汽车之家图片的爬取
汽车之家有很多汽车的点评、价格、图片等信息,那么怎么才能编写一个爬虫来获得我们所需要的信息呢,很简单,两个工具便可以了,一个网页解析工具requests,一个正则匹配工具re,下面以Python语言编写爬虫。
首先在火狐或者chrome浏览器下打开汽车之家的网页,然后点击小型车,得到:

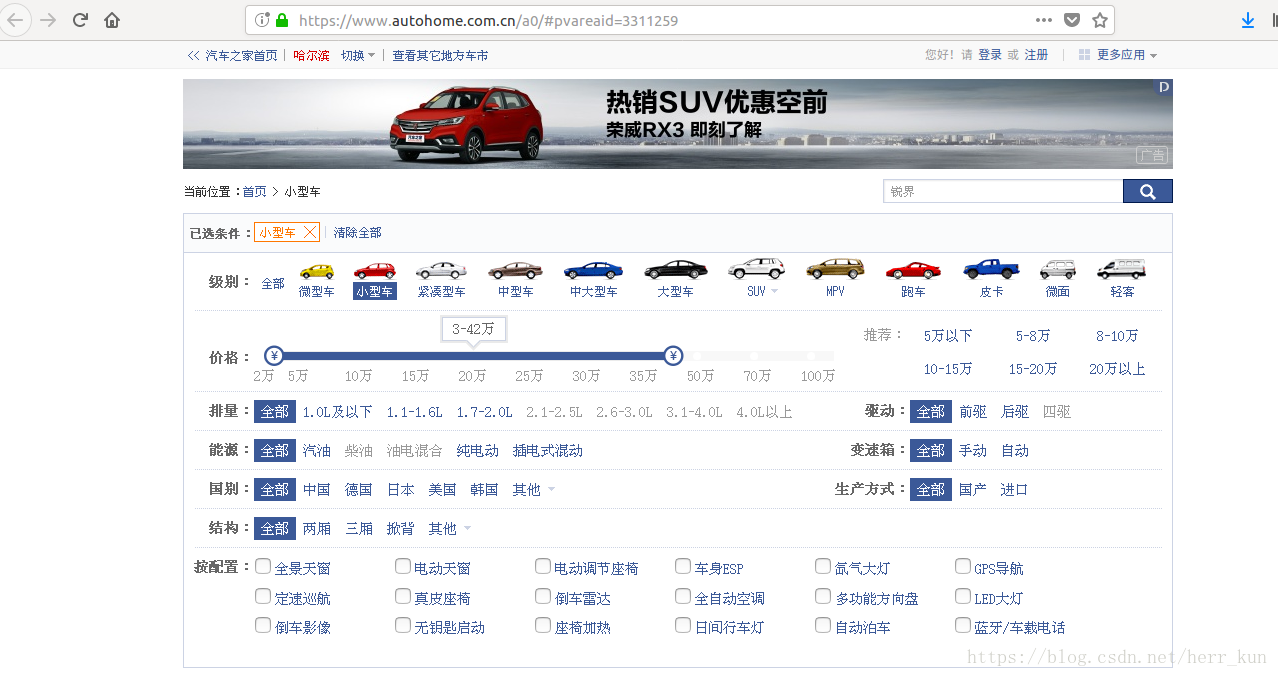
关闭小型车选项,得到全部车型,并且用F2 打开开发者选项
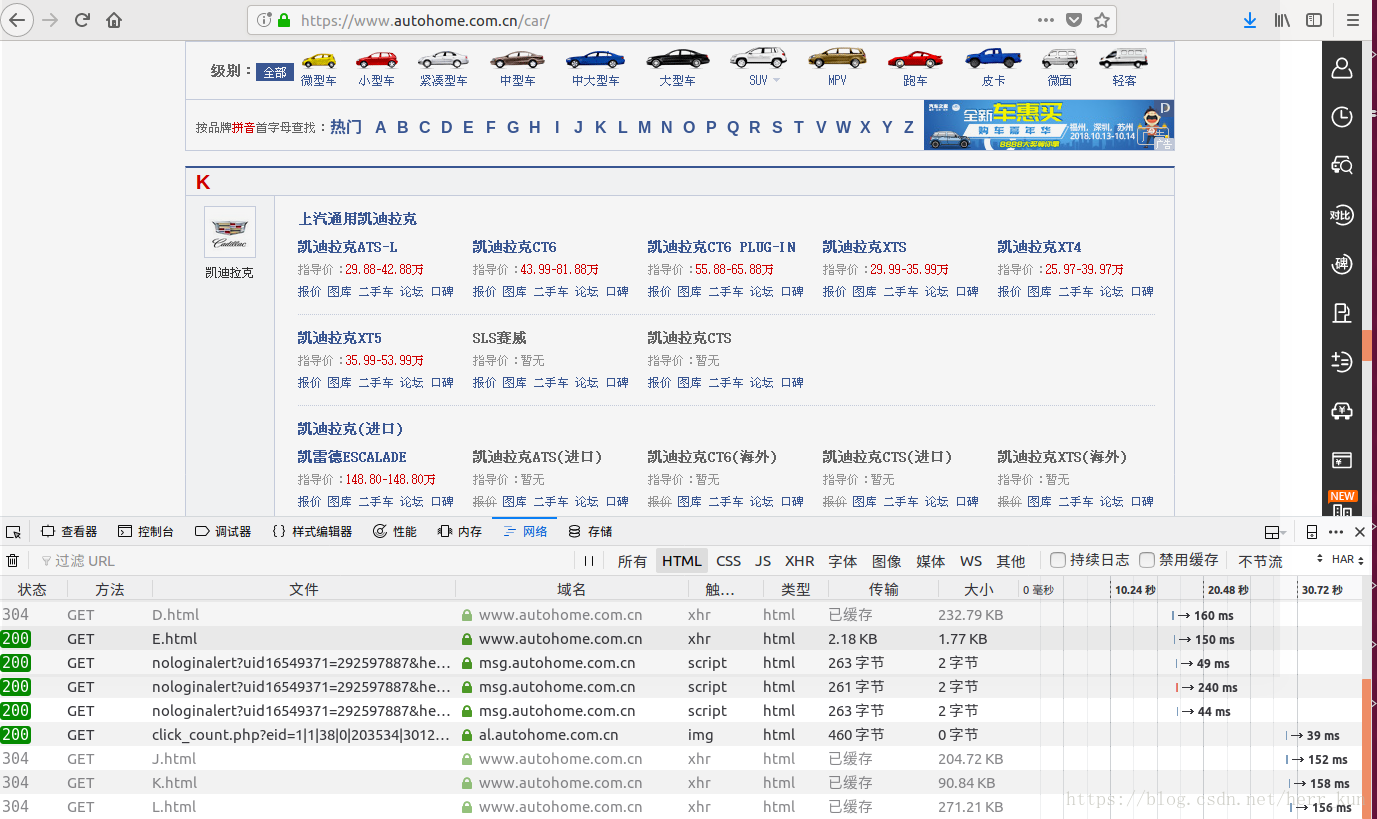
可以看到下面有几个html结尾的文件,那就是我们需要的,点击相应的网址,可以在其右侧得到我们需要的URL地址,根据这个地址便可以利用Python的包进行网页内容的爬取了
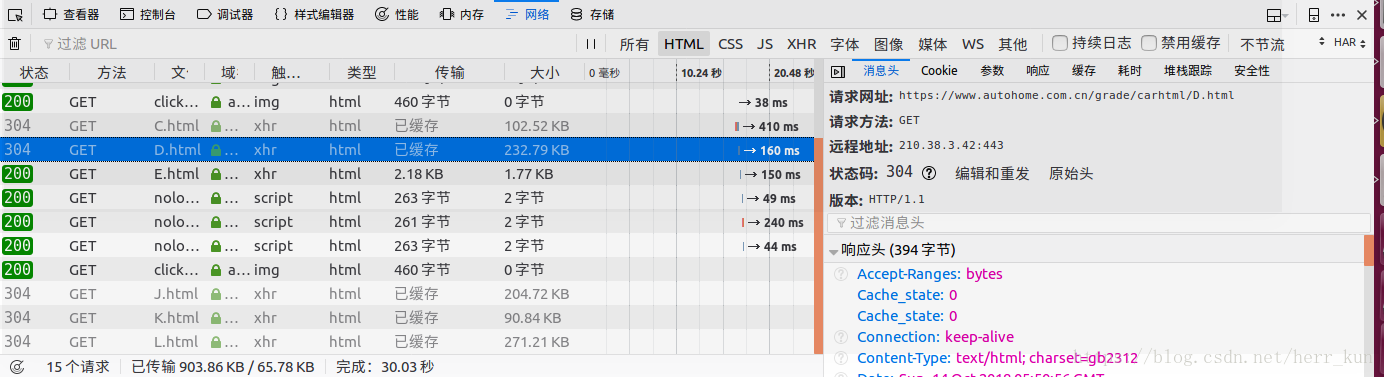
有了URL下面进行爬虫的编写:
import requests
import re
brand['A','B','C','D','F','G','H','J','K','L','M','N','O','P','Q','R','S','T','V','W','X','Y','Z']
url="https://www.autohome.com.cn/grade/carhtml/B.html" #以B brand为例
response=requests.get(zg[1])
response.encoding='gb2312'
html=response.text
打印上述得到的html会得到这样的信息:里面有很多以B开头的车型,奔驰,宝马,宝骏等等。。。
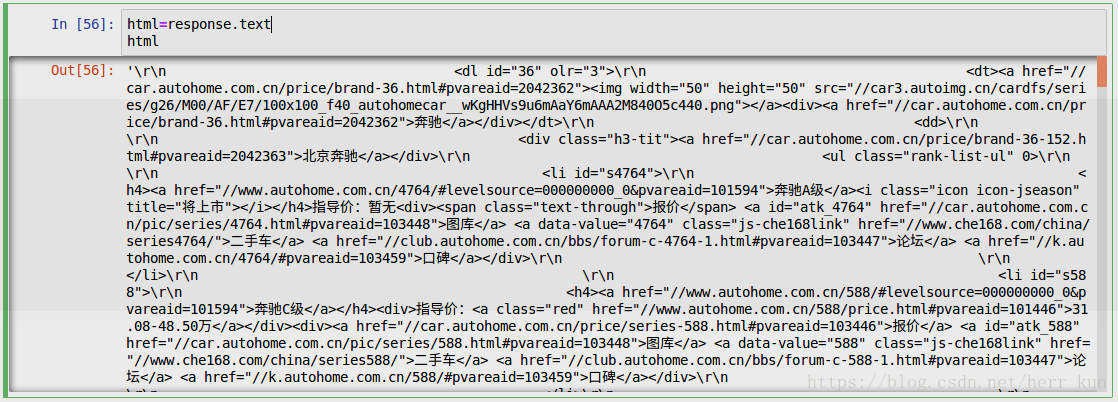
接下来还是通过查看网页车型图片的html地址,然后在上述的文件中进行提取:
img_url=re.findall(r'href="//car.autohome.com.cn/pic/series/(.*?).html#pvareaid=103448"', html) 结果:
接下来的工作就是讲提取到的信息和网址进行拼接以及读取解析操作,就不一一展开了。直接上代码
img_url_1 = 'https://car.autohome.com.cn/pic/series/' + img_url[1] + '-1.html#pvareaid=2042220' #其中-1是车身外观 10是内饰,自己去网页看源代码.......
response_1=requests.get(img_url_1)
html_2=response_1.text
img_url_2=re.findall(r'<a href="/photo/series/(.*?)"', html_2 )
img_url_3= list(map(lambda x:'https://car.autohome.com.cn/photo/series/'+x,img_url_2))
#img_url_3就是完整的html地址:eg:'https://car.autohome.com.cn/photo/series/36070/1
#/4506296.html'
for url in img_url_3:
response_2=requests.get(url)
response_2.encoding='gb2312'
html_2=response_2.text
img_url=re.findall(r'<img id="img" src="(.*?)"', html_2 )
img_url_2="https:"+img_url[0]
img_response=requests.get(img_url_2)
img_file_name_1=re.findall(r'<meta name="description" content="(.*?)"', html_2 )
b=img_file_name_1[0]
img_file_name=img_url_2.split('/')[-1]
img_file_name_2=b+img_file_name
f=open(img_file_name_2,'wb') #新建一个jpg图片文件
img_data=img_response.content
f.write(img_data) #讲二进制图片数据写入文件,可以在本地看到生成的图片至此为止,最后在本地查看保存成功的文件便可。
注:根据不同的需求,方法相同,爬取不同的数据。
转载自原文链接, 如需删除请联系管理员。
原文链接:汽车之家网站为例-爬虫的编写,爬取图片,转载请注明来源!