文章目录
1. 采集网站:百度贴吧
采集内容:图片
比如:下图中的校花吧的图片
:
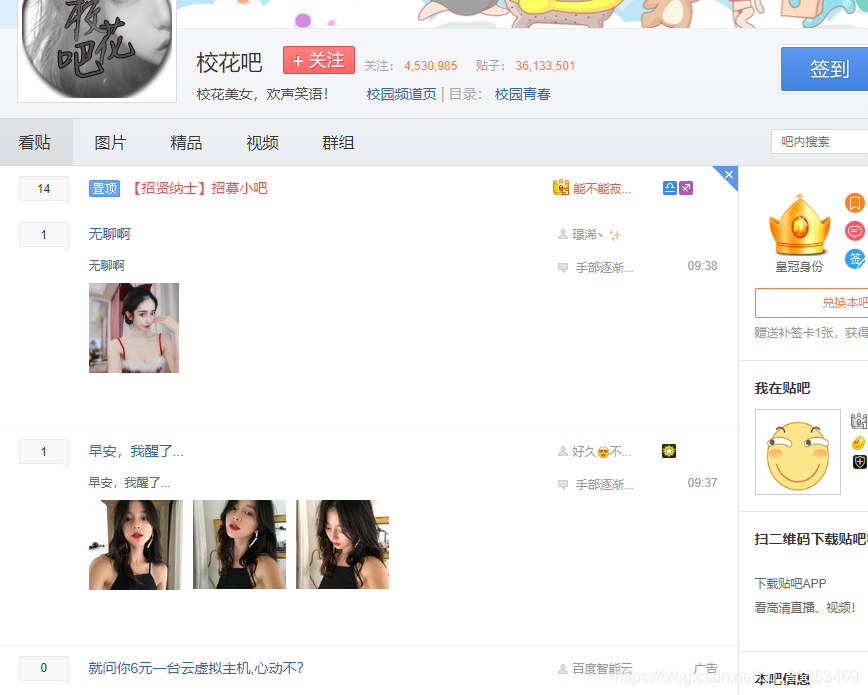
2.采集效果:
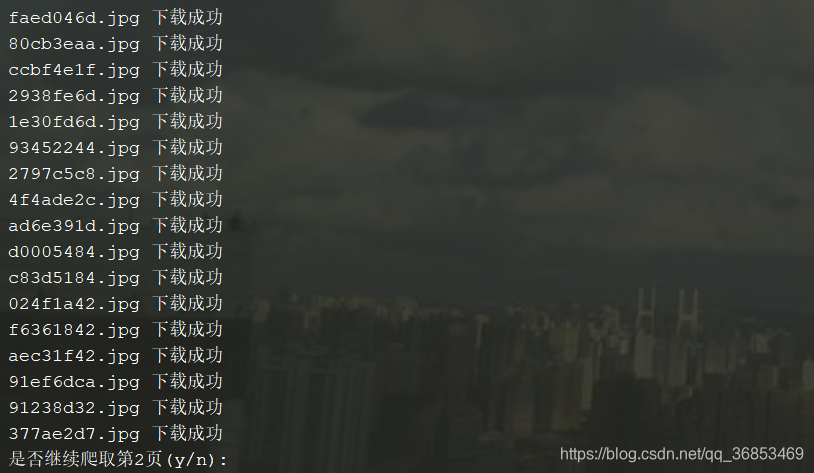

3.代码及思路:
3.1 每个贴吧对应的链接:

构造路由
self.url = "https://tieba.baidu.com/f?kw="
kw = input("请输入要爬取的贴吧:")
urlTieBa = self.url + kw3.2 贴吧翻页规则:
第一页,第二页,第三页:
![]()

![]()
翻页总结:从0开始,没50个铁(帖)子为一页,
构造翻页路由:
for i in range(1, 1000): #爬取1000页
urlTieBa = urlTieBa + "&ie=utf-8&pn=" + str((i - 1) * 50)3.3 xpath抓取每个帖子的链接:

最后每个帖子的链接:

