该程序使用了分布式进程的方法,在服务器端发布任务。在多台客户端同时进行下载,大大的提高了下载效率,同时,在对页面进行解析时使用了多个进程,分别用于提取新的URL和章节内容,以下是源码
服务器端源码:
给部分源码分为两部分,第一部分为任务发布器,第二部分将各个客户端返回的数据写入TXT文件中
第一部分:
#coding:utf-8
从multiprocessing.managers 导入队列
导入时间
从多处理导入BaseManager
导入
来自DataOutputToTxt的freeze_support 导入DataOutputtask_queue = queue.Queue()
result_queue = queue.Queue()
dataOutput = DataOutput()def get_task():
return task_queuedef get_result():
返回result_queueclass QueeuManager(BaseManager):
传递def win_run():
QueeuManager.register('get_task_queue',callable = get_task)
QueeuManager.register('get_result_queue',callable = get_result)manager = QueeuManager(address =('127.0.0.1',8001),authkey ='cyl'.encode('utf-8'))
manager.start()
try:
task = manager.get_task_queue()
result = manager.get_result_queue ()
num = int(input(“输入要下载的书籍数量\ n”))对于范围内的i(int(num)):
book = {}
book_name = input(“请输入第{0}本书的书名\ n”.format(i + 1))
book_url = input(“请输入书籍”链接(以0结尾)\ n“)
book_url = book_url [0:-1]
book ['name
'] = book_name book ['url'] = book_url
task.put(book)而num> 0:
如果不是result.empty():
data = result.get()
dataOutput.output_txt(data)
num = num - 1
print(“还剩{0}本书未爬取”.format(num) )
else:
time.sleep(5)
除了:
print('爬取失败')
finally:
manager.shutdown()
print(“爬取结束”)if __name__ =='__ main__':
freeze_support()
win_run()
第二部分:
导入编解码器
class DataOutput(object):
def output_txt(self,datas): book_name = datas
[0] +'。
txt'fout = codecs.open(book_name,'w',encoding ='utf-8')
datas.pop(0)
表示数据中的数据:
fout.write(“%s”%data ['title'])
fout.write(“\ r \ n”)
fout.write(“%s”%data ['zhengwen'])
fout.write(“\ r \ n \ n“)
fout.flush()
fout.close()
客户端源码
任务接收器
# coding :utf-8
from SpiderMan import SpliderMan
from multiprocessing.managers import BaseManager
from multiprocessing import freeze_support
class QueueManager(BaseManager):
