上篇中已经搭建好了HPL测试环境,可以看到hpl-2.3/bin/test中生成了HPL.dat和xhpl文件。为了测试,我们可以对HPL.dat中的值进行调整。
一、参数介绍
第1行HPLinpack benchmark input file
第2行Innovative Computing Laboratory, University of Tennessee
前两行为说明性文字,不用作修改
第3行 HPL.out output file name (if any)
第4行 6 device out (6=stdout,7=stderr,file)
device out"为"6"时,测试结果输出至标准输出(stdout)
"device out"为"7"时,测试结果输出至标准错误输出(stderr)
"device out"为其它值时,测试结果输出至第三行所指定的文件中
第5行 1 #of problems sizes(N),矩阵的数量,如1即一个矩阵
第6行 24576 Ns
问题规模大小N值,要考虑内存容量的制约关系,有一个达到最佳性能的上限值。我们可以用物理内存的容量(单位:byte)乘以80%~85%来进行HPL的运算,剩余内存用于保证系统中的其他程序正常运行。由于一个双精度数占8个字节,所以再处以8,将结果开平方,得到的值比较接近最佳N值。根据经验似乎为384倍数更佳。
第7行 1 #of NBs ,测试块的个数
第8行 192 NBs,系数矩阵被分成NBxNB的循环块被分配到各个进程当中去处理,NB大小作为计算粒度,在很大程度上影响了计算性能的优劣。NB不可能太大或太小,一般在256以下,NBx8一定是Cache line的倍数等。一般通过单节点或单CPU测试可以得到几个较好的NB值,但当系统规模增加、问题规模变大,有些NB取值所得性能会下降。所以最好在小规模测试时选择3个左右性能不错的NB,再通过大规模测试检验这些选择。此处一般选择128。
第9行 1 PMAP process mapping (0=Row-,1=Column-major)
选择处理器阵列是按列的排列方式还是按行的排列方式。按HPL文档中介绍,按列的排列方式适用于节点数较多、每个节点内CPU数较少的系统;而按行的排列方式适用于节点数较少、每个节点内CPU数较多的大规模系统。在机群系统上,按列的排列方式的性能远好于按行的排列方式。此处一般选择1
第10行 1 # of process grids (P x Q)
第11行 1 Ps
第12行 4 Qs
第10~12行说明二维处理器网格(P × Q),二维处理器网格(P × Q)的有以下几个要求。
P × Q = 系统CPU数 = 进程数。一般来说一个进程对于一个CPU可以得到最佳性能。对于Intel Xeon来说,关闭超线程可以提高HPL性能。P≤Q;一般来说,P的值尽量取得小一点,因为列向通信量(通信次数和通信数据量)要远大于横向通信。P = 2n,即P最好选择2的幂。HPL中,L分解的列向通信采用二元交换法(Binary Exchange),当列向处理器个数P为2的幂时,性能最优。例如,当系统进程数为4,且问题规模较小的时候,P × Q选择为1 × 4的效果要比选择2 × 2好一些,但当问题规模较小的时候,二者相差并不大,因为此时节点内的计算开销相比通信开销要大很多,所以网格的分布方式对整个性能的影响就比较小了。 在集群测试中,P × Q = 系统CPU总核数。
第13行 16.0 threshold
第13行说明测试的精度。这个值就是在做完线性方程组的求解以后,检测求解结果是否正确。若误差在这个值以内就是正确,否则错误。一般而言,若是求解错误,其误差非常大;若正确,则很小。所以没有必要修改此值
第14行1 # of panel fact
第15行 0 1 2 PFACTs (0=left, 1=Crout, 2=Right)
第16行 2 # of recursive stopping criterium
第17行 2 4 NBMINs (>= 1)
第18行 1 # of panels in recursion
第19行 2 NDIVs
第20行 3 # of recursive panel fact.
第21行 0 1 2 RFACTs (0=left, 1=Crout, 2=Right)
第14~21行指明L分解的方式。在消元过程中,zHPL采用每次完成NB列的消元,然后更新后面的矩阵。这NB的消元就是L的分解。每次L的分解只在一列处理器中完成。对每一个小矩阵作消元时,都有3种算法:L、R、C,分别代表Left、Right和Crout。在LU分解中,具体的算法很多,测试经验,NDIVs选择2比较理想,NBMINs 4或8都不错。而对于RFACTs和PFACTs,对性能的影响不大。在HPL官方文档中,推荐的设置为:
1 # of panel fact
1 PFACTs (0=left, 1=Crout, 2=Right)
2 # of recursive stopping criterium
4 8 NBMINs (>= 1)
1 # of panels in recursion
2 NDIVs
1 # of recursive panel fact.