所以,帖子链接拼接:
urlTieZiList = parseHtml.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a[@rel="noreferrer"]/@href')
for i in urlTieZiList:
j = 1
urlTieZi = 'http://tieba.baidu.com'
urlTieZi += i 3.4 每个图片的链接:
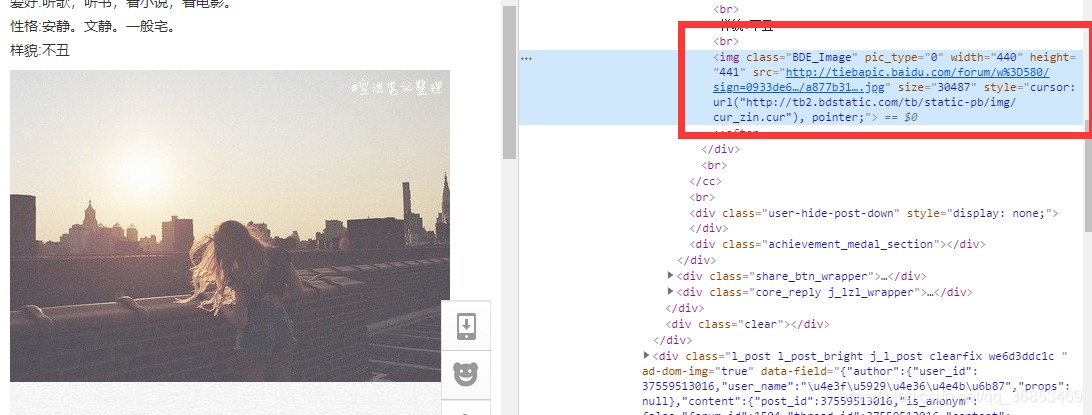
也是可以直接xpath 定位的:
imageurl = parseHtml.xpath('//div[@class = "d_post_content j_d_post_content clearfix"]/img[@class="BDE_Image"]/@src')3.5 下载图片:
for ima in imageurl:
response = requests.get(ima, headers=self.headers)
filename = ima[-12:]
response.encoding = "utf-8"
image = response.content
j += 1
with open("./images/校花/"+filename, "wb")as f:
f.write(image)
print("%s" % filename, "下载成功")
4.总体代码:
# -*- coding: UTF-8 -*-
'''
@Author :Jason
爬取输入的指定贴吧
注意在该目录下创建images\指定贴吧 的 文件夹
'''
import requests
from lxml import etree
class getTiebaPic():
def __init__(self):
self.url = "https://tieba.baidu.com/f?kw="
self.headers = {"User-Agent": "User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)"}
#获取贴吧每一页中的帖子的链接
def get_urlTieBa(self):
kw = input("请输入要爬取的贴吧:")
page = int(input("请输入要爬取的页数:"))
urlTieBa = self.url + kw
for i in range(1,page): #爬取1000页
urlTieBa = urlTieBa + "&ie=utf-8&pn=" + str((i - 1) * 50)
print(urlTieBa)
response = requests.get(urlTieBa, headers=self.headers)
response.encoding = "utf-8"
html = response.text
urlTieZiList = self.get_urlTieZi(html)
self.get_imageUrl(urlTieZiList)
def get_urlTieZi(self, html):
parseHtml = etree.HTML(html)
urlTieZiList = parseHtml.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a[@rel="noreferrer"]/@href')
return urlTieZiList
def get_imageUrl(self, urlTieZiList):
for i in urlTieZiList:
j = 1
urlTieZi = 'http://tieba.baidu.com'
urlTieZi += i
response = requests.get(urlTieZi, headers=self.headers)
response.encoding = "utf-8"
html = response.text
parseHtml = etree.HTML(html)
imageurl = parseHtml.xpath('//div[@class = "d_post_content j_d_post_content clearfix"]/img[@class="BDE_Image"]/@src')
for ima in imageurl:
response = requests.get(ima, headers=self.headers)
filename = ima[-12:]
response.encoding = "utf-8"
image = response.content
j += 1
with open("./images/校花/"+filename, "wb")as f:
f.write(image)
print("%s" % filename, "下载成功")
def main(self):
self.get_urlTieBa()
if __name__ == "__main__":
html = getTiebaPic()
html.main()
print("爬取结束")
转载自原文链接, 如需删除请联系管理员。
原文链接:Python爬虫福利第一弹---爬取校花校草吧图片,转载请注明来源!