1. 环境
centos 7
jdk 1.8
scala 2.10.6
hadoop 2.6.5
spark 1.6.3
2. 功能
1 乃木坂之诗-全集下载
2 星心传说-全集下载
3 灵道-全集下载
4 楚门-全集下载
5 火影忍者之七夜传说-全集下载
6 异世之混元大道-全集下载
7 一个俏妈三个爸-全集下载
8 震惊玄学圈的吉祥物-全集下载
9 快乐的变身生活-全集下载
10 万年古尸-全集下载
11 异界超级扮演-全集下载
12 冷颜笑-全集下载
13 我的老婆是买的-全集下载
14 《饕餮》--最真实的商场高端博弈小说-全集下载
15 玩转无限恐怖-全集下载
16 《你不知道的那些事儿》-全集下载
17 傻小子成帝记-全集下载
18 我不是血裔-全集下载
19 打造女尊国-全集下载
20 穿越之王妃有孕-全集下载
21 重组DNA-全集下载
22 赵匡胤传奇-全集下载
23 我上司的野蛮未婚妻-全集下载
24 网游之神话-全集下载
25 灰姑娘的樱桃之恋-全集下载
26 今晚让你爱上我-全集下载
27 穿越之调皮小王妃-全集下载
28 异世之火德星君-全集下载
29 艳医修行录-全集下载
30 蛇仙下凡旅游记-全集下载
31 雷电法师Ⅱ-全集下载
从 HDFS 中读取文本,统计出现过“火影”的行数。
3. 上传文件到HDFS
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoopVersion>2.6.5</hadoopVersion>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoopVersion}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoopVersion}</version>
</dependency>
</dependencies>
package peerslee.Hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
/*
1. No FileSystem for scheme: hdfs
解决:导入 hadoop-hdfs
*/
public class FileUtil {
private FileSystem fs;
private String default_fs;
FileUtil(String username, String default_fs) {
this.default_fs = default_fs;
Configuration conf = new Configuration();
conf.set("fs.defaultFS", default_fs);
try {
this.fs = FileSystem.get(new URI(default_fs),conf, username);
} catch (Exception e) {
e.printStackTrace();
System.out.println("Constructor Error");
}
}
public boolean upload(String src, String dest) {
try {
this.fs.copyFromLocalFile(new Path(src),
new Path(dest));
} catch (IOException e) {
e.printStackTrace();
System.out.println("Method upload Error");
return false;
}
return true;
}
}
package peerslee.Hdfs;
public class Test {
public static void main(String []args) {
String default_fs = "hdfs://192.168.1.10:8020/";
FileUtil fu = new FileUtil("lpl", default_fs);
if (fu.upload("F:\\hdfsdata\\novellist.dat","/test/folder/novellist.dat"))
System.out.println("ok...");
else
System.out.println("fail...");
}
}
4. Spark
name := "SparkPractice"
version := "0.1"
scalaVersion := "2.10.6"
// https://mvnrepository.com/artifact/org.apache.spark/spark-core_2.10
libraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.6.3"
import org.apache.spark.{SparkConf, SparkContext}
object SparkDemoI {
def main(args: Array[String]): Unit = {
// 1. 创建 RDD
/*
SparkContext 从内存中的集合或者外部文件系统读取数据转化为RDD
*/
val conf = new SparkConf()
val sc = new SparkContext(conf)
val novel_list = sc.textFile(args(0))
// 2. 转换 RDD
/*
将 RDD1通过转换操作(eg. filter)转换成RDD2
*/
val novel_rdd = novel_list.filter(_.contains(args(1)))
// 3. 持久化
/*
将 RDD 保存在磁盘或者内存,便于重复使用
*/
novel_rdd.cache()
// 4. 结果
/*
行动操作:惰性操作(任何action 都会触发作业执行)
将RDD 变成 Scala 集合、标量 或者 保存到外部文件(HDFS)、数据库(HBase)中
*/
println(novel_rdd.count())
sc.stop()
}
}
5.
打包

