,熵值高,则不能进行高效编码。视频信号的数字化是在规定 的取样频率下由A/D转换器对视频电平转换而来的,以256层或1024层表示输入视频信号的幅度,每个像素的视频信号幅度随着每层的时间而周期性地变 化。每个像素的平均信息量的总和为总平均信息量,即熵值。由于每个视频电平发生几乎具有相等的概率,所以视频信号的熵值很高,如图21所示。 熵值是一个定义码率压缩率的参数,视频图像的压缩率依赖于视频信号的熵值,在多数情况下视频信号为高熵值,要进行高效编码,就要将高熵值变为低熵值。怎样 变成低熵值呢?这就需要分析视频频谱的特点。由图22视频频谱分析可见:大多数情况下,视频频谱的幅度随着频率的升高而降低。其中低频频谱在几乎相等的概 率下获得0到最高的电平。与此相对照,高频频谱通常得到的是低电平及稀少的高电平。显然,低频频谱具有较高的熵值,高频频谱具有较低的熵值。据此,可对视 频的低频分量和高频分量分别处理,获得高频的压缩值。

由上述可见,码率压缩基于如图23所示的变换编码和熵值编码两种算法。前者用于降低熵值,后者将数据变为可降低比特数的有效编码方式。在MPEG标准中, 变换编码采用的是DCT,变换过程本身虽然并不产生码率压缩作用,但是变换后的频率系数却非常有利于码率压缩。实际上压缩数字视频信号的整个过程分为块取 样、DCT、量化、编码4个主要过程进行,如图24所示。首先在时间域将原始图像分成N(水平)×N(垂直)取样块,根据需要可选择4×4、4×8、 8×8、8×16、16×16等块,考虑到消除数据相关性及计算复杂度的恰当的折衷,图中选择了8×8像素块。这些8×8取样的像素块代表了原图像各像素 的灰度值,其范围在139-163之间,并依序送入DCT编码器,以便将取样块由时间域转换为频率域的DCT系数块。DCT系统的转换分别在每个取样块中 进行,这些块中每个取样是数字化后的值,表示一场中对应像素的视频信号幅度值。式(2)和(3)分别为2维DCT正变换及反变换公式:
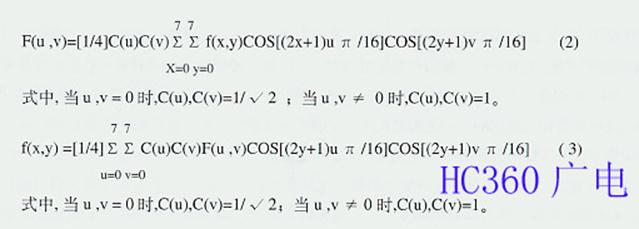
例如,当u,v = 0 时,离散余弦正变换(DCT)后的系数若为F(0,0)=1,则离散余弦反变换(IDCT)后的重现函数f(x,y)=1/8,是个常数值,所以将 F(0,0)称为直流(DC)系数;当 u,v≠0时,正变换后的系数为F(u,v)=0,则反变换后的重现函数f(x,y)不是常数,此时正变换后的系数F(u,v)为交流(AC)系数。
