1、多步自举


一步TD:TD(0),白色圈V函数,黑色Q函数,后继状态V函数更新当前状态V函数,采样,智能体和环境进行交互。根据状态采取一个动作,转为后继状态,环境给一个奖励--》采样一步得到后继状态
MC 采样到终止状态。MC只采样一步,之后的状态利用之前的值函数进行对当前值函数的估计
多步自举通过采样和自举的方法做一个权衡,TD(0)一步采样之后多步自举,现在多步采样多步自举
n步回报值:

几步为最优?
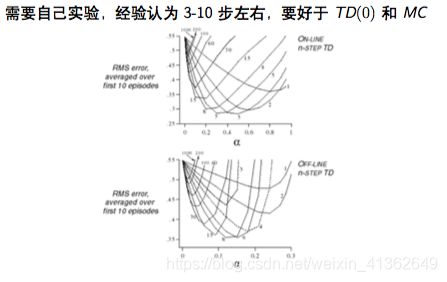

注意:为了计算n步回报值,需要维护R,S的存储空间,对于后继状态不足n个的,使用MC目标值
2、TD(lambda)
1)简介
将n步回报值平均

lambda回报值
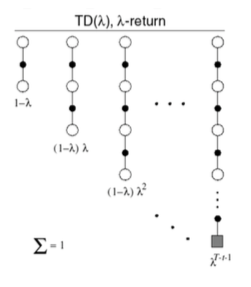

TD(lambda)加权函数
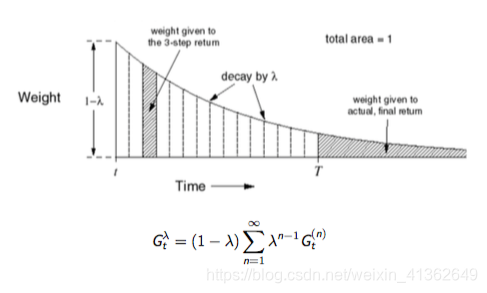
TD(lambda)的两种视角:
前向视角:主要是理解TD(lambda),上述是前向视角
后向视角:比较实用的算法
TD(lambda)的前向视角:
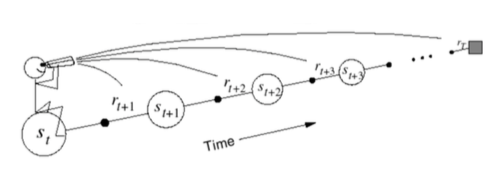

TD(lambda)的后向视角:前向视角提供理论,后向视角提供实用算法,通过后向视角,可以实现在线更新,每步更新,从不完整状态更新
2)资格迹
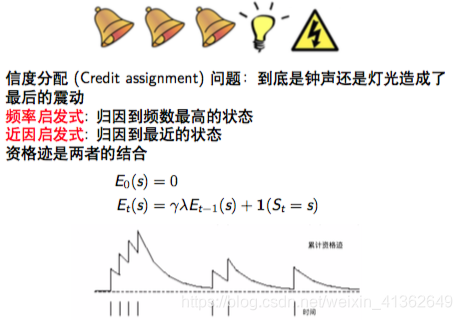
后向视角的TD(lambda):
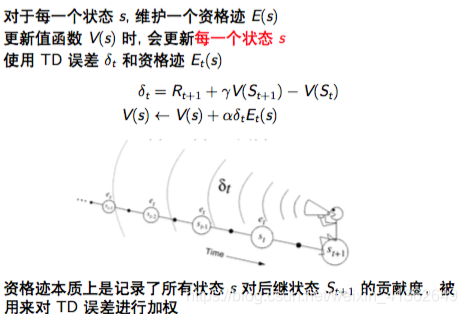
简单地来说,后向视角是秋后算账,看前面那个状态贡献比较大,之后对这个状态的资格迹加1,其它状态资格迹不断地衰减
3)TD(lambda)的两种视角的关系
TD(lambda)与TD(0)


TD(1)和MC:



TD(lambda)和TD(0)
当lambda=1时,信度分配会被延迟到终止状态,这里考虑到片断性任务,而且考虑离线更新,考虑一个片段整体的情况下,TD(1)总更新量等价于MC,在每一步更新上可能有差距
对s 的总更新量
![]()

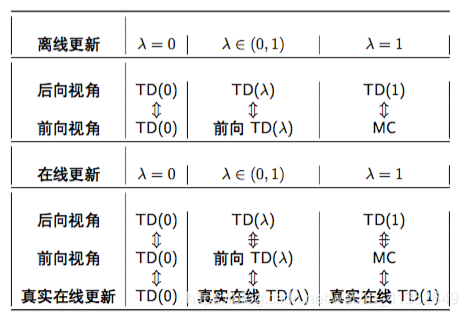
前向视角和后向视角的TD(lambda)

两种视角下的等价性:
离线更新:

在线更新:

小结:
3、TD(lambda)优化算法
n步Sarsa:

前向视角的Sarsa(lambda)算法


后向视角的Sarsa(lambda)

Sarsa(lambda)算法:

转载自原文链接, 如需删除请联系管理员。
原文链接:重温强化学习之无模型学习方法:TD(lambda),转载请注明来源!