性能数据不稳定因素
Ceph 作为软件定义存储的代表之一,最近几年其发展势头很猛,也出现了不少公司在测试和生产系统中使用 Ceph 的案例,尽管与此同时许多人对它的抱怨也一直存在。特别是进行性能测试。我们在进行性能测试时经常会发现性能数据不稳定的现象,尤其是服务器使用的是带有cache的raid卡。比如在使用30个7.2K SATA盘搭建的ONEStor ceph集群 (使用HP Smart Array P840raid卡,cache缓存大小4G)测试4k randwrite时,单个客户端iops可以达到4k以上,低的时候单个客户端iops基本在1k左右,为此,我们就去寻找导致这种现象出现的主要原因。
1、 当性能数据达不到预期,而且数据跳到比较大的时候。首先要考虑的就是raid卡和硬盘是否有故障。一般服务器都有查看自己硬件状态的页面,首先要确定硬件都是完好的,我们才可以继续玩下去。另外,我们可以用ceph osd perf查看集群中是否有某些硬盘比较不给力。通过osd perf可以提供磁盘latency的状况,同时在运维过程中也可以作为监控的一个重要指标。
正常性能测试时使用osd perf查看的结果应该不会有差别:
如果发现某个硬盘或者某个节点下的所有硬盘延时很高,就需要考虑将该OSD剔除出集群。
2、 排除了硬件的故障以后,我们再来看看其他的影响。测试过程中发现在使用fio 4k randwrite进行性能测试时,使用iostat 查看硬盘使用情况,却时不时会有大量读存在,而且出现读的时候硬盘的使用率基本到100%。如果你的集群刚做完数据恢复,或者在虚拟文件系统中的/proc/sys/vm/drop_caches写入2或3来清除缓存,下一次进行randwrite性能测试时该现象是必现的。比如用iostat看到的:


那问题就好找了,原因就基本锁定在了drop_caches时清除的inodes上,首先来了解一下inodes。
我们知道使用free 命令可以查看到内存的使用情况,包括了buffer和cache。 Linux内核会将它最近访问过的文件页面缓存在内存中一段时间,这个文件缓存被称为pagecache。
inode是linux/unix操作系统中的一种数据结构,包含了各文件相关的一些重要信息。在创建文件系统时,就会同时创建大量的inode。一般inode表会占用文件系统磁盘空间的1%。
理解inode,要从文件储存说起:
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。,为了加快对索引节点的索引,linux又引入了inode缓冲区。就是把从硬盘读取到的inodes信息保存在缓存中。
我们可以用slabtop工具查看缓存中inodes的使用情况。内核的模块在分配资源的时候,为了提高效率和资源的利用率,都是透过slab来分配的。我们可以使用slabtop命令查看slab内存分配机制。这个应用能够显示缓存分配器是如何管理Linux内核中缓存的不同类型的对象。这个命令类似于top命令,区别是它的重点是实时显示内核slab缓存信息,例如:
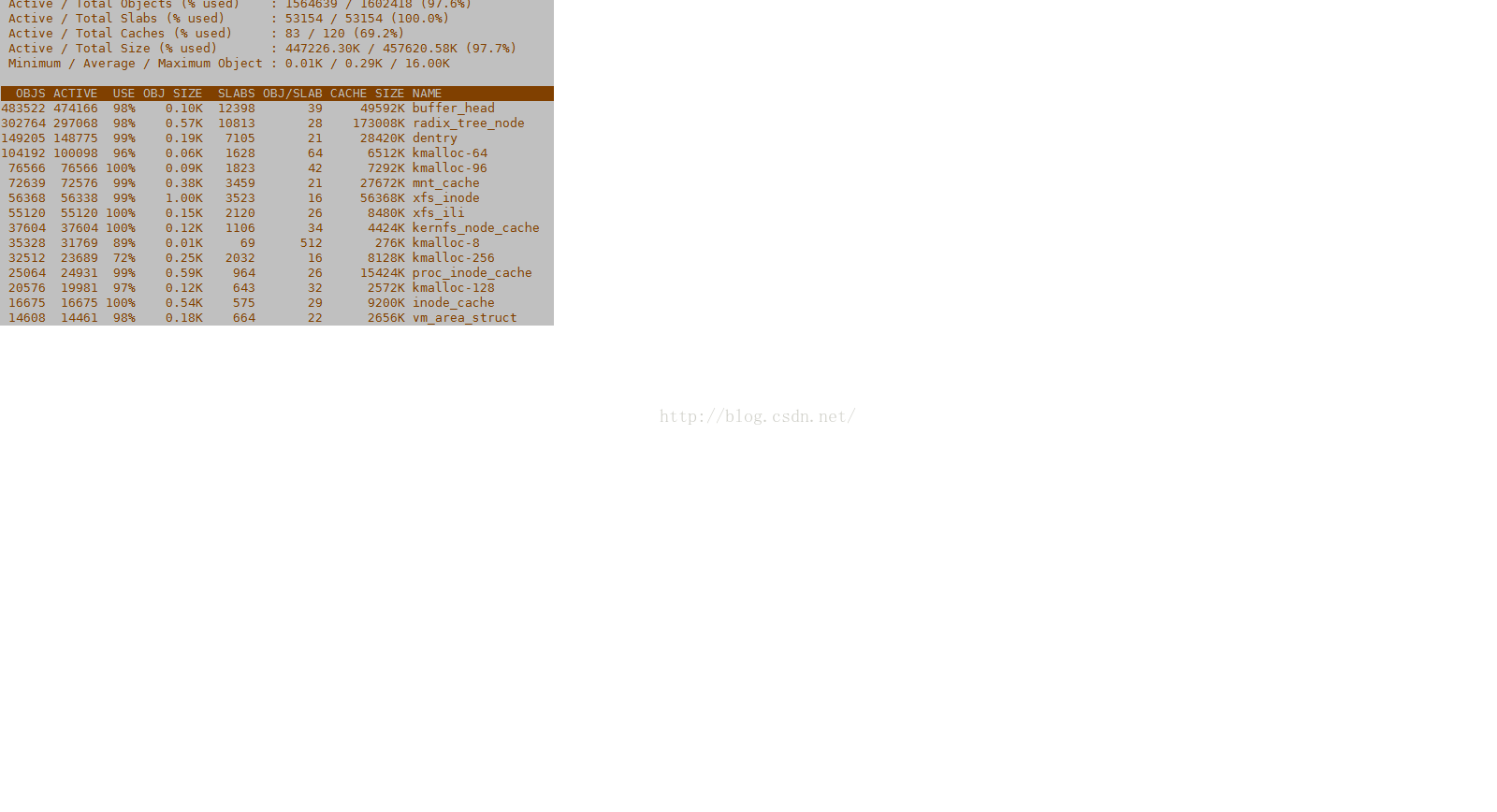
如果看到的xfs_inode和radix_tree_node使用的太多或者刚被清除,这时候就要特别注意inodes的影响了。
如何判断是否有inodes的影响?在进行性能测试过程中尽量使用iostat 查看硬盘的使用情况。如果在进行随机写性能测试时,随机写性能比较低。可以使用iostat –x 1 查看硬盘信息,如果硬盘的util很高,同时又有大量的读存在,这时候基本说明系统正在从硬盘读取大量的inodes,硬盘资源很大部分被读inodes给占用了。
当然,触发它进行读取inodes的原因有很多:
1、使用了drop_caches的方式释放了inodes和dentry。就是在/proc/sys/vm/drop_caches里写入2或者3 都会drop inodes和dentry。
2、有过其他大量的读写操作,比如增删过硬盘、主机等只要有过大量数据恢复,数据恢复之后再进行性能测试就会触发需要重新读inodes。这时性能数据会很长时间维持在很低的状态,因为从缓存读inodes的命中率很低,甚至连续写几个小时或更长的时候都会性能很低。
3、内存使用太多。如果slab cache占用过多属于正常问题,并且当内存到达系统最低空闲内存限制的话,会自动触发kswapd进程来回收内存。
从测试的角度来看,目前性能测试数据乎高乎低基本原因就是读取inodes造成 的。(不排除还有其他原因),要让测试随机写时,尽量高的提升从缓存读取inodes的命中率,目前有如下方法:
1、 fio测试时尽量使用小块进行测试,目前来看如果使用100G的块,就不太受inodes的影响,性能数据比较高
2、 尽量不使用做过异常测试的集群进行性能测试
3、 随机写性能测试时使用iostat查看硬盘状态,如果此时有大量读,尽量让测试时间长一点 ,多写一会后停止fio后再重新测试。直到基本不出现读时再记录测试结果
4、 在/etc/sysctl.conf内核参数文件中配置
vm.vfs_cache_pressure = 50
该配置表示内核回收用于directory和inode cache内存的倾向;缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比;降低该值低于100,将导致内核倾向于保留directory和inode cache;增加该值超过100,将导致内核倾向于回收directory和inode cache。
5、 目前个人认为在 ceph代码和linux系统配置上这一块应该还存在很大的优化空间,需要具体分析其它提升方法
转载自原文链接, 如需删除请联系管理员。
原文链接:分布式存储ceph系统性能不稳定因素,转载请注明来源!