由DCT正变换公式(2)及反变换公式(3)可见,计算有一定的复杂性。但是,实际上这个函数是用代码来实现的,即两个余弦项只在程序开始时进行1次计 算,将计算的结果储存起来,而后通过查表就可以了,其它各项都可以通过查表解决,其程序采用了双层嵌套循环。图25是两个余弦项所构成的核函数Gu,v (x,y)计算的示意图,其中设N = 8, u = 2,v = 3;x = 4, y = 5,可求得G2,3(4,5) = G2,3(4)G2,3(5) = (-0.924) ×(+0.979)= - 0.905,以此类推可得到各个点的值,储存起来备查。通过查表,查出各个项的值,用代码来实现图24中DCT编码器输出的DCT系数。根据式(2)和 (3) 进行查表后,利用C语言程序对N×N个矩阵元素的代码采用双层嵌套循环计算如下:
for (u = 0 , u < N, u ++)
for (v = 0,v < N, v++) {
temp = 0,0;
for (x = 0, x < N, x++)
for (y = 0,y < N, y++) {
temp + = Cosines[x][u]*Cosines [y] [v] * pixel [x] [y];
}
temp* = sqrt(2 * N ) * Coefficients[u][v];
DCT[u] [v] = INT_ROUND(temp):
}
代码中用pixel[x][y]表示式中的f(x,y),用DCT[u][v]表示式中的F(u,v)。
当前,除了上述直接用双层嵌套循环定义DCT外,还有采用余弦变换矩阵来定义DCT的矩阵计算法,二者机理相同。
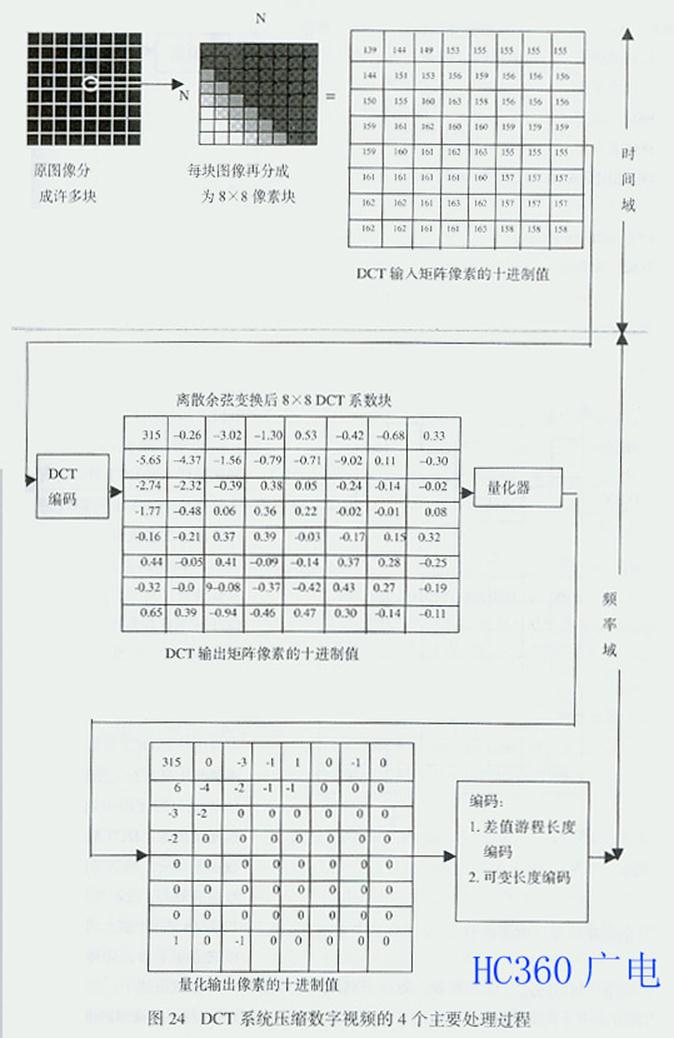
由图24及上述变换原理可察觉两点:其一,DCT后的64个DCT频率系数与DCT前的64个像素块相对应,DCT前后都是64个点,它只是1个本身没有 压缩作用的无损变换过程。其二,单独1场图像的全部DCT系数块的频谱几乎都集中在最左上角的系数块中,仅从该块的频谱中就可以形成1幅压缩图像;DCT 输出的频率系数矩阵最左上角的直流(DC)系数幅度最大,图24中为315,由于代表了x轴和y轴上的DC分量,所以它表示了输入矩阵全部幅度的平均值; 以DC系数为出发点向下、向右的其它DCT系数,离DC分量越远,频率越高,幅度值越小,图24中最右下角为-0.11,即图像信息的大部分集中于直流系 数及其附近的低频频谱上,离DC系数越来越远的高频频谱几乎不含图像信息,甚至于只含杂波。显然,DCT本身虽然没有压缩作用,却为以后压缩时的"取"、 "舍" 奠定了必不可少的基础.
