一、安装selenium
基于Window操作系统
1.selenium库的安装
(需要先安装python3,这里就不详细说明)
- 可在cmd上运行pip install selenium
- 也可在pycharm工程目录下添加selenium库
2.下载对应的浏览器驱动
各大浏览器webdriver地址可参见:https://docs.seleniumhq.org/download/
3.webdriver的安装路径
- (1)将下载解压后驱动文件放到python安装路径
(若不知安装路径,可用where python命令查询)

- (2)也可放到pycharm工程中的venv->Scripts中

(本人配置的是python3,
浏览器:火狐66.03(最新)
驱动:geckodriver-v0.24.0-win64.zip)
二、selenium的简单操作
天天基金网址: http://fund.eastmoney.com/
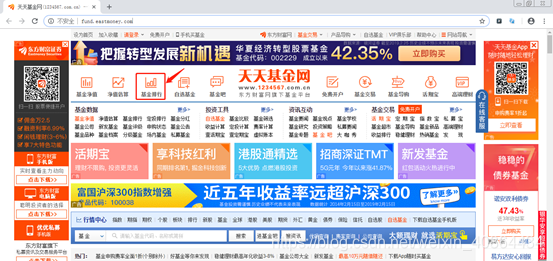
1. 基于firefox浏览器驱动打开天天基金网站;
待页面“基金排行”出现后,点击“基金排行”,进入排行页面。
from selenium import webdriver
d = webdriver.Firefox() #打开浏览器
d.get('http://fund.eastmoney.com/') #进入网页
# #点击基金排行
d.find_element_by_xpath("//li[@class='ph']/a").click() #通过xpath元素定位
# click()方法模仿人工点击
为什么xpath是 “//li[@class=‘ph’]/a”
让我们来分析一下
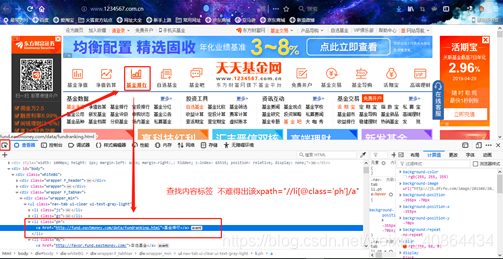
关于xpath的学习可参考 (转)python+selenium基础之XPATH定位(第一篇)
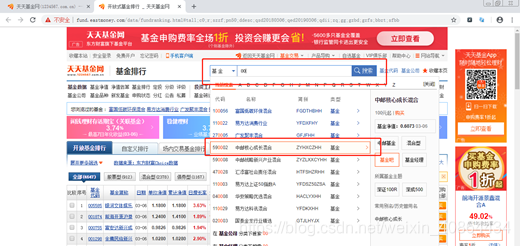
2. 进入排行页面后,在基金搜索框输入:00,并在弹出的下拉框中选择第四条基金,点击进入基金详情页面。
d.switch_to.window(d.window_handles[1]) #切换句柄到当前页面
d.find_element_by_xpath("//input[@id='search-input']").clear()
d.find_element_by_xpath("//input[@id='search-input']").send_keys("00") #send_keys("00")模仿人工输入
# d.refresh() #刷新页面
time.sleep(3)
#click()点击下拉菜单第四条信息
d.find_element_by_xpath("//tr[@data-submenu='590008']/td[@class='seaCol2']").click()
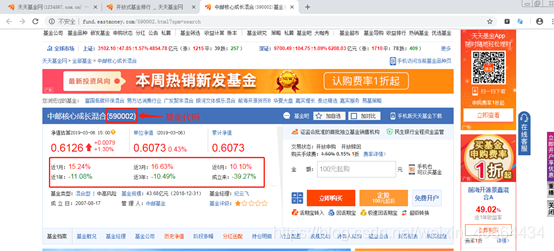
3.获取基金详情页面红框内容,并存入mysql数据库
d.switch_to.window(d.window_handles[2])
#获取网页内容,并
bs = BeautifulSoup(d.page_source,'html.parser')
# 创建一个列表,将数据存储进去
InfoList = []
#获取基金代码
code = bs.find("span",{"class":"ui-num"}).text
# 获取基本基金信息
div = bs.find('div',{'class':'fundInfoItem'})
InfoList.append(code) # 将基金代码添加到列表中
dls = div.find_all('dl')
for dl in dls:
dds = dl.find_all('dd')
for i,dd in enumerate(dds):
# print(dd)
"""
dd 的内容如下:
dd[0] <dd class="dataNums"><dl class="floatleft">...... id="gz_gszzl">+0.15%</span></dl></dd>
dd[1] <dd><span>近1月:</span><span class="ui-font-middle ui-color-green ui-num">-4.45%</span></dd>
dd[2] <dd><span>近1年:</span><span class="ui-font-middle ui-color-green ui-num">-4.76%</span></dd>
因为只有二、三才是我们所需的数据
"""
if i == 1:
span = dd.find_all('span')[1].string
InfoList.append(span)
if i == 2:
span = dd.find_all('span')[1].string
InfoList.append(span)
conn = pymysql.connect(host = 'localhost',user = 'root',password = '123456',port = 3306,db = 'mystudy',charset = 'utf8') # 数据库的连接
cursor = conn.cursor() # 创建游标
tablename = 'seleniumGetNews'
#数据存储操作
try:
insertSql = "insert into {} values (%s,%s,%s,%s,%s,%s,%s)".format(tablename) #mysql语句
cursor.execute(insertSql,InfoList)
except pymysql.err.ProgrammingError:
#如果表不存在则创建。
createSql = "create table {}(" \
"基金代码 varchar(100) primary key ," \
"近一月 varchar(100)," \
"近一年 varchar(100)," \
"近三月 varchar(100)," \
"近三年 varchar(100)," \
"近六月 varchar(100)," \
"成立来 varchar(100))" \
"ENGINE = InnoDB DEFAULT CHARSET =utf8;".format(tablename)
cursor.execute(createSql)
cursor.execute(insertSql,InfoList)
conn.commit() #提交命令
cursor.close() #关闭游标
conn.close() #关闭连接
4.将页面切换回首页(句柄切换)
d.switch_to.window(d.window_handles[0]) #关于页面句柄,在第三点的问题有提及
d.refresh() #刷新页面
三、遇到的问题
1. 从主窗口A跳转至主窗口B后,无法定位窗口B的元素的问题
原因:当启动脚本后,从页面A打开页面B后,窗口句柄(焦点)依旧停留在主页面A,所以无法定位页面B的元素,报错无当前元素,当跳转页面时。
当我们打印句柄,输出的是列表,其中各代表各自的页面。
解决方法:将窗口句柄(焦点)切换到当前页面
d.switch_to.window(d.window_handles[1])
转载自原文链接, 如需删除请联系管理员。
原文链接:【小白】利用selenium+python爬取天天基金网--模拟人工查询基金信息,转载请注明来源!