2 RFACTs (0=left, 1=Crout, 2=Right)
第22行 1 # of broadcast
第23行 0 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM)
第22、23行说明L的横向广播方式,HPL中提供了6种广播方式。其中,前4种适合于快速网络;后两种采用将数据切割后传送的方式,主要适合于速度较慢的网络。目前,机群系统一般采用千兆以太网甚至光纤等高速网络,所以一般不采用后两种方式。一般来说,在小规模系统中,选择0或1;对于大规模系统,选择3。推荐的配置为:
2 # of broadcast
3 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM)
第24行 1 # of lookahead depth
第25行 0 DEPTHs (>=0)
第24、25行说明横向通信的通信深度。这依赖于机器的配置和问题规模的大小,推荐配置为:
2 # of lookahead depth
0 1 DEPTHs (>=0)
第26行 0 SWAP (0=bin-exch,1=long,2=mix)
第27行 32 swapping threshold
第26、27行说明U的广播算法。U的广播为列向广播,HPL提供了3种U的广播算法:二元交换(Binary Exchange)法、Long法和二者混合法。SWAP="0",采用二元交换法;SWAP="1",采用Long法;SWAP="2",采用混合法。推荐配置为:
2 SWAP (0=bin-exch,1=long,2=mix)
60 swapping threshold
第28行 0 L1 in (0=transposed,1=no-transposed) form
第29行 0 U in (0=transposed,1=no-transposed) form
第28、29行分别说明L和U的数据存放格式。若选择"transposed",则采用按列存放,否则按行存放。推荐配置为:
0 L1 in (0=transposed,1=no-transposed) form
0 U in (0=transposed,1=no-transposed) form
第30行 1 Equilibration (0=no,1=yes)
第30行主要在回代中使用,一般使用其默认值
第31行 8 memory alignment in double (> 0)
第31行的值主要为内存地址对齐而设置,用于在内存分配中对齐地址。出于安全考虑,可以选择8
二、测试
本次测试的硬件环境如下
MPI+MKL+HPL(HPL 2.3,MKL 2018.1.163,MPI 2019.1.144)



因此调节了如下参数
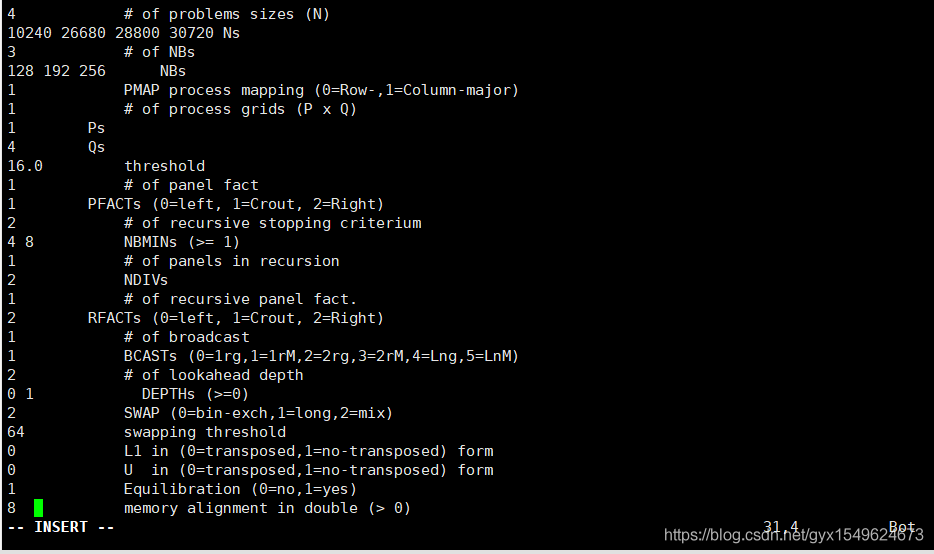
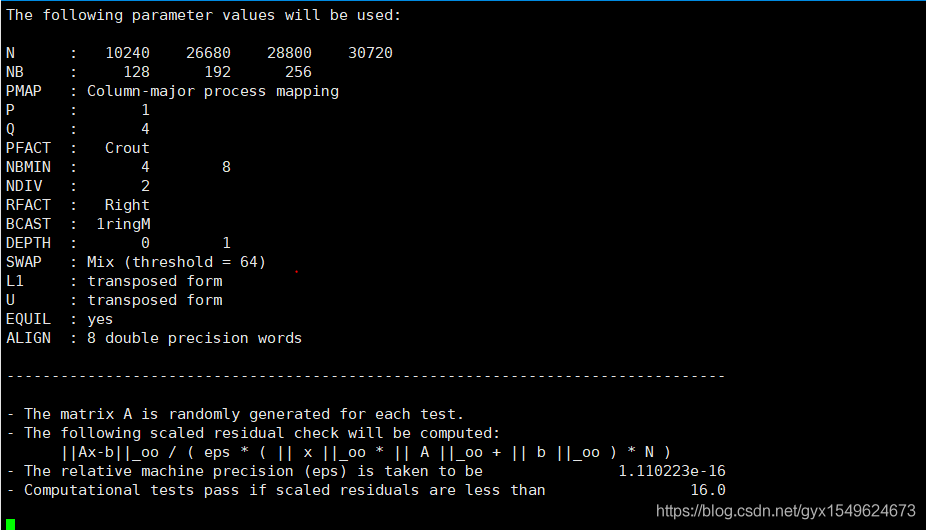
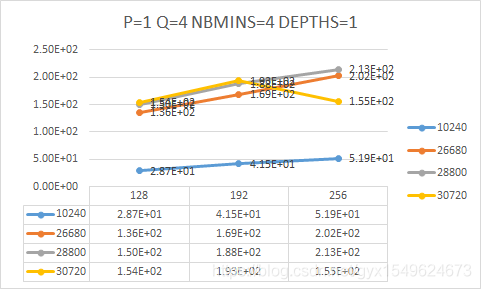
目前本机测试最好的一组
转载自原文链接, 如需删除请联系管理员。
原文链接:HPL测试,转载请注明来源!