3)量化
DCT系数采用量化(Quantization)进行压缩是1个关键性的运算,因为组合量化和游程长度编码可以提供最大的压缩量,也可以通过量化使编码器 输出匹配成1个给定的比特率。实际上,自适应量化是实现视觉质量的关键性工具之一,在量化中会减少频率域中描述DCT系数的精度。这一点可从图26基本 MPEG编码器的运动补偿预测编码过程简化电路图看出。用当前帧的原始图像的取样值减去当前帧解码复原值,其差值为:
fn - fn'= f n - e'n-f*n = en+f*n - e'n - f*n = en- e'n = qn (4)

式(4)中qn为量化误差,即量化误差的大小决定了图像恢复的精度。这表明,可以利用调整量化器误差大小来调整量化精度的高低。实际量化如图27所示,是 DCT编码输出的系数块中的每DCT系数除以量化器表中与其系数对应位置上的量化步长。量化步长是1个大于1的值,可根据编码图像的复杂度改变,甚至可对 每个DCT块改变量化矩阵值。根据DCT的结果分析,直流分量DC体现了大多数普通图像的内容,应该用较小的量化步长去分配;交流分量AC只体现了普通图 像所包含频谱中的很少一部分,应该用较大的量化步长去分配。量化的结果如图24所示,量化了的不同频率的频域系数趋向"0"值,而且这些大群的"0"在许 多情况下都是群集在较高频率上。因此,通过一串"0"的个数的编码而不是对每个单独的"0"本身的编码,可以取得附加的压缩效果,这就是游程长度编码 (RLC-Run Length Coding)。

4)编码
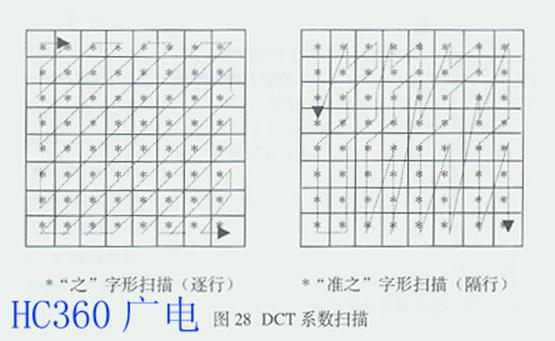
编码是DCT压缩系统的最后一步。在对64个DCT系数均匀量化后,系数分成为直流(DC)和交流(AC)两个部分。DC系数代表了分量模块的平均亮度, 可采用差值脉冲编码调制(DPCM)进行编码;对AC系数,由于非零的DCT系数大多数集中在矩阵的左上角,在进行编码之前先对量化后的DCT系数进行 "之"字形扫描,有利于得到一个长的"0"序列,提高编码效率。DCT系数扫描方式有"之"字形和"准之" 字形两种。逐行扫描采用"之"字形传送量化后的DCT系数,隔行扫描采用"准之"字形传送量化后的DCT系数,两种扫描方式如图28所示。
通过"之"字形扫描,将8×8的像素块转换成为1×64的码组,以便进行游程长度编码(RLC)和可变长度编码(VLC),如图29所示。

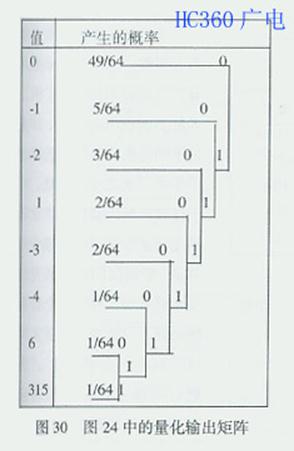
为了说明RLC和VLC,这里以图24中的量化输出编码为例,加以说明。量化输出矩阵如图30;量化输出的十进制值出现的概率统计如表3;变长编码如表 4。由表4可见,概率大的得到短编码,概率小的得到长编码。如果将这些编码按照图29中"之"字形扫描后数据流排序排列起来,如图31所示。
