『写在前面』
目标检测新思路,检测目标极值点而不是回归包围框。
作者机构:Xingyi Zhou等,UT Austin
文章标题:《Bottom-up Object Detection by Grouping Extreme and Center Points》
摘要
提出一种目标检测的新思路:首先通过标准的关键点估计网络来检测4个极值点和1个中心点,然后通过几何关系对提取到的关键点进行分组,一组极值点(5个)就对应一个检测结果。
使得目标检查问题转化成了一个纯粹的基于外观信息的关键点估计问题,从而巧妙地避开了区域分类和隐含特征学习。
与现有的目标检测模型相比,首先极值点比包围框更能反映物体信息,其次作者还提出了使用一个简单的trick就能得到一个更加细致的八边形的分割估计结果,最后如果还不满意还能结合DeepExtremeCut使用,将极值点转化为分割mask,最终的效果甚至可以和Mask R-CNN媲美。
1 介绍
传统目标检测算法的局限性:
- 因为形状问题(指矩形框),通常预测结果中包含了太多的无用干扰;
- 枚举了大量不理解目标具体视觉信息的框;
- 因为包围框本身就不能很好地代表物体本身,所以只能提很有限的信息(形状、姿势等)。
ExtremeNet的大致思路是:使用关键点检测算法,对每个类别预测4张极值点heatmap和1张中心点heatmap,然后通过暴力枚举(复杂度 )找到有效的点组。
)找到有效的点组。
CornerNet是第一个将关键点检测用在目标检测任务上的模型。ExtremeNet与CornerNet有两处不同:
- 如何定义关键点:corner point通常落在物体外部,往往没有强烈的局部特征。而extreme point一半就在物体边界上,视觉上比较好辨认;
- 关键点分组:ExtremeNet纯粹依赖几何关系进行极值点的分组,没有隐含的特征学习,效果更好。
2 相关工作
Two-stage方面
- 作者首先肯定了RCNN类方法取得的成绩,但也提出了自己的观点,即认为对于目标检测任务而言,Region不见得是必须存在的。
One-stage方面
- ExtremeNet也属于One-stage类目标检测模型
- YOLO、SSD等在空间中设置anchor。
- ExtremeNet在空间中检测5个独立的部件,具体而言,在每个heatmap中只预测某位置是一个极值点的概率。对于用来预测center的heatmap而言,可以将其理解为一个用来预测尺度宽高未知的RPN。
3 算法初步
Extreme and center points
传统标注使用矩形框标注目标,而矩形框一般会用左上角和右下角两个点表示。
而在ExtremeNet中,使用四点标注法,即一个目标用上下左右四个方向上的极值点来表示。额外的,通过这四个点可以计算出该目标的中心坐标。
Keypoint detection
使用fully convolutional encoder-decoder network预测一个多通道heatmap,每个通道都对应一个类别的关键点。
使用HourglassNetwork作为backbone,对每张heatmap进行加权逐点逻辑回归,加权的目的是为了减少ground truth周围的虚警惩罚。
CornerNet
CornerNet基于HourglassNetwork进行关键点检测,去预测两组相对点的heatmap,最后通过联合嵌入(associative embedding)对点集进行分组,进而实现目标检测。ExtremeNet沿用了CornerNet的网络结构和损失函数,但没有使用联合嵌入。
为了平衡正负样本,在训练中使用了改进版的focal loss:
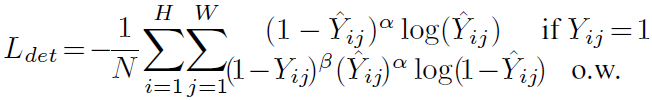
为了提高Corner point检测的准确性,CornerNet还添加了一个与类别无关的offset map,用来弥补在下采样过程中引起的分辨率损失。Offset map训练过程中使用了平滑L1 loss:
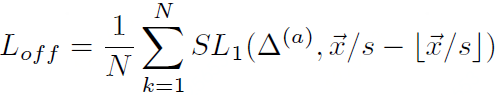
Deep Extreme Cut
入选CVPR 2018的大作,给定一副图像,和若干个极值点,即可得到一个类别未知分割mask。如果需要得到更加精细的分割效果的话,正好可以接在ExtremeNet的输出之后,便可以轻松得到分割结果。
论文信息:https://arxiv.org/abs/1711.09081
官方网站:http://www.vision.ee.ethz.ch/~cvlsegmentation/dextr/index.html
4 ExtremeNet细节
ExtremeNet的输出通道数为: 。对每个类别,预测4张极值点heatmap和1张center map所以是5张。然后,对每种极值点heatmap,再预测2张offset map(分别对应XY轴方向),注意是所有类别公用的且center map没有,所以只有4x2张。
整体效果如下图所示:

4.1 中心点分组
大体分为两个步骤:
第一步,ExtrectPeak。 即提取heatmap中所有的极值点,极值点定义为在3x3滑动窗口中的极大值。
第二步,暴力枚举。对于每一种极值点组合(进行适当的剪枝以减小遍历规模),计算它们的中心点,如果center map对应位置上的响应超过预设阈值,则将这一组5个点作为一个备选,该备选组合的score为5个对应点的score平均值。
直观展示:
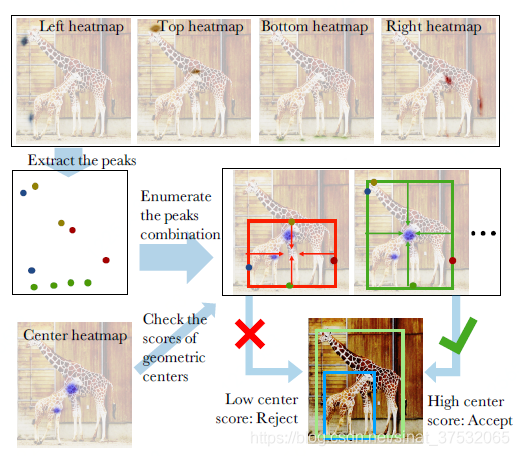
具体的算法说明:

4.2 Ghost box抑制
何为ghost box?如下图所示,若存在多个并排排列且大小相近的物体,则对obj_2这个目标来说,在指定center时,会有两个选择,一个是真实的目标,另一个是大一圈的ghost box。
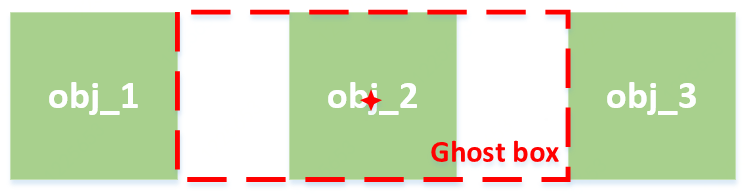
使用soft NMS来抑制Ghost box:如果某个包围框,其内部所有的包围框的score综合超过了其本身score的3倍,则将其本身的score修正为原来的1/2。
4.3 边缘融合
极值点的定义并不唯一,这就导致如果物体沿着水平或垂直方向边缘形成极值点的话(比如汽车顶部),沿着该边缘的点可能都会被当做极值点。网络会对沿对象任何对齐的边缘产生弱响应,而不是单个的强响应。这会引起两个问题:一方面,较弱的响应可能低于预设的极值点阈值,导致漏掉所有的点;另一方面,即使侥幸超过了阈值,但其score可能还是PK不过轻微旋转过的目标相比(在两个方向上都有较大的响应)。
![]()
解决办法是,对每一个极值点,向它的两个方向进行聚集。具体做法是,沿着X/Y轴方向,将第一个单调下降区间内的点的score按一定权重累加到原极值点上。效果如下图所示,可以看出,红圈部分的响应明显增强了。

4.4 基于ExtremeNet的实例分割
八边形掩模估计
基于ExtremeNet检测到的4个极值点,通过在每两个极值点之间插入中间点,来补成八边形掩模。具体做法是:首先根据4个极值点找到外接矩形;然后对每个极值点,在其所属的矩形边上,沿着两个方向各延长矩形边的1/8;最后将8个点连接起来,如果遇到了矩形边界则截断,得到最后的八边形分割掩模估计结果。
精细分割 by DeepExtremeCut
上文中第3章部分有简单介绍。给定一副图像和若干个极值点,即可得到一个类别未知分割mask。

5 实验部分
只记录了几个点:
极值点标注
从COCO mask中得到极值点标注的方式:如果一条边平行于轴或角度小于3°,则将该边的中点标注为一个极值点。
训练细节
从头训练CornerNet部分需要140 GPU days,不太现实。。所以作者是finetune的。
测试细节
ExtrectPeak步骤中,取Top40的点来进行后续的枚举,以确保效率。
作者的耗时测试结果:3.1FPS,单帧耗时约322ms。其中,模型前向运算13ms,点分组150ms,后处理(soft NMS)约160ms。可以看出,绝大部分时间都花在了解析网络输出上,
转载自原文链接, 如需删除请联系管理员。
原文链接:论文学习笔记ExtremeNet(Bottom-up Object Detection by Grouping Extreme and Center Points),转载请注明来源!