词向量是自然语言的基础:
构建词向量最有名的方法就是word2vec,还有最近推出的Bert
下面先讲述一下word2vec,word2vec有两种模型CBOW和Skip-gram。CBOW是基于上下文预测当前的词,而Skip-gram模型与之相反,给定input word 预测上下文。两个模型通过训练,优化目标函数,获得隐藏层的权重,而隐藏层的权重才是我们真正需要的。

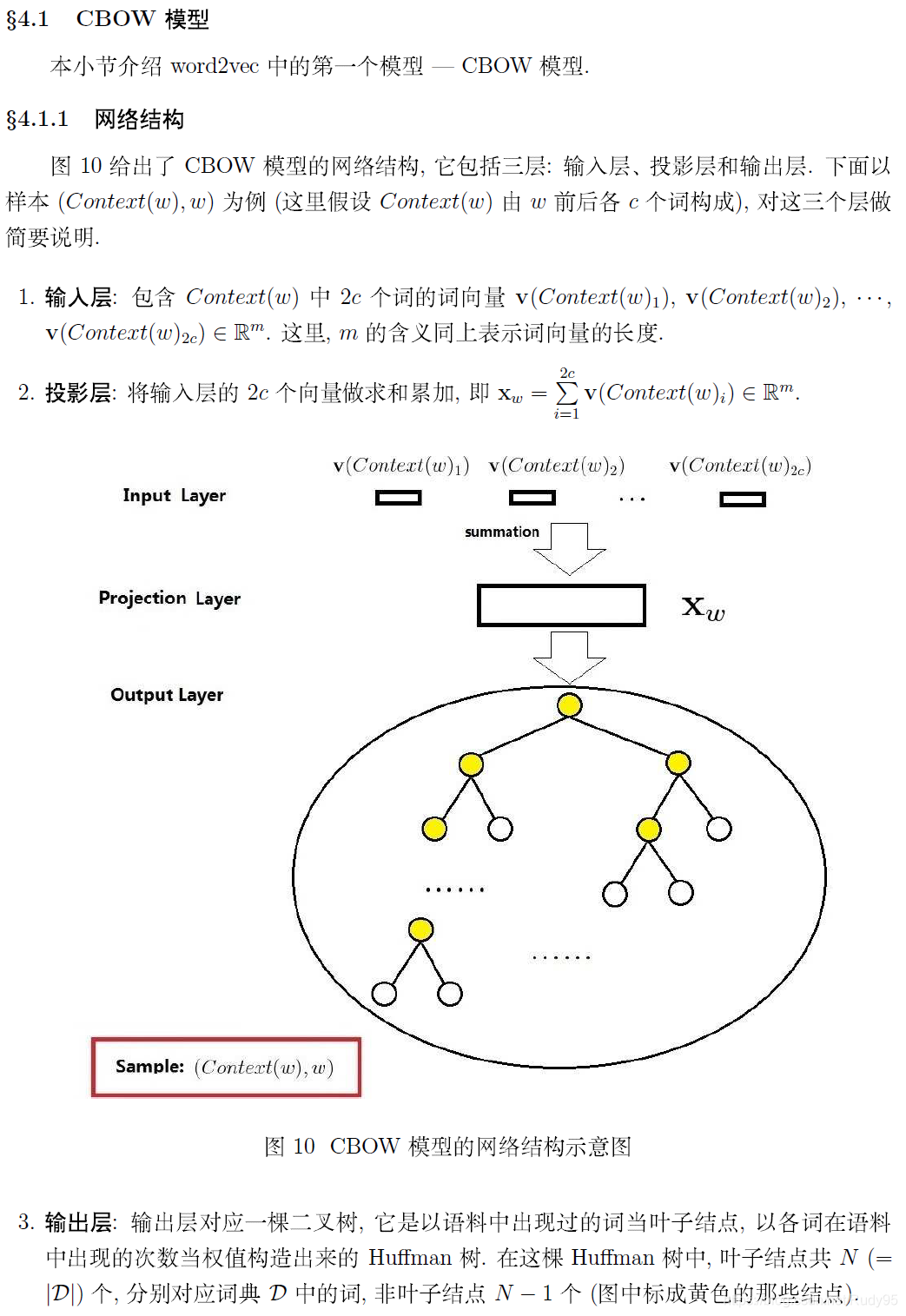

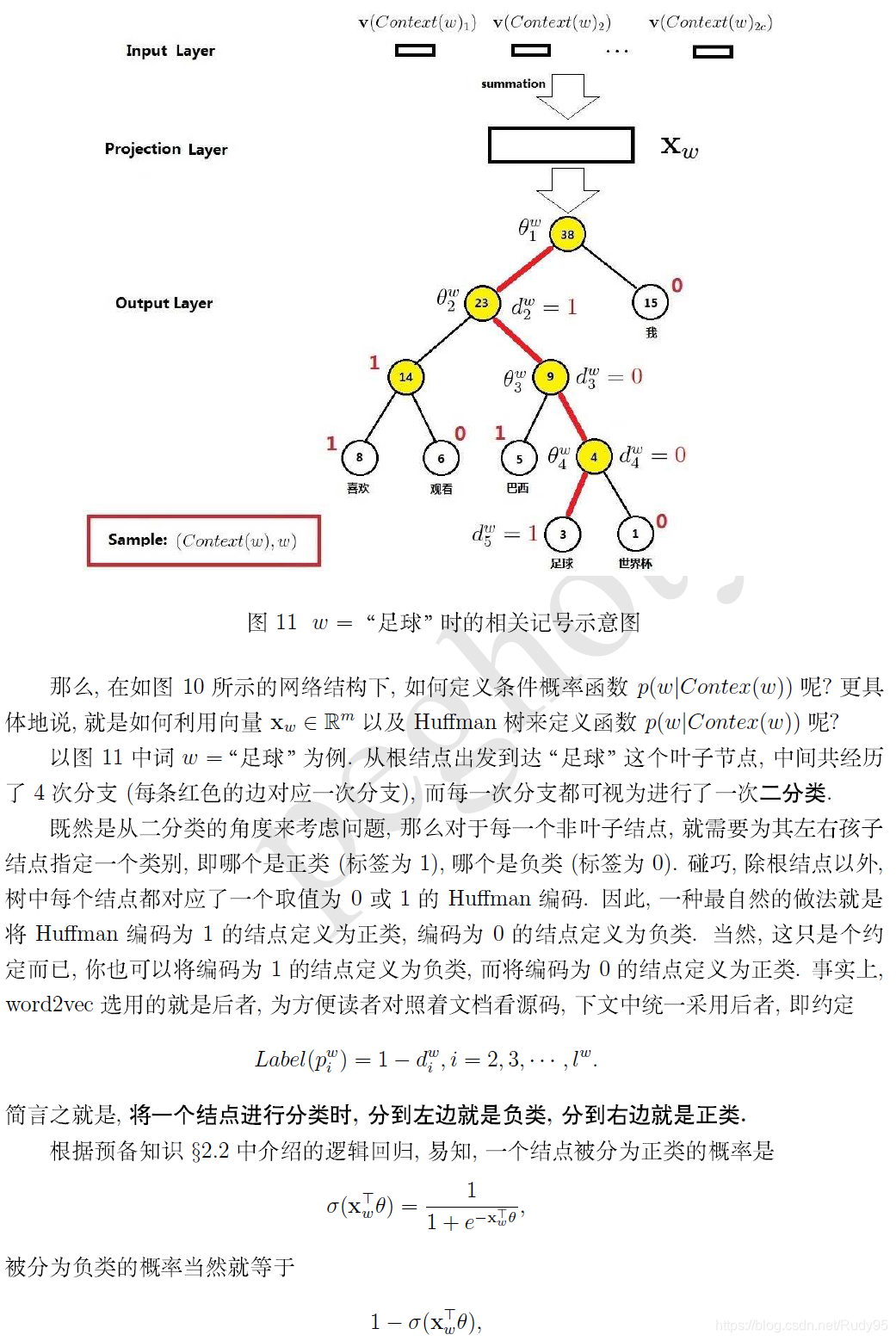



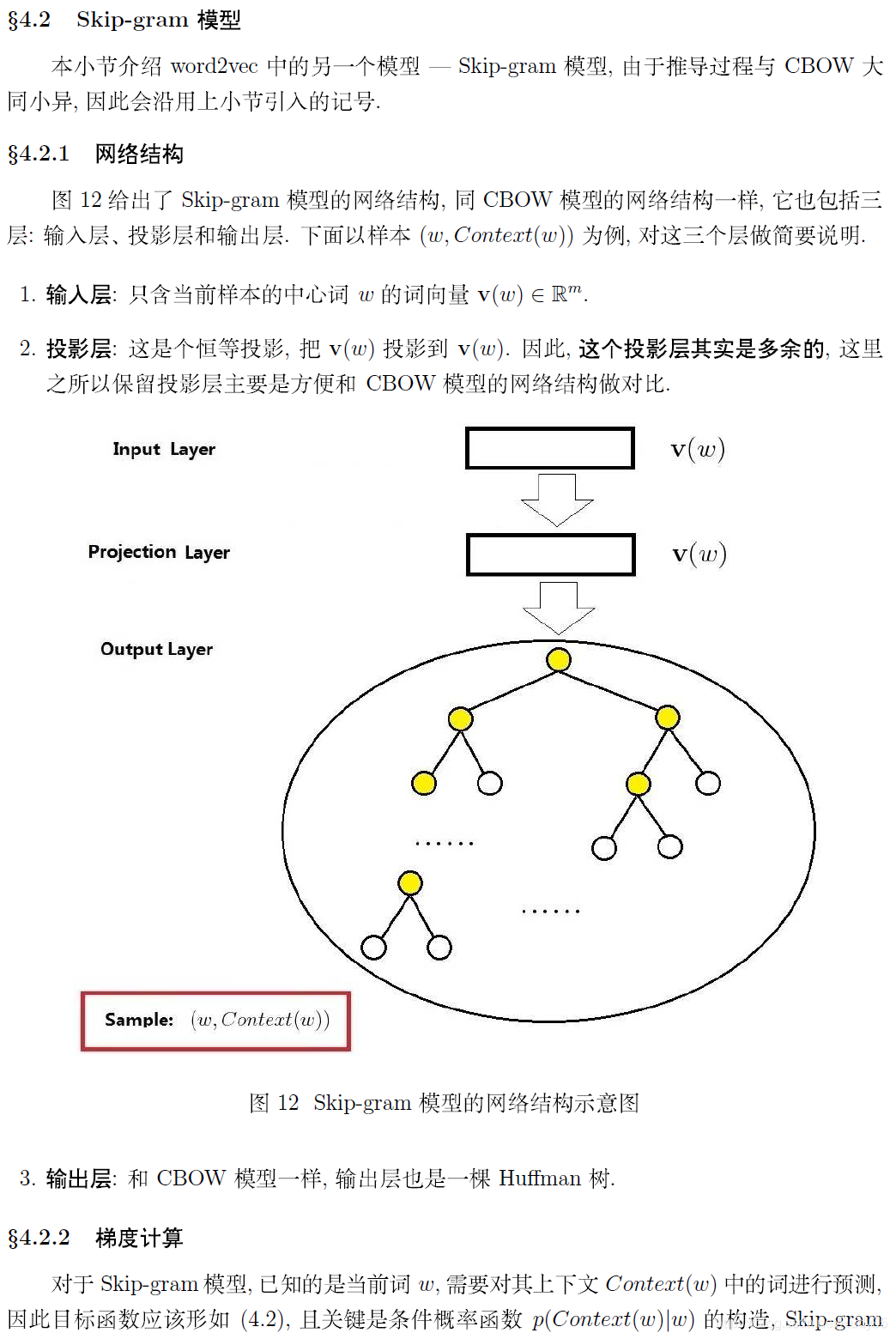


个人觉得为w2v涉及的知识点包含了逻辑回归,哈夫曼树,是一个很好的综合各方面知识的知识点,当然w2v的优化除了使用哈夫曼树优化方法还有负采样的方法。此外,w2v实际上有一个非常致命的缺点,是同一个词,无论在什么语境下,它的词向量是一样的。比如:
我喜欢吃苹果;我喜欢苹果手机。
在这里上下文中的,苹果的含义是不一样的,但是其词向量是一样的。后续有很多改进的方法,比如非常火的Bert。后续也会单独写文章来介绍。
再次推荐刘建平的博客讲的很好:https://www.cnblogs.com/pinard/p/7243513.html
作者: peghoty

出处: http://blog.csdn.net/itplus/article/details/37969979
欢迎转载/分享, 但请务必声明文章出处.
转载自原文链接, 如需删除请联系管理员。
原文链接:W2V原理(一),转载请注明来源!