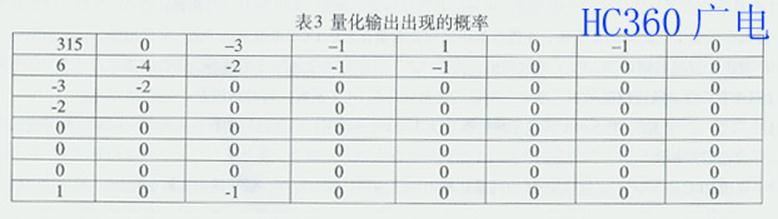
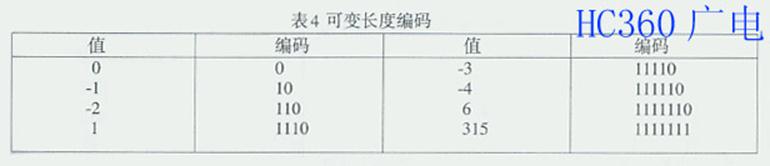
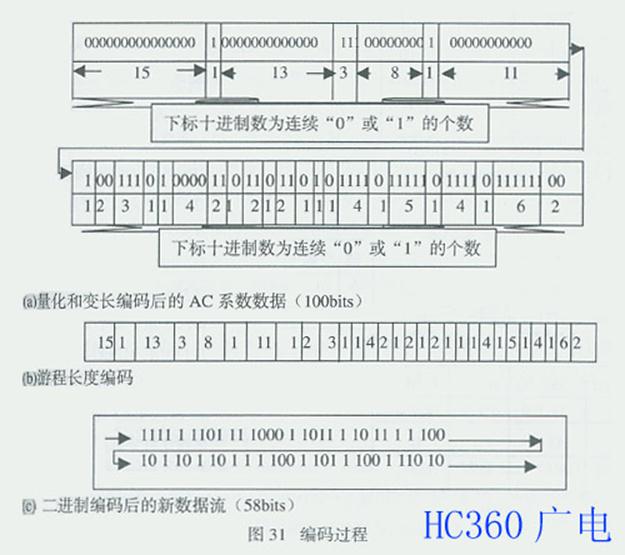
由图30,31和表3,4可见,原始的8×8像素块要用64×8=512比特,量化和变长编码后要用100比特,高于5:1压缩。经过游程长度编码后,二 进制编码的新数据流为58比特,其压缩比高于8:1。显然,编码是码率压缩的关键,因为编码是对数据流中的每个符号分配一种特定的码值的过程,选择最有效 的码值决定了编码的有效性,从而有效地降低熵值。这里,对DC分量进行DPCM编码以及对AC分量进行变换编码,如DCT,都是为了降低熵值 ;对AC分量进行熵值编码,如RLC和VLC,都是为了减少比特数。
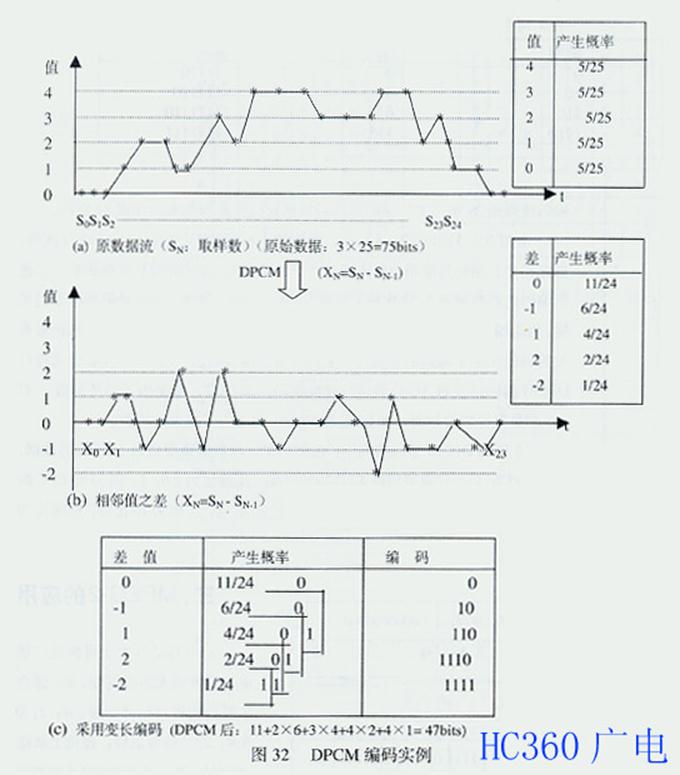
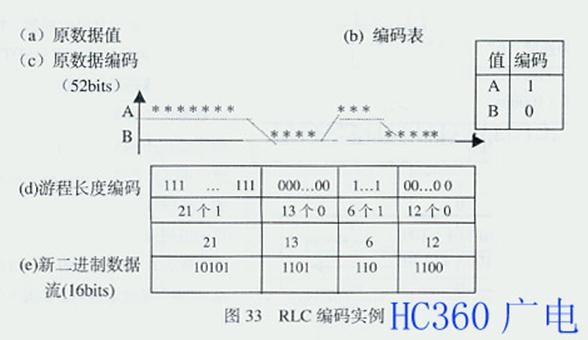
图32为DPCM编码的例子。由图可见,原数据需要传输75比特的数据,通过DPCM后,只需要传输47比特的数据,压缩比为1.6:1。图33是RLC编码的实例,由图可见,原数据52比特经过RLC后,压缩为16比特,压缩比为3.25:1。(未完待续)
三、MPEG-2的应用
MPEG-2基本上可满足广播电视系统的大多数需要,如:适合于隔行和逐行扫描图像;4:2:0和4:2:2图像取样;理论上高达16000像素 ×16000行的多种图像分解力和广播中常用的场频、帧频;编码的可分层特点可使SDTV或LDTV解码器从较高级HDTV的数据流中抽取所需要的信息。 为了适应不同场合对编码方法、操作模式、性能价格比的不同需要,在1993年3月悉尼会议上和7月的纽约会议上,基本上确定了表5所示的MPEG-2的型 与级规范。"型"是全部编码方法的1个子集,按压缩编码算法的复杂度大小,在表5中,由右向左定义了6个子集;"级"是依照型的编码参数所受到的不同限 制,按照图像分辨率的高低,在表5中,由上到下定义了4个等级的像素分解力。显然,MPEG-2标准具有广泛的通用性,为了满足多种不同应用的需要,将多 种不同的视频编码算法综合于单个句法之中。但是,对于接收端解码器若要求全部满足句法中规定的视频编码算法,解码器的设计将变的复杂而耗费,作为1个普通 编码器不可能也无必要实现MPEG-2的全部功能 。为此,提出了针对不同的应用,应满足句法中不同部分的要求。
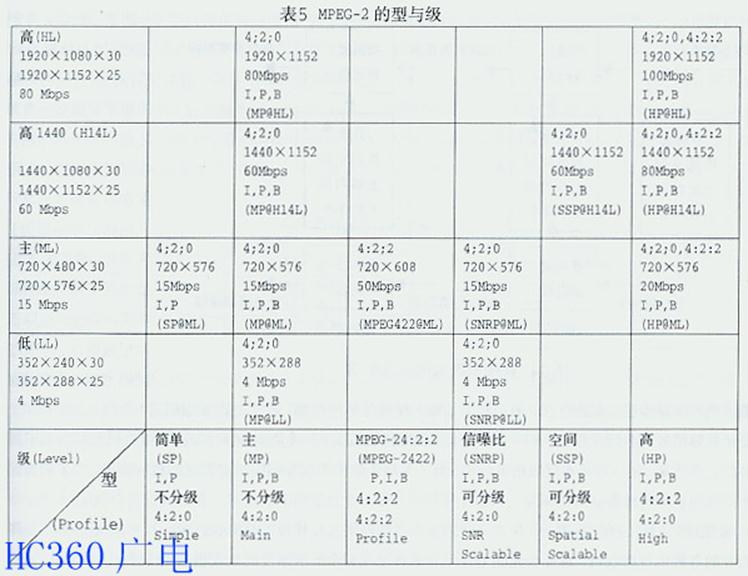
1. MPEG-2的型级概念