passdef taskWorker():
server_address = '172.29.200.198'
m = QueueManager(address=(server_address, 8001), authkey='cyl'.encode('utf-8'))
m.connect()
task = m.get_task_queue()
result = m.get_result_queue()
while (not task.empty()):
startCrawl = SpliderMan()
book = task.get()
book_name = book['name']
book_url = book['url']
print("开始爬取{0}".format(book_name))
datas = startCrawl.start(book_url, book_name)
result.put(datas)
# 将爬取结果返回result队列if __name__ == '__main__':
freeze_support()
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue')
taskWorker()
爬虫调度器
from DataOutput import DataOutput
from HtmlDownloader import HtmlDownloader
from HtmlParser import HtmlParser
from UrlManager import UrlManager
from login import login
class SpliderMan(object):
def __init__(self):
self.manager = UrlManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.output = DataOutput()
self.datas = []
def crawl(self,root_url,bookName):
self.manager.add_new_url(root_url)
self.datas.append(bookName)
while(self.manager.has_new_urls()):
try:
new_url = self.manager.get_new_url()
html = self.downloader.download(new_url)
new_urls,data = self.parser.parser(html)
self.manager.add_new_urls(new_urls)
self.output.store_data(data,self.datas)
print("已经抓取%s个链接"%self.manager.old_url_size())except Exception as e:
print(e)
print("crawl failed")
break
return self.datas
def start(self,url,bookName):
pwd = 'long0000'
username = 'qingliu'
logIn = login(pwd, username)
logIn.start()
splider_man = SpliderMan()
books = splider_man.crawl(url,bookName)
return books
页面下载器
import requests
class HtmlDownloader(object):
def download(self,url):
if url is None:
return None
agent = 'Mozilla/5.0 (windows NT 5.1;rv:33.0) Gecko/20100101 Firefox/33.0'
headers = {'User_agent':agent}
