彼岸图网站里有大量的高清图片素材和壁纸,并且可以免费下载,读者也可以根据自己需要爬取其他类型图片,方法是类似的,本文通过python爬虫批量下载网站里的高清美女图片,熟悉python写爬虫的基本方法:发送请求、获取响应、解析并提取数据、保存到本地。


1. 爬取一页的图片
正则匹配提取图片数据
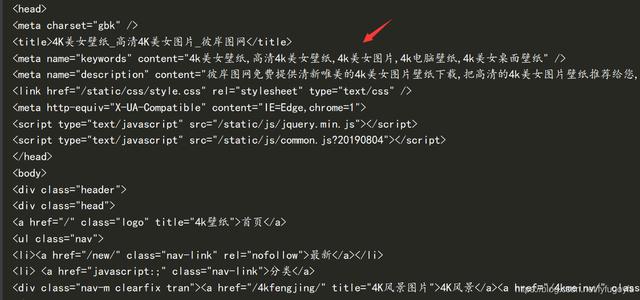
网页源代码部分截图如下:

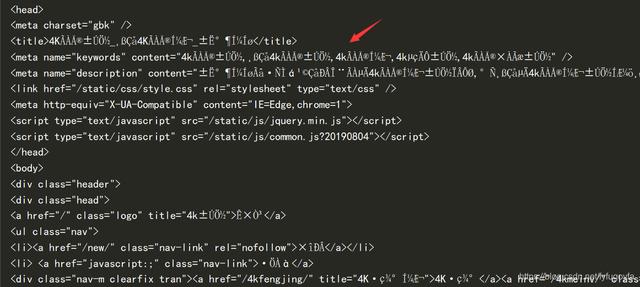
重新设置GBK编码解决了乱码问题
代码实现:
import requests
import re
# 设置保存路径
path = r'D:\test\picture_1\ '
# 目标url
url = "http://pic.netbian.com/4kmeinv/index.html"
# 伪装请求头 防止被反爬
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Referer": "http://pic.netbian.com/4kmeinv/index.html"
}
# 发送请求 获取响应
response = requests.get(url, headers=headers)
# 打印网页源代码来看 乱码 重新设置编码解决编码问题
# 内容正常显示 便于之后提取数据
response.encoding = 'GBK'
# 正则匹配提取想要的数据 得到图片链接和名称
img_info = re.findall('img src="(.*?)" alt="(.*?)" /', response.text)
for src, name in img_info:
img_url = 'http://pic.netbian.com' + src # 加上 'http://pic.netbian.com'才是真正的图片url
img_content = requests.get(img_url, headers=headers).content
img_name = name + '.jpg'
with open(path + img_name, 'wb') as f: # 图片保存到本地
print(f"正在为您下载图片:{img_name}")
f.write(img_content)
Xpath定位提取图片数据
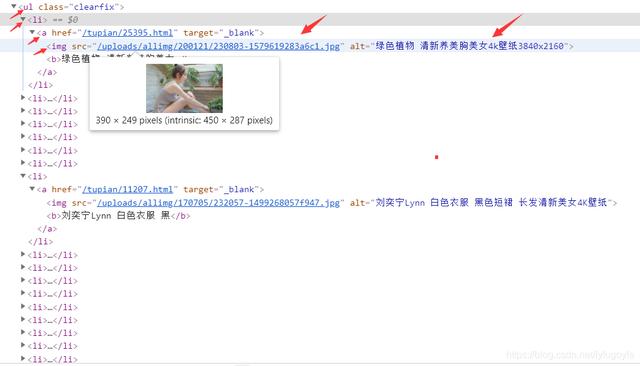
检查分析网页可以找到图片的链接和名称的Xpath路径,写出xpath表达式定位提取出想要的图片数据,但得到的每个图片的src前面需要都加上 ‘http://pic.netbian.com’ 得到的才是图片真正的url,可以用列表推导式一行代码实现。
代码实现:
import requests
from lxml import etree
# 设置保存路径
path = r'D:\test\picture_1\ '
# 目标url
url = "http://pic.netbian.com/4kmeinv/index.html"
# 伪装请求头 防止被反爬
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Referer": "http://pic.netbian.com/4kmeinv/index.html"
}
# 发送请求 获取响应
response = requests.get(url, headers=headers)
# 打印网页源代码来看 乱码 重新设置编码解决编码问题
# 内容正常显示 便于之后提取数据
response.encoding = 'GBK'
html = etree.HTML(response.text)
# xpath定位提取想要的数据 得到图片链接和名称
img_src = html.xpath('//ul[@class="clearfix"]/li/a/img/@src')
# 列表推导式 得到真正的图片url
img_src = ['http://pic.netbian.com' + x for x in img_src]
img_alt = html.xpath('//ul[@class="clearfix"]/li/a/img/@alt')
for src, name in zip(img_src, img_alt):
img_content = requests.get(src, headers=headers).content
img_name = name + '.jpg'
with open(path + img_name, 'wb') as f: # 图片保存到本地
print(f"正在为您下载图片:{img_name}")
f.write(img_content)