为适应不同场合的需要,MPEG-2引进型(Profile)和级(Level)的概念,为定义句法子集提供了方法。在单个句法的基础上,按压缩编码算法 的复杂度及不同应用,定义了6个句法子集,每个句法子集就是1种型。MPEG-2的型有简单型(SP)、主型(MP)、MPEG-2 4:2:2 型(后增加的)、信噪比可分级型(SNRP)、空间可分级型(SSP)、高型(HP)共6种。在同1种型里,需要处理的图像参数,如图像尺寸、帧率、码 率,也有不同。例如,表5的主型中包括4种不同的图像尺寸和4种有差别的码率,只有帧率是相同的。为此,MPEG-2还定义了低级(LL)、主级 (ML)、高1440级(H14L)、高级(HL)共4个级,以示对同1个型内不同参数的区别。显然,型定义了数据流可分级性和彩色空间分解力;级定义了 图像分辨力和每个型的最大码率。即,每个型定义了1组新的算法,如:型的性质,彩色格式、有否双向帧等,不同的组合有不同的算法。在同一型内的每个级定义 了参加运算的参数的取值范围,如:每帧图像行数、每行像素数、帧率、码率。由表7可见,与1994年MPEG-2标准通过时的MPEG-2的型与级相比, 增加了1个MPEG-2 422 @ M L。因为,MPEG-2 M P @ M L采用4:2:0色度亚取样,多版复制只能到2代,也不符合ITU-R 601标准。采用4:2:2可多代复制,也符合ITU-R 601标准要求。
在表5中的空格是不可能出现或尚未出现的组合。从高型到简单型,其压缩比由高到低。表5中已经定义的型、级组合,可用型、级的名称表示。如,目前最常用的 描述符是主型主级,可以表示为Main Profile @ Main Level ,简写为MP @ ML。对NTSC视频而言,相当于720×480分辨力,帧率30fps,码率小于15 Mbps。同样,对于PAL视频而言, 相当于720×576分辨力,帧率25fps,码率小于15 Mbps。图像用于ITU-R 601,如美国采用MP @ ML进行卫星直播,数字视盘也多有采用。同理,对于MP @ HL可用于高级电视(ATV),如美国HDTV大联盟(GA)采用MP @ HL的指标;对于MP @ H14L可用于HDTV;欧洲的实验HDTV采用了SSP @ H14L;对于MP @ LL可用于视频电话或电视会议。
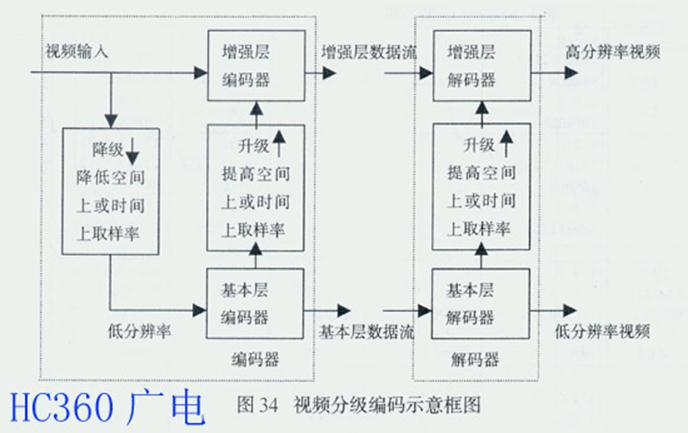
2. MPEG-2的分级编码
