我们在在分类任务时,经常会对模型结果进行评估。评估模型好坏的指标有AUC、KS值等等。这些指标是通过预测概率进行计算的。而准确率、精准率和召回率也通过混淆矩阵计算出来的。下图是对混淆矩阵的介绍:

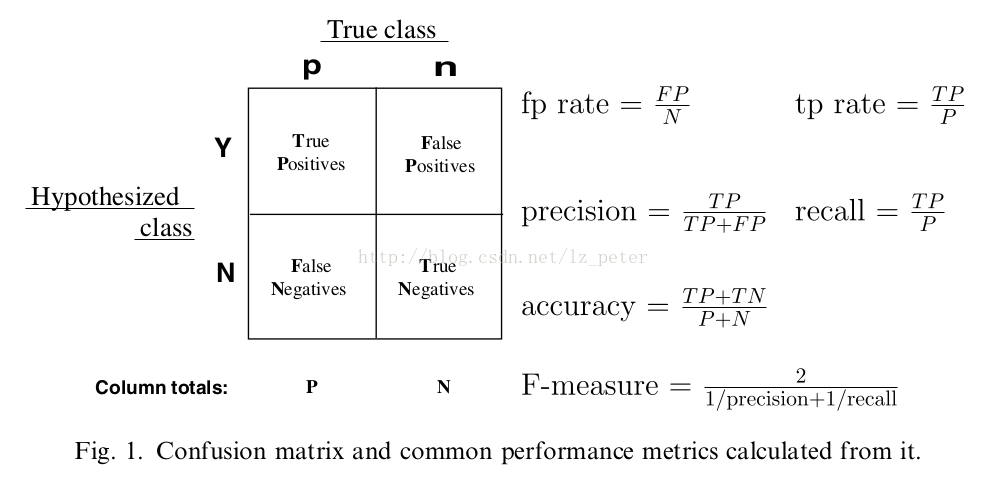
其中,
TP:样本为正,预测结果为正;
FP:样本为负,预测结果为正;
TN:样本为负,预测结果为负;
FN:样本为正,预测结果为负。
准确率、精准率和召回率的计算公式如下:
准确率(accuracy): (TP + TN )/( TP + FP + TN + FN)
精准率(precision):TP / (TP + FP),正确预测为正占全部预测为正的比例
召回率(recall): TP / (TP + FN),正确预测为正占全部正样本的比例
F-measure:precision和recall调和均值的2倍。
观察上面的公式我们发现,精准率(precision)和召回率(recall)的分子都是预测正确的正类个数(即TP),区别在于分母。精准率的分母为预测为正的样本数,召回率的分母为原来样本中所有的正样本数。那么精准率和召回率的区别是什么呢,下图是在不同阈值下统计出来的精准率和召回率。通过下图我们发现精准率和召回率并不一定是正相关(但也不一定是负相关)。
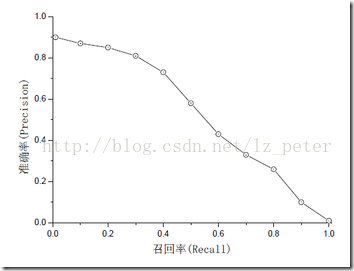
我们当然希望精准率和召回率都高,但是现实情况一般不是这样。这时我们可以通过F-measure来评估,F-measure是精准率和召回率的调和平均数的2倍。调和平均数的意义,是为了衡量A在空间B,C的总体平均分布程度(假设B,C不重叠)。F-measure应该是精准率和召回率之间的一个平衡点。如果多个模型结果进行对比的话,可能更加公平一些(个人理解)。
突发奇想,如果模型预测的结果全部为负类的话,那么精准率、召回率和F-measure这些指标就全为零。就无法通过这些指标评价模型的好坏。当然这种情况比较极端,我想应该不会在现实中出现吧。哈哈哈哈。。。。
参考文献:
https://www.zhihu.com/question/23096098?sort=created
http://www.cnblogs.com/sddai/p/5696870.html
http://blog.csdn.net/appleml/article/details/40476295
转载自原文链接, 如需删除请联系管理员。
原文链接:准确率、精准率和召回率的理解,转载请注明来源!