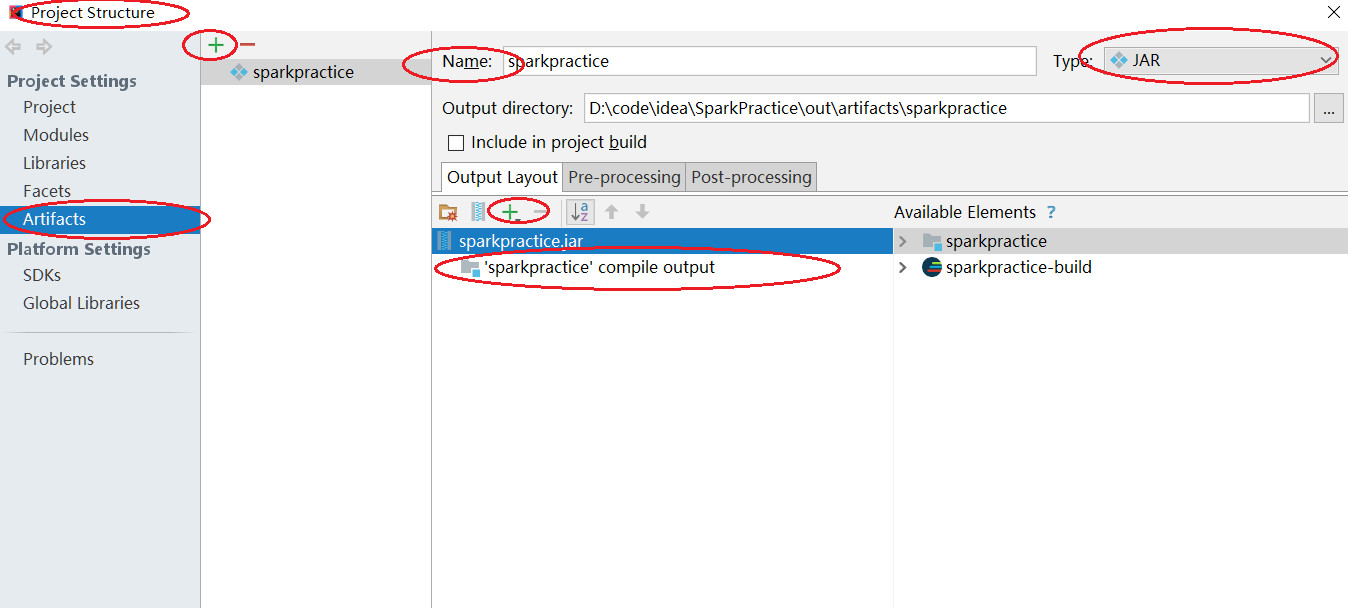

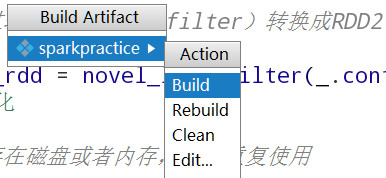

6. Linux Shell
#!/bin/bash
set -x
spark-submit \
--name sparkpractice \
--class SparkDemoI \
--master spark://master:7077 \
--executor-memory 1G \
--total-executor-cores 1 \
~/jar/sparkpractice.jar \
hdfs://master:8020/test/folder/novellist.dat "火影"

7. spark-submit
spark-submit --help
Usage: spark-submit [options] <app jar | python file> [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of local jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor.
--conf PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
--help, -h Show this help message and exit
--verbose, -v Print additional debug output
--version, Print the version of current Spark
Spark standalone with cluster deploy mode only:
--driver-cores NUM Cores for driver (Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
--principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to
the node running the Application Master via the Secure
Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.
转载自原文链接, 如需删除请联系管理员。
原文链接:【spark 大数据处理技术】 - “Hello world”,转载请注明来源!