DrugBank数据库简介
DrugBank数据库是唯一将详细的药品数据(即化学,药理学和制药)与综合药物靶点信息(即序列,结构和作用通路)相结合的“生物信息学和化学信息学”资源.DrugBank由加拿大卫生研究院,亚伯达省创新 - 健康解决方案和代谢组学创新中心(TMIC)提供支持,该中心是国家资助的研究以及支持广泛的尖端技术代谢组学研究的核心.DrugBank数据库查询包含以下信息:药品类型,药品简介,化学结构,药品成分,临床试验,药物靶点,酶,转运体,载体,药品图片,批准情况,批准的处方药,国外上市商品名,药物相互作用,制造商,包装商等。

DrugBank数据库功能
开发DrugBank数据库旨在缩小临床药品资源和化学药品数据库之间“深度与广度”的差距.DrugBank于2006年年首次发布,作为全面并完全可搜索的计算机药物资源,将药物分子(包括生物技术药物)的序列,结构和机制数据与其药物靶点的序列,结构和机制数据连接。作为临床导向的药品百科全书,DrugBank能够提供关于药品,药品靶点和药物作用的生物或生理结果的详细,最新,定量分析或分子量的信息。作为化学导向的药品数据库,DrugBank能够提供许多内置的工具,用于查看,排序,搜索和提取文本,图像,序列或结构数据。自数据库首次发布信息起,DrugBank已被广泛应用于计算机检索药物,药物“复原”,计算机检索药物结构数据,药物对接或筛选,药物代谢预测,药物靶点预测和一般制药教育。
DrugBank数据库小分子信息的解析,药物结构提取:
-
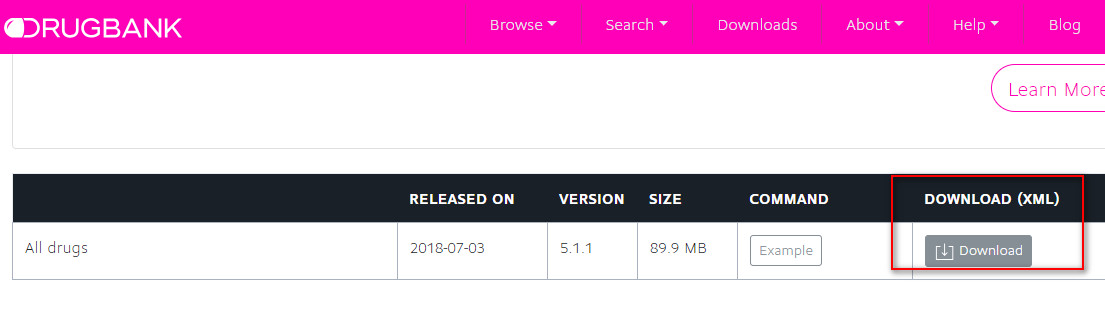
下载XML文件
https://www.drugbank.ca/releases/latest
-
基于Python3从含有药物信息的XML文件解析数据
# In[1]:
#!/usr/bin/python3
import untangle
import pandas as pd
import numpy as np
import os
# In[2]:
filename="drugbank_all_full_database.xml"
obj=untangle.parse(filename)
# In[3]:
#Building dataframe of chemical descriptors
#Data Frame of DrugBank Small Molecule Type Drugs
df_drugbank_sm=pd.DataFrame(columns=["drugbank_id","name","cas","smiles","logP ALOGPS", "logP ChemAxon", "solubility ALOGPS", "pKa (strongest acidic)", "pKa (strongest basic)"])
df_drugbank_sm
# In[4]:
i=-1
#iterate over drug entries to extract information
for drug in obj.drugbank.drug:
drug_type= str(drug["type"])
# select for small molecule drugs
if drug_type in ["small molecule", "Small Molecule", "Small molecule"]:
i=i+1
#Get drugbank_id
for id in drug.drugbank_id:
if str(id["primary"])=="true":
df_drugbank_sm.loc[i, "drugbank_id"]=id.cdata
#Drug name
df_drugbank_sm.loc[i,"name"]=drug.name.cdata
#Drug CAS
df_drugbank_sm.loc[i, "cas"]=drug.cas_number.cdata
#Get SMILES, logP, Solubility
#Skip drugs with no structure. ("DB00386","DB00407","DB00702","DB00785","DB00840",
# "DB00893","DB00930","DB00965", "DB01109","DB01266",
# "DB01323", "DB01341"...)
if len(drug.calculated_properties.cdata)==0: #If there is no calculated properties
continue
else:
for property in drug.calculated_properties.property:
if property.kind.cdata == "SMILES":
df_drugbank_sm.loc[i, "smiles"]=property.value.cdata
if property.kind.cdata == "logP":
if property.source.cdata == "ALOGPS":
df_drugbank_sm.loc[i, "logP ALOGPS"]=property.value.cdata
if property.source.cdata == "ChemAxon":
df_drugbank_sm.loc[i, "logP ChemAxon"]=property.value.cdata
if property.kind.cdata == "Water Solubility":
df_drugbank_sm.loc[i, "solubility ALOGPS"]=property.value.cdata
if property.kind.cdata == "pKa (strongest acidic)":
df_drugbank_sm.loc[i, "pKa (strongest acidic)"]=property.value.cdata
if property.kind.cdata == "pKa (strongest basic)":
df_drugbank_sm.loc[i, "pKa (strongest basic)"]=property.value.cdata
# In[5]:
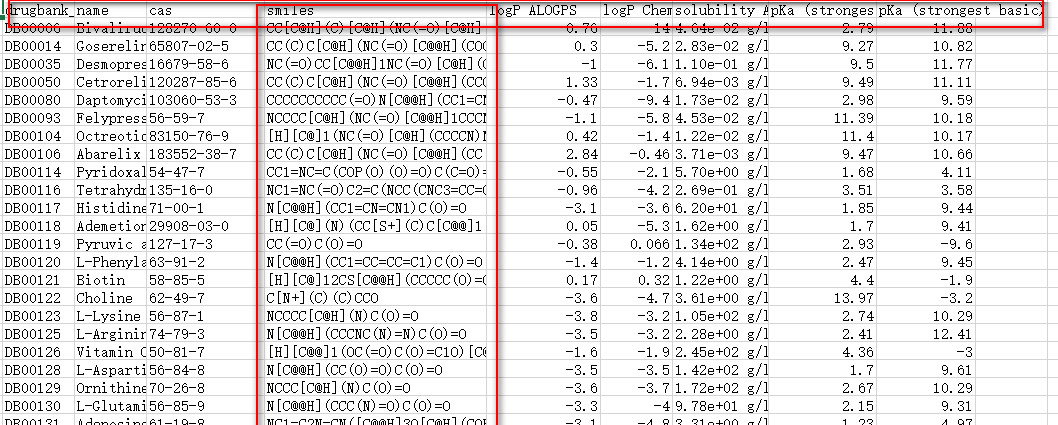
df_drugbank_sm.head(10)
# In[6]:
print (df_drugbank_sm.shape)
# In[7]:
#Drop drugs without SMILES from the dataframe
df_drugbank_smiles = df_drugbank_sm.dropna()
df_drugbank_smiles= df_drugbank_smiles.reset_index(drop=True)
print(df_drugbank_smiles.shape)
# In[8]:
df_drugbank_smiles.head()
# In[9]:
#write to csv
df_drugbank_smiles.to_csv("drugbank_smiles.csv", encoding='utf-8',index=False)
效果展示: