效果预览

完整代码
import requests
import csv
import time
import re
import math
import os
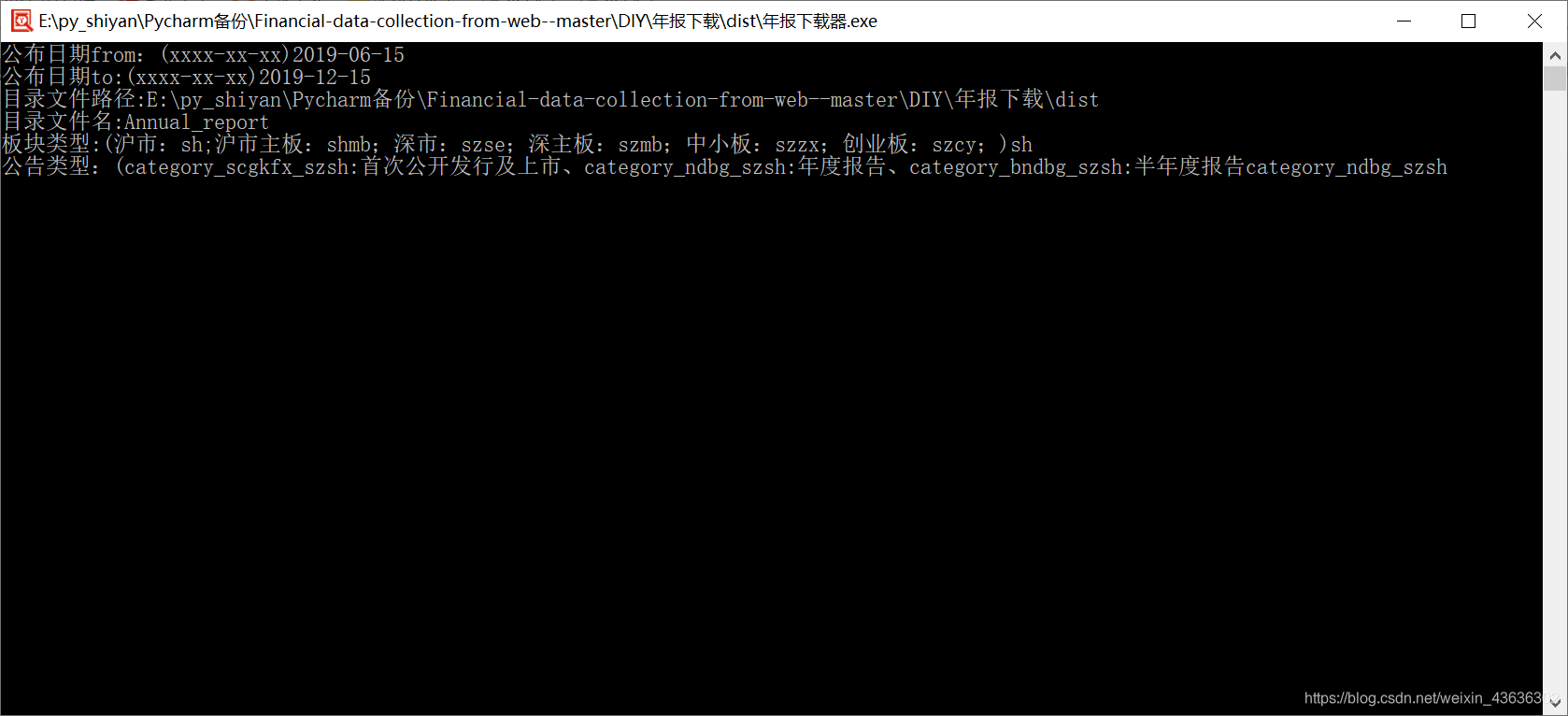
START_DATE =input('公布日期from:(xxxx-xx-xx)')
END_DATE=input('公布日期to:(xxxx-xx-xx)')
OUT_DIR =input('目录文件路径:')
OUTPUT_FILENAME = input('目录文件名:')
PLATE =input('板块类型:(沪市:sh;沪市主板:shmb;深市:szse;深主板:szmb;中小板:szzx;创业板:szcy;)')
# 板块类型——沪市:sh;沪市主板:shmb;深市:szse;深主板:szmb;中小板:szzx;创业板:szcy;
CATEGORY = input('公告类型:(category_scgkfx_szsh:首次公开发行及上市、category_ndbg_szsh:年度报告、category_bndbg_szsh:半年度报告')
# 公告类型:category_scgkfx_szsh(首次公开发行及上市)、category_ndbg_szsh(年度报告)、category_bndbg_szsh(半年度报告)
keyword=input('请输入关键字:')
URL = 'http://www.cninfo.com.cn/new/hisAnnouncement/query'
HEADER = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
MAX_PAGESIZE = 30
MAX_RELOAD_TIMES = 5
RESPONSE_TIMEOUT = 10
def standardize_dir(dir_str):
assert (os.path.exists(dir_str)), 'Such directory \"' + str(dir_str) + '\" does not exists!'
if dir_str[len(dir_str) - 1] != '/':
return dir_str + '/'
else:
return dir_str
def get_response(page_num, return_total_count=False):
query={'pageNum': page_num,
'pageSize': MAX_PAGESIZE,
'column': 'szse',
'tabName': 'fulltext',
'plate': PLATE,
'stock': '',
'searchkey': '',
'category': CATEGORY,
'seDate': START_DATE + '~' + END_DATE,
'sortName': '',
'sortType': '',
'showTitle': '',
'limit': '',
}
result_list = []
reloading = 0
while True:
try:
r = requests.post(URL, query, HEADER)
# print(r.text)
# print(len(r.text))
except Exception as e:
print(e)
continue
if r.status_code == requests.codes.ok and r.text != '':
break
my_query = r.json()
try:
r.close()
except Exception as e:
print(e)
if return_total_count:
return my_query['totalRecordNum']
else:
for each in my_query['announcements']:
file_link = 'http://static.cninfo.com.cn/' + str(each['adjunctUrl'])
file_name = __filter_illegal_filename(
str(each['secCode']) + str(each['secName']) + str(each['announcementTitle']) + '.' + '(' + str(
each['adjunctSize']) + 'k)' +
file_link[-file_link[::-1].find('.') - 1:] # 最后一项是获取文件类型后缀名
)
result_list.append([file_name,file_link])
return result_list
def __log_error(err_msg):
err_msg = str(err_msg)
print(err_msg)
with open(error_log, 'a', encoding='gb18030') as err_writer:
err_writer.write(err_msg + '\n')
def __filter_illegal_filename(filename):
illegal_char = {
' ': '',
'*': '',
'/': '-',
'\\': '-',
':': '-',
'?': '-',
'"': '',
'<': '',
'>': '',
'|': '',
'-': '-',
'—': '-',
'(': '(',
')': ')',
'A': 'A',
'B': 'B',
'H': 'H',
',': ',',
'。': '.',
':': '-',
'!': '_',
'?': '-',
'“': '"',
'”': '"',
'‘': '',
'’': ''
}
for item in illegal_char.items():
filename = filename.replace(item[0], item[1])
return filename
if __name__=='__main__':
out_dir = standardize_dir(OUT_DIR)
error_log = out_dir + 'error.log'
output_csv_file = out_dir + OUTPUT_FILENAME.replace('/', '') + '_' + \
START_DATE.replace('-', '') + '-' + END_DATE.replace('-', '') + '.csv'
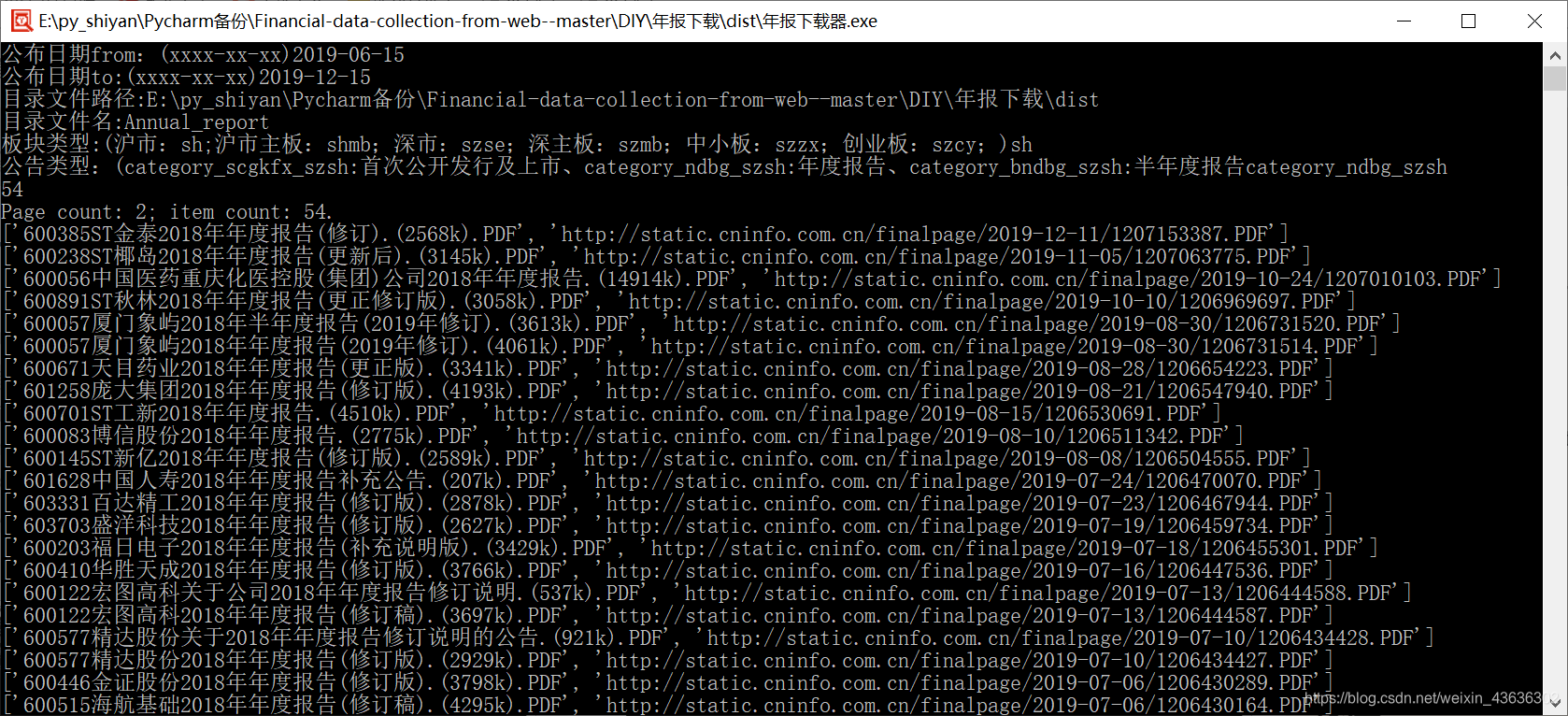
item_count = get_response(1, True)
assert (item_count != []), 'Please restart this script!'
print(item_count)
begin_pg = 1
end_pg = int(math.ceil(item_count / MAX_PAGESIZE))
print('Page count: ' + str(end_pg) + '; item count: ' + str(item_count) + '.')
time.sleep(2)
with open(output_csv_file, 'w', newline='', encoding='gb18030') as fa:
writer = csv.writer(fa)
for i in range(begin_pg, end_pg + 1):
#默认为false
row = get_response(i)
for r in row:
if re.search('摘要', r[0], re.S) or (not re.search(keyword, r[0], re.S)) or re.search('取消', r[0], re.S):
pass
else:
writer.writerow(r)
print(r)
with open(output_csv_file, mode='r', encoding='gbk', newline='') as f:
reader = csv.reader(f)
for row in reader:
filename = row[0]
link = row[1]
r = requests.get(link, stream=True)
with open(filename, 'wb') as fd:
for y in r.iter_content(102400):
fd.write(y)
以上方法的思路是先获取所有公司名称和链接保存到csv,然后再读取csv下载,也可以每获取一个链接保存一行下载一个年报,代码大同小异:
import requests
import csv
import time
import re
import math
import os
START_DATE =input('公布日期from:(xxxx-xx-xx)')
END_DATE=input('公布日期to:(xxxx-xx-xx)')
OUT_DIR =input('目录文件路径:')
OUTPUT_FILENAME = input('目录文件名:')
PLATE =input('板块类型:(沪市:sh;沪市主板:shmb;深市:szse;深主板:szmb;中小板:szzx;创业板:szcy;)')
# 板块类型——沪市:sh;沪市主板:shmb;深市:szse;深主板:szmb;中小板:szzx;创业板:szcy;
CATEGORY = input('公告类型:(category_scgkfx_szsh:首次公开发行及上市、category_ndbg_szsh:年度报告、category_bndbg_szsh:半年度报告')
# 公告类型:category_scgkfx_szsh(首次公开发行及上市)、category_ndbg_szsh(年度报告)、category_bndbg_szsh(半年度报告)
URL = 'http://www.cninfo.com.cn/new/hisAnnouncement/query'
HEADER = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
MAX_PAGESIZE = 30
MAX_RELOAD_TIMES = 5
RESPONSE_TIMEOUT = 10
def standardize_dir(dir_str):
assert (os.path.exists(dir_str)), 'Such directory \"' + str(dir_str) + '\" does not exists!'
if dir_str[len(dir_str) - 1] != '/':
return dir_str + '/'
else:
return dir_str
def get_response(page_num, return_total_count=False):
query={'pageNum': page_num,
'pageSize': MAX_PAGESIZE,
'column': 'szse',
'tabName': 'fulltext',
'plate': PLATE,
'stock': '',
'searchkey': '',
'category': CATEGORY,
'seDate': START_DATE + '~' + END_DATE,
'sortName': '',
'sortType': '',
'showTitle': '',
'limit': '',
}
result_list = []
reloading = 0
while True:
try:
r = requests.post(URL, query, HEADER)
# print(r.text)
# print(len(r.text))
except Exception as e:
print(e)
continue
if r.status_code == requests.codes.ok and r.text != '':
break
my_query = r.json()
try:
r.close()
except Exception as e:
print(e)
if return_total_count:
return my_query['totalRecordNum']
else:
for each in my_query['announcements']:
file_link = 'http://static.cninfo.com.cn/' + str(each['adjunctUrl'])
file_name = __filter_illegal_filename(
str(each['secCode']) + str(each['secName']) + str(each['announcementTitle']) + '.' + '(' + str(
each['adjunctSize']) + 'k)' +
file_link[-file_link[::-1].find('.') - 1:] # 最后一项是获取文件类型后缀名
)
result_list.append([file_name,file_link])
return result_list
def __log_error(err_msg):
err_msg = str(err_msg)
print(err_msg)
with open(error_log, 'a', encoding='gb18030') as err_writer:
err_writer.write(err_msg + '\n')
def __filter_illegal_filename(filename):
illegal_char = {
' ': '',
'*': '',
'/': '-',
'\\': '-',
':': '-',
'?': '-',
'"': '',
'<': '',
'>': '',
'|': '',
'-': '-',
'—': '-',
'(': '(',
')': ')',
'A': 'A',
'B': 'B',
'H': 'H',
',': ',',
'。': '.',
':': '-',
'!': '_',
'?': '-',
'“': '"',
'”': '"',
'‘': '',
'’': ''
}
for item in illegal_char.items():
filename = filename.replace(item[0], item[1])
return filename
if __name__=='__main__':
out_dir = standardize_dir(OUT_DIR)
error_log = out_dir + 'error.log'
output_csv_file = out_dir + OUTPUT_FILENAME.replace('/', '') + '_' + \
START_DATE.replace('-', '') + '-' + END_DATE.replace('-', '') + '.csv'
item_count = get_response(1, True)
assert (item_count != []), 'Please restart this script!'
print(item_count)
begin_pg = 1
end_pg = int(math.ceil(item_count / MAX_PAGESIZE))
print('筛选关键字前,共有 Page count: ' + str(end_pg) + '; item count: ' + str(item_count) + '.')
time.sleep(2)
# 设置关键字过滤筛选,比如要下2018年的,可以设置关键字为2018,如果想要下载多年的,可以将关键字的限制范围扩大,比如“年”
keyword = input('请输入关键字:')
with open(output_csv_file, 'w', newline='', encoding='gb18030') as fa:
writer = csv.writer(fa)
for i in range(begin_pg, end_pg + 1):
#默认为false
row = get_response(i)
for r in row:
if re.search('摘要', r[0], re.S) or (not re.search(keyword, r[0], re.S)) or re.search('取消', r[0], re.S):
pass
else:
writer.writerow(r)
print(r)
pdf = requests.get(r[1], stream=True)
with open(r[0], 'wb') as fd:
for y in pdf.iter_content(102400):
fd.write(y)
生成年报下载器
将代码打包,具体步骤见上一篇博客:
https://blog.csdn.net/weixin_43636302/article/details/103555585
转载自原文链接, 如需删除请联系管理员。
原文链接:Python批量下载上交所、深交所年报或半年报并生成年报下载器exe文件,转载请注明来源!