r = requests.get(url,headers=headers)if r.status_code == 200:
r.encoding = 'gbk'
return r.text
return None
页面解析器
import requests
class HtmlDownloader(object):
def download(self,url):
if url is None:
return None
agent = 'Mozilla/5.0 (windows NT 5.1;rv:33.0) Gecko/20100101 Firefox/33.0'
headers = {'User_agent':agent}
r = requests.get(url,headers=headers)if r.status_code == 200:
r.encoding = 'gbk'
return r.text
return None
数据存储器:与服务器端数据存储器不同,该部分只是将同一本小说的各个章节整合打包成List
import codecs
class DataOutput(object):
def store_data(self,data,datas):
if data is None:
return
datas.append(data)
URL管理器
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()def has_new_urls(self):
return len(self.new_urls) != 0def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_urldef add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)def add_new_urls(self,urls):
if urls is None:
return
for url in urls:
self.add_new_url(url)def old_url_size(self):
return len(self.old_urls)
网站登录器
import requests
class login(object):
def __init__(self,pwd,username):
self.agent = 'Mozilla/5.0 (windows NT 5.1;rv:33.0) Gecko/20100101 Firefox/33.0'
self.header = {'User-Agent': self.agent}
self.post_url = 'http://www.biquge.com.tw/login.php?do=submit&action=login&usecookie=1&jumpurl='
self.postdata = {
'password': pwd,
'username': username, }
def start(self):
session = requests.session()
login_page = session.post(self.post_url, data=self.postdata, headers=self.header)
print(login_page.status_code)
if __name__ == '__main__':
pwd = 'xxxxx'
username = 'xxxxxx'
login = login(pwd,username)
login.start()
结果展示
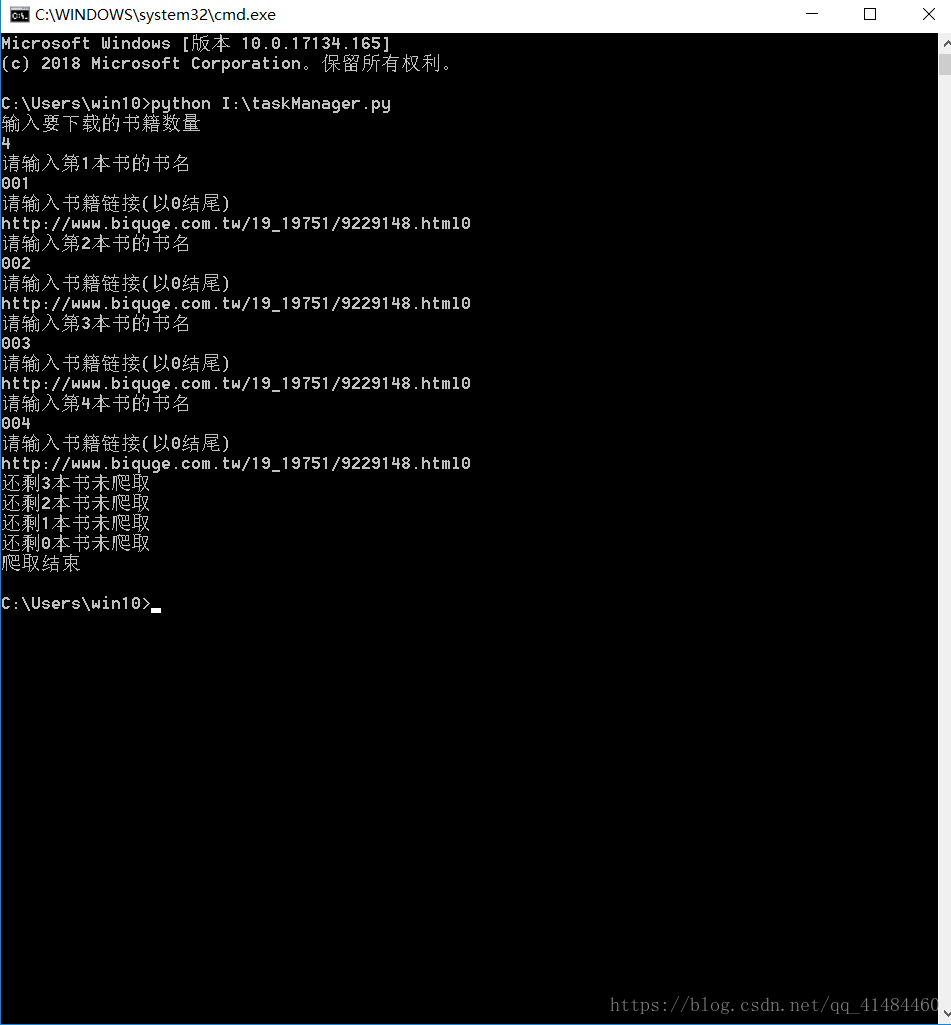
服务器端:

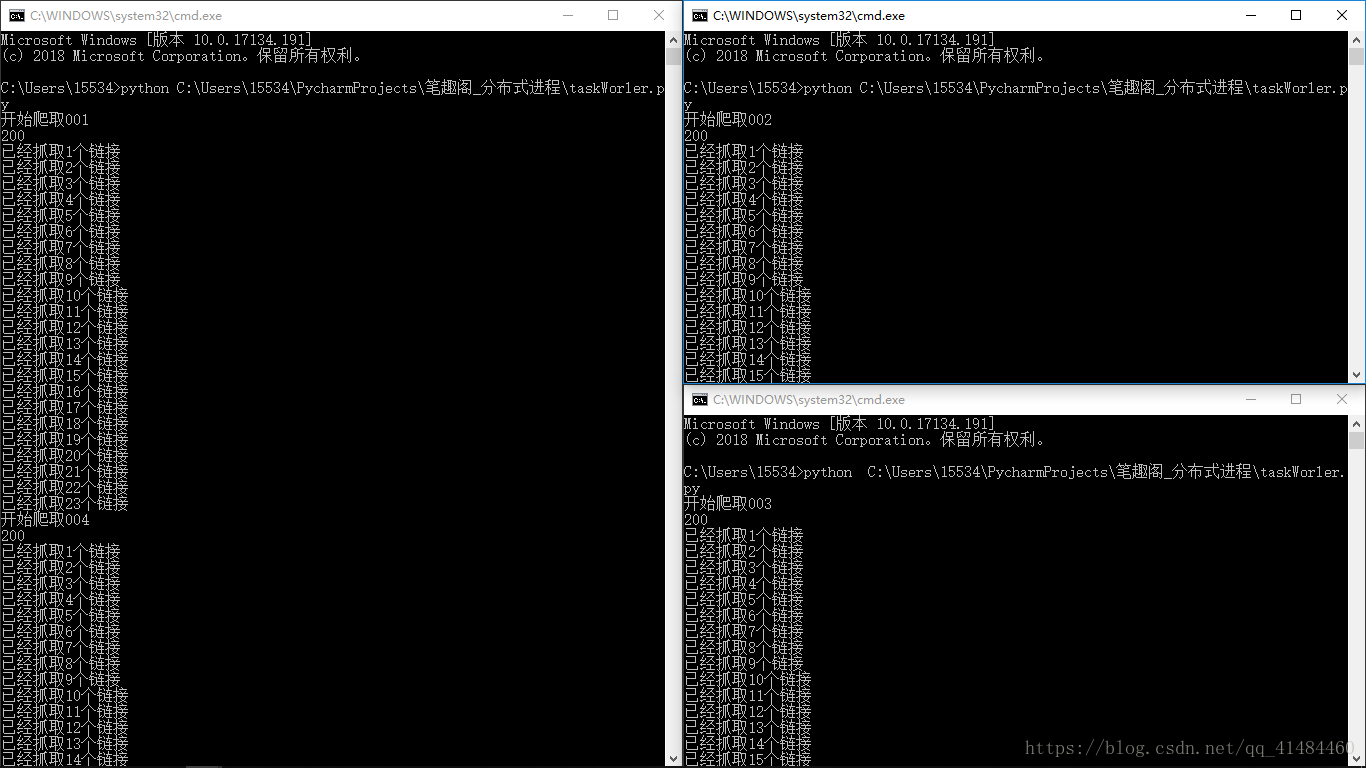
客户端:
爬取结果:

源码下载:https://download.csdn.net/download/qq_41484460/10578981
转载自原文链接, 如需删除请联系管理员。
原文链接:小说下载器,转载请注明来源!