由于MPEG-2采用分级编码(Scalable Coding)已超出主型(Main Profile)编码算法所支持的范围,所以在信噪比型(SNR Profile)和空间型(Spatial Profile)两个子集中加入分级编码。所谓分级编码,是将整个视频数据流分为可逐级嵌入的若干层,不同复杂度的解码器可根据自身能力,从同一数据流中 抽出不同层进行解码,得到不同质量、不同时间分辨率、不同空间分辨率的视频信号。图34是视频分级编码示意框图。由图可见,视频分级编码采用了多级编码方 案。图中提供了基本和增强两层,每层支持的视频级别不同。其过程是:为了实现多清晰度的显示,首先将输入视频信号降级为1种较低清晰度视频,降级的方法是 在空间上或时间上降低取样率。然后,将降级视频编码成降低了码率的基本层数据流,再通过在空间上或时间上提升取样率的升级法,把降低了码率的基本层数据流 升级,用于对原始输入视频信号的预测,将预测误差编码成1个增强层数据流。若接收机需要显示视频信号的全部质量,则将基本层数据流和增强层数据流一起解码 就可实现;若接收机无能力或不需要显示视频信号的全部质量,则只对基本层数据流解码。为了满足传输频道和存储媒体对带宽的特殊要求,为了浏览视频数据库及 经不同网络视频传输等业务的需要,对每1层均应分配1个合适码率的视频,并对其进行分级编码。
分级编码的目的有二:其一,是在不同的业务之间提供互操作性(Interoperability),以灵活的方式支持具有不同显示功能的各种电视接收机。 对那些无能力或无要求再现视频全部清晰度的接收机,可只对分层数据流的子集进行解码,显示1个较低的空间或时间清晰度的低质量视频图像。这是通过在信噪比 型(SNR Profile)子集中采用分级编码实现的,即随着接收条件变差,使图像质量适度降级,以防出现数字广播固有的"峭壁效应"。其二,是对HDTV信源进行 分级编码,使其能灵活地支持多种清晰度,实现HDTV与SDTV产品的兼容,避免很耗费地将两个单独的数据流专门、分别地传输给HDTV和SDTV接收 机。即要避免采用同播(Simucast)方式,因为该方式是将每个视频节目以不同的空间分辨率、帧速率、码率等参数编码,传送给相应用户,带来的不必要 的经济负担。这是通过在空间型(Spatial Profile) 子集中采用分级编码实现的。另外,分级编码在媒体资产管理数据库浏览、多媒体环境下视频多清晰度重放等方面也得到应用。
分级编码有优点也有缺点。优点有二:使同1个数据流能适应不同特性的解码器,提高了灵活性、有效性;为视频广播、通信系统向更高时间分辨率、空间分辨率过渡,提供了技术保证。
其缺点也有二:该技术使编码器、解码器复杂化,成本增加;由于数据流中有多层编码,使编码效率下降。
