Python 爬取电影街美剧网址
1 前期分析
电影街网站的下载模式基本为两级菜单,首先搜索美剧《危机边缘》,找到第四季的网址
https://moviejie.net/movie/caf13d/
打开共有三个版本的下载地址,在这里选取人人影视版,查看网页源代码可以发现,此版正好是下载网址的前二十二个(一共二十二集),网页源代码如下:
<tr data-episode="01">
<td class="movie_name"><span class="restitle">迷离档案.Fringe.S04E01.Chi_Eng.Webrip.AC3.1024X576.x264-YYeTs人人影视V2.mkv</span></td>
<td>493M</td>
<td>576p</td>
<td>mkv</td>
<td class="link">
<a href="/link/AwH1AmRlAv50qQR5AQVlBGxhZwNhZGR2Zmp3/">链接</a>
</td>
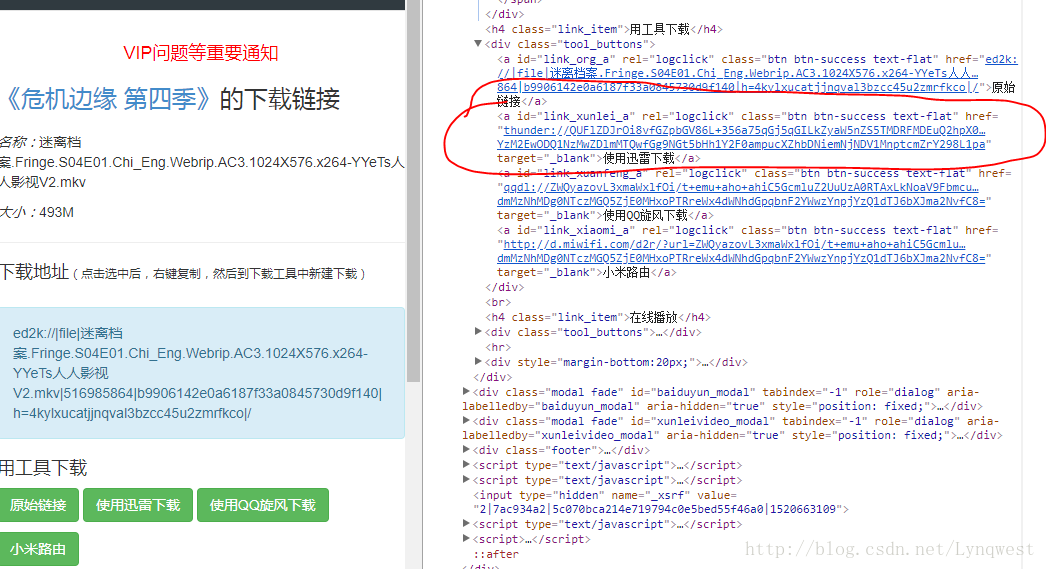
</tr>a打开该集的链接,才会出现这一集的下载地址,我们要做的是找到最终的迅雷下载地址,并将其写到一个txt文件当中,最终统一粘贴到迅雷里下载

2 Python包
这里我一共写了两个python文件,首先第一个是爬取所有分集的地址,写到一个文件中,第二个文件是打开刚才写入的文件,一个网址一个网址的找到最终的迅雷下载地址,写入到txt中。
在第一个文件中,由于网页源码比较简单,引入了正则表达式,来爬取所有的网址。
import re
import requests
import urllib 第二个文件,由于我们要找的迅雷下载地址在网页源码中没有,而从审查元素中可以找到,所以采用的selenium,模拟浏览器。
Selenium也是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE、Mozilla Firefox、Mozilla Suite等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。具体的selenium还有待学习,这里只是介绍一种webdriver的用法,用来驱动浏览器。
import re
import requests
from bs4 import BeautifulSoup
from selenium import webdriver3 程序编写
(1)爬取所有分集的跳转网址,并写入文件 '危机边缘第四季下载地址'
import re
import requests
import urllib
#提取分集EP中的模式
basic_html = 'https://moviejie.net/movie/caf13d/' #第四季合集网址
pattern = re.compile('<a href="(.*)">链接</a>') #正则式模式匹配
num = 0
#找到所有字幕组的视频的集合
r = requests.get(basic_html).text
series = re.findall(pattern,r) #所有匹配到的网址形成一个列表series
with open('电影街危机边缘分集网址','a') as f:
while num <22: #提取人人字幕组的前22集
html=[] #将人人字幕组分集的网址添加到 html列表中
html.append('https://moviejie.net'+series[num]) #完整网址的组合
print((html))
for i in html:
f.write(i)
num += 1 #下一集
(2)通过文件1,找到最终的迅雷下载网址,并写入文件 '电影街危机边缘分集网址'
import re
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
#用webdriver驱动Chrome浏览器
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
list=[]
download_html = open ('危机边缘第四季下载地址', 'a')
with open('电影街危机边缘分集网址','r') as f:
for i in f:
print(i)
driver.get(i) #连接到分集网址下载页
sourcePage = driver.page_source #找到网页的源代码
soup = BeautifulSoup(sourcePage, "lxml") #构建BeautifulSoup对象,
html = soup.find_all('a',id="link_xunlei_a") #审查元素,找到迅雷下载的网址段的标签
for j in html:
list.append(j.get('href')) #get()方法提取迅雷下载的网址
for i in list:
download_html.write(i)
download_html.write('\n')
download_html.close()
f.close()(3)复制最终的下载地址,打开迅雷即可
4 常见问题
(1) 在查找标签时,如果出现不存在的属性需要用 if !=\n 或其他语句首先判断
(2)webdriver的使用:首先要下载浏览器(这里是chrome)的对应版本的driver驱动,放在浏览器.exe相同的目录下,并在调用webdriver函数时写入绝对地址,否则会报错,无法启动Chrome浏览器
(3)以上两个文件,完全可以合起来写成一个,并且存在多个语句值得修改的地方,因此可能效率不高——懒得写了
转载自原文链接, 如需删除请联系管理员。
原文链接:Python 爬取电影街美剧网址,转载请注明来源!