单线程版
import requests
from lxml import etree
import datetime
import time
# 设置保存路径
path = r'D:\test\picture_1\ '
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Referer": "http://pic.netbian.com/4kmeinv/index.html"
}
start = datetime.datetime.now()
def get_img(urls):
for url in urls:
# 发送请求 获取响应
response = requests.get(url, headers=headers)
# 打印网页源代码来看 乱码 重新设置编码解决编码问题
# 内容正常显示 便于之后提取数据
response.encoding = 'GBK'
html = etree.HTML(response.text)
# xpath定位提取想要的数据 得到图片链接和名称
img_src = html.xpath('//ul[@class="clearfix"]/li/a/img/@src')
# 列表推导式 得到真正的图片url
img_src = ['http://pic.netbian.com' + x for x in img_src]
img_alt = html.xpath('//ul[@class="clearfix"]/li/a/img/@alt')
for src, name in zip(img_src, img_alt):
img_content = requests.get(src, headers=headers).content
img_name = name + '.jpg'
with open(path + img_name, 'wb') as f: # 图片保存到本地
# print(f"正在为您下载图片:{img_name}")
f.write(img_content)
time.sleep(1)
def main():
# 要请求的url列表
url_list = ['http://pic.netbian.com/4kmeinv/index.html'] + [f'http://pic.netbian.com/4kmeinv/index_{i}.html' for i in range(2, 11)]
get_img(url_list)
delta = (datetime.datetime.now() - start).total_seconds()
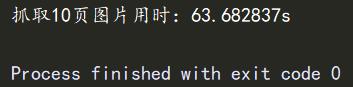
print(f"抓取10页图片用时:{delta}s")
if __name__ == '__main__':
main()
程序运行成功,抓取了10页的图片,共210张,用时63.682837s。
多线程版
import requests
from lxml import etree
import datetime
import time
import random
from concurrent.futures import ThreadPoolExecutor
# 设置保存路径
path = r'D:\test\picture_1\ '
user_agent = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
start = datetime.datetime.now()
def get_img(url):
headers = {
"User-Agent": random.choice(user_agent),
"Referer": "http://pic.netbian.com/4kmeinv/index.html"
}
# 发送请求 获取响应
response = requests.get(url, headers=headers)
# 打印网页源代码来看 乱码 重新设置编码解决编码问题
# 内容正常显示 便于之后提取数据
response.encoding = 'GBK'
html = etree.HTML(response.text)
# xpath定位提取想要的数据 得到图片链接和名称
img_src = html.xpath('//ul[@class="clearfix"]/li/a/img/@src')
# 列表推导式 得到真正的图片url
img_src = ['http://pic.netbian.com' + x for x in img_src]
img_alt = html.xpath('//ul[@class="clearfix"]/li/a/img/@alt')
for src, name in zip(img_src, img_alt):
img_content = requests.get(src, headers=headers).content
img_name = name + '.jpg'
with open(path + img_name, 'wb') as f: # 图片保存到本地
# print(f"正在为您下载图片:{img_name}")
f.write(img_content)
time.sleep(random.randint(1, 2))
def main():
# 要请求的url列表
url_list = ['http://pic.netbian.com/4kmeinv/index.html'] + [f'http://pic.netbian.com/4kmeinv/index_{i}.html' for i in range(2, 51)]
with ThreadPoolExecutor(max_workers=6) as executor:
executor.map(get_img, url_list)
delta = (datetime.datetime.now() - start).total_seconds()
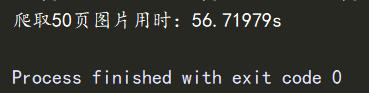
print(f"爬取50页图片用时:{delta}s")
if __name__ == '__main__':
main()
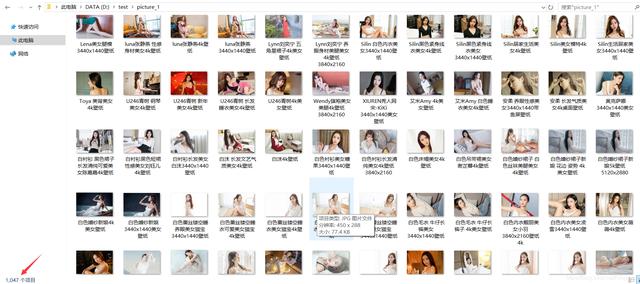
程序运行成功,抓取了50页图片,共1047张,用时56.71979s。开多线程大大提高的爬取数据的效率。
最终成果如下:
3. 其他说明
- 本文仅用于python爬虫知识交流,勿作其他用途,违者后果自负。
- 不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
还是很简单的,基本都能一看就会把?
此文转载于:叶庭云
著作权归作者所有,如有侵权联系小编删除!
转载自原文链接, 如需删除请联系管理员。
原文链接:Python爬虫实战 批量下载高清美女图片!让你们开开眼!,转载请注明来源!