尽管分级编码优、缺点参半,在MPEG-2的标准化进程中,人们还是想开发1个通用的分级编码方案,以满足所想象到的各种可能的应用。有些应用要求最低的 装置复杂性,另一些则要求尽可能高的编码效率。通用性与特殊性的冲突,使通用的分级编码方案化为泡影。但是,就是这种泡影,提醒人们,要从特殊问题的实际 出发,进行分级编码方案的制定,以满足各种特殊应用的需要。结果,分级编码为MPEG-2提供了空间分级(Spatial Scalability)、时间分级(Temporal Scalability)、信噪比分级性(SNR Scalability)和数据划分(Data Partitioning)4种工具,MPEG-2已对前3种进行了标准化:
1)空间分级
空间分级的出发点是使不同大小图像之间的服务具有兼容性,其采用的主要方法是空间补偿。
所谓空间补偿,是指将图像分为高、低两层处理,高层只传送高层图像与低层图像两者之差的数据,低层数据流经过解码、重取样的图像数据作为空间补偿的基准图像,将高层解码的差值数据加在低层相应的图像数据块上,就得到了高层图像数据。
这种编码数据流可提供至少两种空间分辨率的视频信号,1个是标准分辨率的视频信SDTV,另1个是高分辨率的视频信HDTV。分层数据流嵌套的第1层为基 本层(Base Layer),符合MPEG标准,其它为增强层(Enhancement Layer)。MPEG-2在序列层的数据头定义了两个变量:
Layer-id和Scalable-mode。用以指明该层的层号及使用的分级方法。现在采用的是空间分级法,利用基本层来提供SDTV,利用增强层来 提供HDTV。表6表明了空间分级应用情况。要获得SDTV,需将原视频序列每1帧图像经过低通滤波、亚取样,形成低分辨率的基本层图像序列,用 MPEG-2进行独立编码,得到基本层数据流,由基本层提供标准分辨率SDTV。要获得HDTV,需将原视频序列图像,经过时间、空间预测(参考帧可为已 编码全分辨率图像,或基本层图像经内插后形成的预测图像,或为全分辨率图像的预测图像加权平均值),将预测误差编码形成全分辨率增强层数据流,增强层实现 高分辨率信号HDTV。

2)时间分级
时间分级的出发点是实现不同帧速率视频图像服务之间的兼容性。该分级方式可提供帧速率不同、空间分辨率相同的视频信号。实现时间分级分两步进行:
第1步是以一定规律跳过原视频中的某些帧场,将剩余的帧场组成基本层图像序列,按MPEG-2编码,形成基本层数据流,由于基本层时间清晰度不太高,要在性能好的通道上传送。
第2步是将跳过的帧场,借助已编码基本层图像,采用运动补偿加DCT的方法进行编码,形成全帧速率的增强层数据流,借助时间分级,在基本层提供隔行扫描 HDTV,在增强层提供逐行扫描HDTV。由于增强层时间清晰度更高些,可在性能差一些的通道上传送。这里,基本层图像可直接作为增强层图像的部分帧,增 强层可以没有I帧,其可由最近解出的增强层图像或基本层图像预测出来。基本层图像中的B帧也可作为参考帧。表7是时间分级应用情况。

3)SNR分级性
信噪比分级性的出发点是实现不同质量视频图像服务之间的兼容性。该分级方式是,由1个图像信号源产生出具有相同空间分辨率的两个不同编码质量的视频数据流。实现SNR分级分两步进行:
第1步是对DCT系数进行粗(grob)量化,称为第1次量化,形成基本层数据流。
第2步是将粗量化之前的原DCT系数与第1次量化结果相减,对其差值进行第2次量化,即精细(feiner)量化,形成增强层数据流。
由上述可知,增强层进行的是误差DCT精细量化,其与基本层所进行的DCT系数粗量化密切相关,所以在解码时增强层与基本层要同时进行。表8是SNR分级应用情况。

4)数据划分
数据划分的目的,是希望在信号传输通道条件及发射功率受限时,也能收到质量略差些的图像,而不至于什么图像也接收不到。为此,MPEG-2采用了数据划分 技术,将对解码具有重要作用的信息,如包头、运动矢量、DCT系数(尤其是视频的低频DCT系数),放在误码性能好的通道中传送。对解码不太重要的部分, 如音频的DCT系数等,放在误码性能较差的通道中传送。当然,这种方案是在存在两个可用来传输、存储视频信号的通道时,才能实行。事实上,利用优先级的概 念,也可以进行数据划分。将编码数据流分成两个优先级不同的部分,如将编码数据流中的头信息、运动矢量、量化参数、低频DCT系数划分为高优先级 (High Priority Partition)部分,将编码数据流中的高频DCT系数、音频DCT系数划分为低优先级(Low Priority Partition)部分。这种用优先级进行数据划分的方法,可以将信道噪声及信元丢失造成的图像损伤,降至最低限度。
由上可见,为了解决通用性和特殊性之间的矛盾,MPEG-2采取了两个措施:1个是采用具有可分级性的型、级概念,用于描述不同的编码参数集;另1个是采 用具有可伸缩性的时间、空间、信噪比及数据划分4种视频编码工具,通过对数据流的1部分编码和对数据流的全部解码获得较低图像分辨率。从而使MPEG-2 成为真正的"通用标准"。
总之,MPEG-2可以在很大范围内对不同分辨率和不同输出码率的图像信号进行有效的压缩编码,已经成为真正的国际通用标准。在广播电视领域必将获得广泛应用。
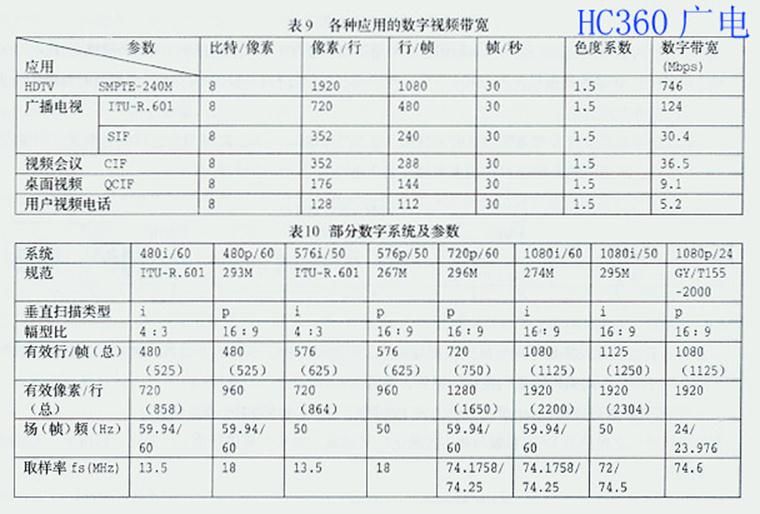
表9是各种应用的数字视频带宽,表10是部分数字系统及参数,供应用时参考。(全文完)
参考:http://blog.csdn.net/lanxch/article/details/3023899
pdf版下载:http://download.csdn.net/detail/xkfz008/4464316
转载自原文链接, 如需删除请联系管理员。
原文链接:MPEG2相关原理概述,转载请注明来源!